训练概览与功能
概览
训练高级深度学习模型充满挑战。除了模型设计,模型科学家还需要设置最先进的训练技术,如分布式训练、混合精度、梯度累积和检查点。然而,科学家可能仍然无法达到所需的系统性能和收敛速度。大型模型尺寸更具挑战性:大型模型很容易因纯数据并行而内存不足,并且难以使用模型并行。DeepSpeed 解决了这些挑战,以加速模型开发和训练。
轻松实现分布式、有效和高效训练
DeepSpeed API 是 PyTorch 的一个轻量级封装。这意味着您可以使用 PyTorch 中所有您喜欢的功能,而无需学习一个新平台。此外,DeepSpeed 管理所有样板式的最先进训练技术,如分布式训练、混合精度、梯度累积和检查点,以便您可以专注于模型开发。最重要的是,您只需对 PyTorch 模型进行几行代码更改,即可利用 DeepSpeed 独特的效率和效益优势来提升速度和规模。
速度
DeepSpeed 通过计算/通信/内存/IO 上的效率优化以及高级超参数调优和优化器上的效益优化相结合,实现了高性能和快速收敛。例如:
-
DeepSpeed 使用 1024 块 V100 GPU(64 台 DGX-2 盒子)在 44 分钟内将 BERT-large 训练到相同性能水平,并使用 256 块 GPU(16 台 DGX-2 盒子)在 2.4 小时内完成。
BERT-large 训练时间
设备 来源 训练时间 1024 块 V100 GPU DeepSpeed 44 分钟 256 块 V100 GPU DeepSpeed 2.4 小时 64 块 V100 GPU DeepSpeed 8.68 小时 16 块 V100 GPU DeepSpeed 33.22 小时 BERT 代码和教程即将发布。
-
DeepSpeed 在 Azure GPU 上训练 GPT2(15 亿参数),比最先进的 NVIDIA Megatron 快 3.75 倍。
阅读更多:GPT 教程
内存效率
DeepSpeed 提供内存高效的数据并行性,并允许在没有模型并行性的情况下训练模型。例如,DeepSpeed 可以在单个 GPU 上训练高达 130 亿参数的模型。相比之下,现有框架(例如 PyTorch 的分布式数据并行)在处理 14 亿参数的模型时就会内存不足。
DeepSpeed 通过一种名为零冗余优化器 (ZeRO) 的新颖解决方案,减少了训练内存占用。与将内存状态复制到数据并行进程中的基本数据并行不同,ZeRO 对模型状态和梯度进行分区以显著节省内存。此外,它还减少了激活内存和碎片化内存。当前实现 (ZeRO-2) 相对于最先进技术,内存减少了高达 8 倍。您可以在我们的论文以及与 ZeRO-1 和 ZeRO-2 相关的博客文章中了解更多关于 ZeRO 的信息。
凭借这种令人印象深刻的内存削减,DeepSpeed 的早期采用者已经制作了一个拥有超过 170 亿参数的语言模型 (LM),名为 Turing-NLG,在 LM 类别中树立了新的 SOTA。
对于 GPU 资源有限的模型科学家,ZeRO-Offload 利用 CPU 和 GPU 内存来训练大型模型。使用单个 GPU 的机器,我们的用户可以运行高达 130 亿参数的模型而不会内存不足,比现有方法大 10 倍,同时获得具有竞争力的吞吐量。此功能使数十亿参数模型的训练大众化,为许多深度学习从业者探索更大更好的模型打开了窗口。
可扩展性
DeepSpeed 支持高效的数据并行、模型并行、流水线并行及其组合,我们称之为 3D 并行。
- DeepSpeed 的 3D 并行提供了运行万亿参数模型的系统支持,更多信息请阅读我们的新闻稿和教程。
-
DeepSpeed 可以更高效地运行大型模型,对于从 15 亿到千亿参数的各种尺寸模型,速度可提升高达 10 倍。更具体地说,ZeRO 驱动的数据并行是互补的,并且可以与不同类型的模型并行相结合。它允许 DeepSpeed 使用较低程度的模型并行和更大的批量大小来适应模型,与单独使用模型并行相比,提供了显著的性能提升。
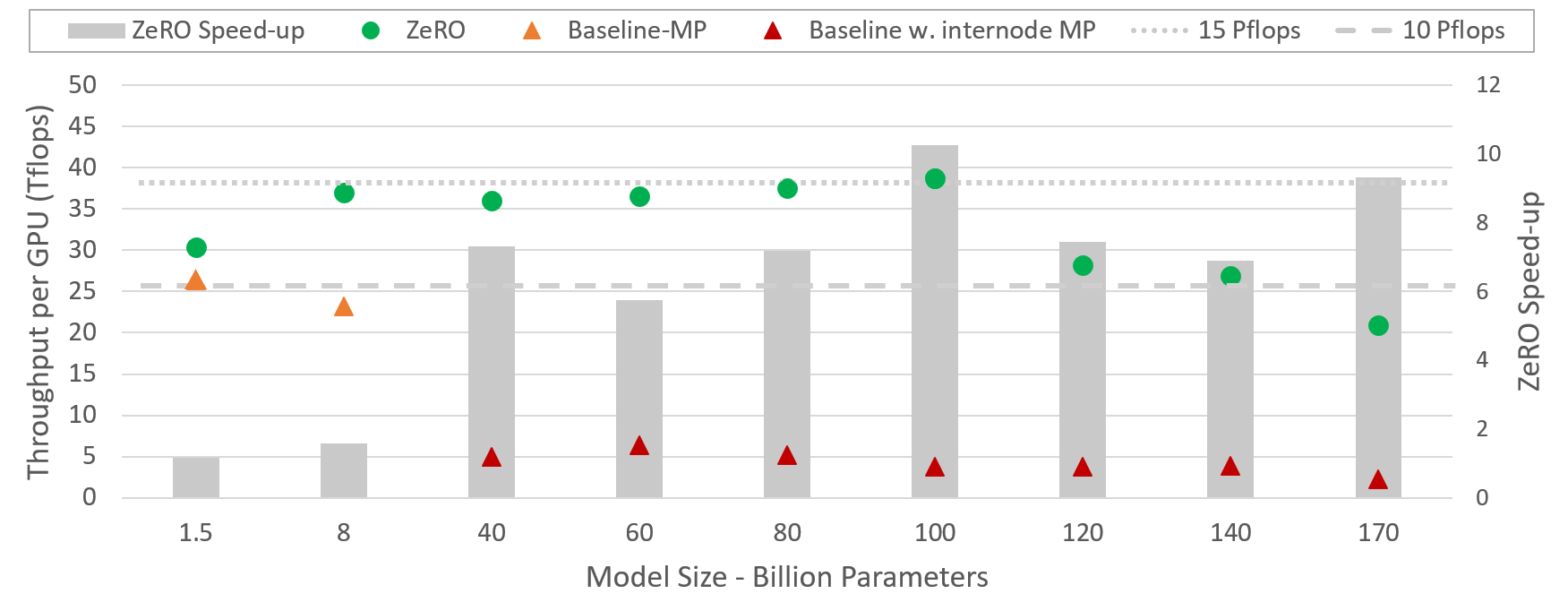
该图展示了 DeepSpeed(将 ZeRO 驱动的数据并行与 NVIDIA Megatron-LM 的模型并行结合)相对于单独使用 Megatron-LM 的系统吞吐量改进。
通信效率
DeepSpeed 的流水线并行减少了分布式训练期间的通信量,这使得用户能够在网络带宽有限的集群上以 2-7 倍的速度训练数十亿参数模型。 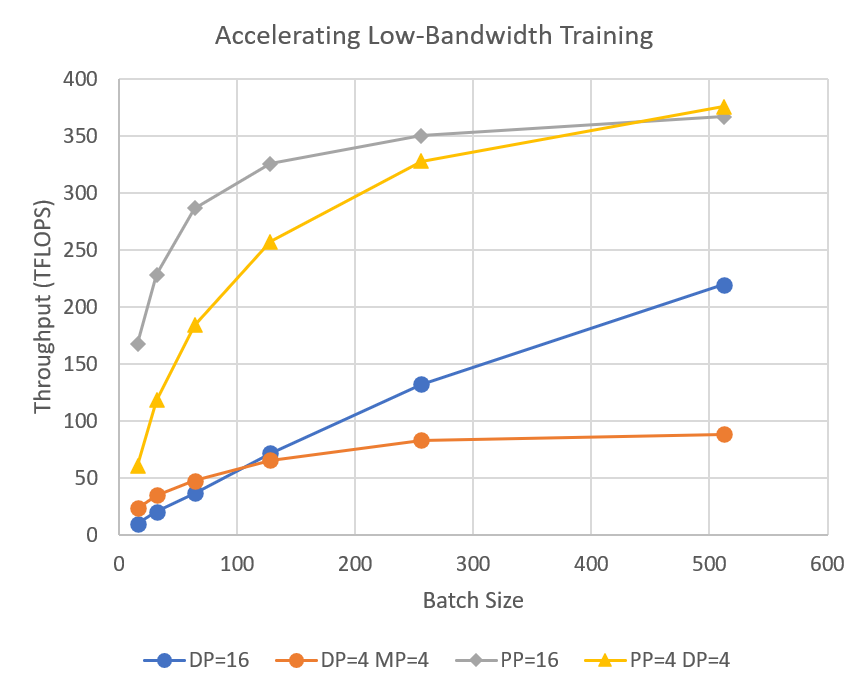
1-bit Adam、0/1 Adam 和 1-bit LAMB 可将通信量减少高达 26 倍,同时实现与 Adam 相似的收敛效率,从而能够扩展到不同类型的 GPU 集群和网络。1-bit Adam 博客文章、1-bit Adam 教程、0/1 Adam 教程、1-bit LAMB 教程。
数据效率
DeepSpeed 数据效率库通过课程学习提供高效的数据采样,并通过随机分层令牌丢弃提供高效的数据路由。该组合解决方案在 GPT-3/BERT 预训练和 GPT/ViT 微调期间可节省高达 2 倍的数据和 2 倍的时间,或在相同数据/时间下进一步提高模型质量。更多信息请参阅教程。
支持长序列长度
DeepSpeed 提供稀疏注意力内核——这是一项支持长序列模型输入(无论是文本、图像还是声音)的关键技术。与经典密集 Transformers 相比,它支持长一个数量级的输入序列,并以可比较的准确性实现高达 6 倍的执行速度。它还以 1.5-3 倍的执行速度超越了最先进的稀疏实现。此外,我们的稀疏内核支持高效执行灵活的稀疏格式,并使用户能够在自定义稀疏结构上进行创新。在此处阅读更多信息。
快速收敛以提高效率
DeepSpeed 支持高级超参数调优和大型批量优化器,例如 LAMB。这些可以提高模型训练的有效性,并减少收敛到所需精度所需的样本数量。
阅读更多:调优教程。
良好的可用性
只需几行代码更改,即可使 PyTorch 模型使用 DeepSpeed 和 ZeRO。与当前的模型并行库相比,DeepSpeed 不需要代码重新设计或模型重构。它也不对模型维度(如注意力头数、隐藏大小等)、批量大小或任何其他训练参数施加限制。对于高达 130 亿参数的模型,您可以方便地使用 ZeRO 驱动的数据并行,而无需模型并行,相比之下,标准数据并行对于超过 14 亿参数的模型将内存不足。此外,DeepSpeed 方便地支持 ZeRO 驱动的数据并行与自定义模型并行(如 NVIDIA Megatron-LM 的张量切片)的灵活组合。
功能
下面我们提供一个简要的功能列表,有关描述和用法,请参阅我们的详细功能概览。
- 混合精度分布式训练
- 16 位混合精度
- 单 GPU/多 GPU/多节点
- 模型并行
- 支持自定义模型并行
- 与 Megatron-LM 集成
- 流水线并行
- 3D 并行
- 零冗余优化器
- 优化器状态和梯度分区
- 激活分区
- 常量缓冲区优化
- 连续内存优化
- ZeRO-Offload
- 利用 CPU/GPU 内存进行模型训练
- 在单个 GPU 上支持 10B 模型训练
- 超高速密集 transformer 内核
- 稀疏注意力
- 内存和计算高效的稀疏内核
- 支持比密集模型长 10 倍的序列
- 灵活支持不同的稀疏结构
- 1-bit Adam, 0/1 Adam 和 1-bit LAMB
- 自定义通信集合
- 通信量节省高达 26 倍
- 额外的内存和带宽优化
- 智能梯度累积
- 通信/计算重叠
- 训练功能
- 简化的训练 API
- 梯度裁剪
- 混合精度自动损失缩放
- 训练优化器
- 融合 Adam 优化器和任意
torch.optim.Optimizer - 内存带宽优化的 FP16 优化器
- 使用 LAMB 优化器进行大批量训练
- 使用 ZeRO 优化器进行内存高效训练
- CPU-Adam
- 融合 Adam 优化器和任意
- 训练无关的检查点
- 高级参数搜索
- 学习率范围测试
- 1Cycle 学习率调度
- 简化的数据加载器
- 数据效率
- 通过课程学习实现高效数据采样,通过随机分层令牌丢弃实现高效数据路由
- 在 GPT-3/BERT 预训练和 GPT/ViT 微调期间,数据和时间节省高达 2 倍
- 或在相同数据/时间下进一步提高模型质量
- 课程学习
- 基于课程学习的数据管线,在训练早期提供更简单或更易懂的示例
- GPT-2 预训练更稳定,速度提高 3.3 倍,批量大小/学习率提高 8 倍/4 倍,同时保持令牌级收敛速度
- 与许多其他 DeepSpeed 功能互补
- 请注意,上述数据效率库提供了更通用的课程学习支持。此遗留课程学习功能仍然受支持,但我们建议使用数据效率库。
- 渐进式层丢弃
- 高效且稳健的压缩训练
- 预训练收敛速度提升高达 2.5 倍
- 性能分析和调试
- 专家混合 (MoE)
标题:“功能概览” 布局:single 永久链接:/features/ 目录:true 目录标签:“内容” —
混合精度分布式训练
混合精度训练
通过在 deepspeed_config JSON 中启用 16 位 (FP16) 训练。
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"consecutive_hysteresis": false,
"min_loss_scale": 1
}
单 GPU、多 GPU 和多节点训练
通过使用主机文件指定资源,轻松地在单 GPU、单节点多 GPU 或多节点多 GPU 执行之间切换。
deepspeed --hostfile=<hostfile> \
<client_entry.py> <client args> \
--deepspeed --deepspeed_config ds_config.json
脚本 <client_entry.py> 将在 <hostfile> 中指定的资源上执行。
流水线并行
DeepSpeed 提供 流水线并行 以实现内存和通信高效训练。DeepSpeed 支持数据、模型和流水线并行的混合组合,并已通过 3D 并行扩展到超过一万亿参数。流水线并行还可以提高通信效率,并在低带宽集群上将训练速度提高了 7 倍。
模型并行
支持自定义模型并行
DeepSpeed 支持所有形式的模型并行,包括基于张量切片的方法,例如 Megatron-LM。它只需模型并行框架提供一个实现了一些簿记功能的模型并行单元 (mpu)
mpu.get_model_parallel_rank()
mpu.get_model_parallel_group()
mpu.get_model_parallel_world_size()
mpu.get_data_parallel_rank()
mpu.get_data_parallel_group()
mpu.get_data_parallel_world_size()
与 Megatron-LM 集成
DeepSpeed 与 Megatron 完全兼容。有关详细信息,请参阅 Megatron-LM 教程。
零冗余优化器
零冗余优化器(ZeRO)是 DeepSpeed 的核心,它使得大规模模型训练成为可能,这是仅靠模型并行无法实现的。启用 ZeRO 后,可以在不进行任何模型并行的情况下训练超过 130 亿参数的模型,并可以在当前一代硬件上通过模型并行训练高达 2000 亿参数的模型。
有关更多详细信息,请参阅 ZeRO 论文以及与 DeepSpeed 集成的 GPT 教程。
优化器状态和梯度分区
ZeRO 中的优化器状态和梯度分区将模型状态(优化器状态、梯度和参数)的内存消耗降低了 8 倍,相比标准数据并行,通过将这些状态在数据并行进程之间进行分区而不是复制。
激活分区
激活分区是 ZeRO 中一项内存优化,可以减少模型并行训练 (MP) 期间激活所消耗的内存。在 MP 中,某些激活可能被所有 MP 进程需要,导致激活在 MP GPU 之间复制。激活分区在正向传播中用于计算后,将这些激活以分区状态存储。在反向传播中再次需要这些激活之前,它们会被完全收集。通过以分区状态存储激活,DeepSpeed 中的 ZeRO 可以按 MP 程度的比例减少激活内存占用。
常量缓冲区优化 (CBO)
CBO 在限制内存使用为恒定大小的同时,实现了高网络和内存吞吐量。对于内存和网络受限的操作,如归一化或 allreduce 集合,其性能取决于操作数的尺寸。简单地将所有操作数融合成一个大型操作数可以实现出色的吞吐量,但会以不必要的内存开销为代价。DeepSpeed 中的 CBO 将较小的操作数融合成一个预定义大小的缓冲区,该缓冲区足够大以实现出色性能,而没有不必要的内存开销。
连续内存优化 (CMO)
CMO 减少训练期间的内存碎片化,防止因缺少连续内存而导致的内存不足错误。内存碎片化是短生命周期和长生命周期内存对象交错的结果。在正向传播期间,激活检查点是长生命周期的,但重新计算的激活是短生命周期的。同样,在反向计算期间,激活梯度是短生命周期的,而参数梯度是长生命周期的。CMO 将激活检查点和参数梯度传输到连续缓冲区,从而防止内存碎片化。
ZeRO-Offload
ZeRO-Offload 通过利用 GPU 及其主机 CPU 上的计算和内存资源,突破了使用最少 GPU 资源高效训练的最大模型尺寸的限制。它允许在单个 NVIDIA V100 GPU 上训练高达 130 亿参数的模型,比最先进的技术大 10 倍,同时保持每 GPU 超过 30 teraflops 的高训练吞吐量。
有关更多详细信息,请参阅 ZeRO-Offload 发布博客以及与 DeepSpeed 集成的教程。
额外的内存和带宽优化
智能梯度累积
梯度累积允许在内存有限的情况下运行更大的批量大小,方法是将一个有效批量分解为几个顺序的微批量,并对这些微批量的参数梯度进行平均。此外,不是将每个微批量的梯度在所有 GPU 上进行全局平均,而是在序列的每一步中局部平均梯度,并在序列结束时进行一次 allreduce 以生成所有 GPU 上有效批量的平均梯度。这种策略显著减少了与每个微批量全局平均方法相关的通信量,特别是当每个有效批量的微批量数量很大时。
通信重叠
在反向传播过程中,DeepSpeed 可以将平均已计算出的参数梯度所需的通信与正在进行的梯度计算重叠。这种计算-通信重叠使 DeepSpeed 即使在适中的批量大小下也能实现更高的吞吐量。
训练功能
简化的训练 API
DeepSpeed 核心 API 仅包含少量方法
- 初始化:
initialize - 训练:
backward和step - 参数解析:
add_config_arguments - 检查点:
load_checkpoint和store_checkpoint
DeepSpeed 通过使用这些 API 以及一个 deepspeed_config JSON 文件来启用和禁用功能,支持本文档中描述的大多数功能。有关更多详细信息,请参阅核心 API 文档。
激活检查点 API
DeepSpeed 的激活检查点 API 支持激活检查点分区、CPU 检查点和连续内存优化,同时还允许分层分析。有关更多详细信息,请参阅核心 API 文档。
梯度裁剪
{
"gradient_clipping": 1.0
}
DeepSpeed 根据用户指定的最大梯度范数在内部处理梯度裁剪。有关更多详细信息,请参阅核心 API 文档。
混合精度自动损失缩放
DeepSpeed 内部处理混合精度训练的损失缩放。损失缩放的参数可以在 deepspeed_config JSON 文件中指定。有关更多详细信息,请参阅核心 API 文档。
训练优化器
1-bit Adam、0/1 Adam 和 1-bit LAMB 优化器,通信量减少高达 26 倍
DeepSpeed 拥有三个通信高效优化器,分别命名为 1-bit Adam、0/1 Adam 和 1-bit LAMB。它们提供与 Adam/LAMB 相同的收敛性,通信量减少高达 26 倍,从而在带宽受限的集群上,BERT-Large 预训练吞吐量提高高达 6.6 倍,SQuAD 微调吞吐量提高高达 2.7 倍。有关用法和性能的更多详细信息,请参阅 1-bit Adam 教程、1-bit Adam 博客文章、0/1 Adam 教程 和 1-bit LAMB 教程。有关技术细节,请参阅 1-bit Adam 论文、0/1 Adam 论文 和 1-bit LAMB 论文。
融合 Adam 优化器和任意 torch.optim.Optimizer
使用 DeepSpeed,用户可以选择使用 NVIDIA 的高性能 ADAM 实现,或任何扩展 torch 的 torch.optim.Optimizer 类的训练优化器。
CPU-Adam:Adam 的高性能向量化实现
我们引入了 CPU 上 Adam 优化器的高效实现,将参数更新性能提高了近一个数量级。我们使用 Intel-x86 架构上的 AVX SIMD 指令来实现 CPU-Adam。我们支持 AVX-512 和 AVX-2 指令集。DeepSpeed 默认使用 AVX-2,在安装 DeepSpeed 时,可以通过将构建标志 DS_BUILD_AVX512 设置为 1 来切换到 AVX-512。使用 AVX-512,我们观察到在模型大小在 1 到 100 亿参数之间时,相对于 torch-adam 实现了 5.1 倍到 6.5 倍的加速。
内存带宽优化的 FP16 优化器
混合精度训练由 DeepSpeed FP16 优化器处理。此优化器不仅处理 FP16 训练,而且效率极高。权重更新的性能主要受内存带宽的影响,而实现的内存带宽取决于输入操作数的大小。FP16 优化器旨在通过将模型的所有参数合并到一个大型缓冲区中,并在单个内核中应用权重更新,从而最大限度地提高可实现的内存带宽,使其实现高内存带宽。
使用 LAMB 优化器进行大批量训练
DeepSpeed 通过启用 LAMB 优化器,简化了使用大批量进行训练。有关 LAMB 的更多详细信息,请参阅 LAMB 论文。
使用 ZeRO 优化器进行内存高效训练
DeepSpeed 可以在不进行模型并行的情况下训练高达 130 亿参数的模型,并可以通过 16 路模型并行训练高达 2000 亿参数的模型。模型尺寸的这一飞跃是通过 ZeRO 优化器实现的内存效率实现的。有关更多详细信息,请参阅 ZeRO 论文。
训练无关的检查点
DeepSpeed 可以为您简化检查点,无论您是使用数据并行训练、模型并行训练、混合精度训练、这三者的混合,还是使用零优化器来启用更大的模型尺寸。有关更多详细信息,请参阅入门指南和核心 API 文档。
高级参数搜索
DeepSpeed 支持多种学习率调度,以实现大批量缩放的更快收敛。
学习率范围测试
请参阅学习率范围测试教程。
1Cycle 学习率调度
请参阅1Cycle 学习率调度教程。
简化的数据加载器
DeepSpeed 在数据加载方面为用户抽象了数据并行和模型并行。用户只需提供 PyTorch 数据集,DeepSpeed 数据加载器即可自动适当地处理批量创建。
数据效率
请参阅数据效率教程。
课程学习
请参阅课程学习教程。请注意,上述数据效率库提供了更通用的课程学习支持。此遗留课程学习功能仍然受支持,但我们建议使用数据效率库。
性能分析和调试
DeepSpeed 提供了一套用于性能分析和调试的工具。
实际耗时分解
DeepSpeed 提供了训练不同部分所花费时间的详细分解。这可以通过在 deepspeed_config 文件中进行以下设置来启用。
{
"wall_clock_breakdown": true,
}
激活检查点函数计时
当启用激活检查点时,可以在 deepspeed_config 文件中启用每个检查点函数的前向和后向时间分析。
{
"activation_checkpointing": {
"profile": true
}
}
浮点运算分析器
DeepSpeed 浮点运算分析器衡量 PyTorch 模型的时间、浮点运算和参数,并显示哪些模块或层是瓶颈。与 DeepSpeed 运行时一起使用时,浮点运算分析器可以在 deepspeed_config 文件中如下配置
{
"flops_profiler": {
"enabled": true,
"profile_step": 1,
"module_depth": -1,
"top_modules": 3,
"detailed": true,
}
}
浮点运算分析器也可以作为独立包使用。有关更多详细信息,请参阅浮点运算分析器教程。
自动调优
DeepSpeed 自动调优器利用模型信息、系统信息和启发式方法,高效地调优 Zero 阶段、微批量大小和其他 Zero 配置。使用自动调优功能无需 DeepSpeed 用户进行任何代码更改。虽然 "autotuning": {"enabled": true} 是启用自动调优的最低要求,但用户可以定义其他参数来配置自动调优过程。下面显示了自动调优配置中的主要参数及其默认值。有关更多详细信息,请参阅自动调优教程。
{
"autotuning": {
"enabled": true,
"results_dir": null,
"exps_dir": null,
"overwrite": false,
"metric": "throughput",
"num_nodes": null,
"num_gpus": null,
"start_profile_step": 3,
"end_profile_step": 5,
"fast": true,
"num_tuning_micro_batch_sizes": 3,
"tuner_type": "model_based",
"tuner_early_stopping": 5,
"tuner_num_trials": 50,
"arg_mappings": null
}
}
浮点运算分析器也可以作为独立包使用。有关更多详细信息,请参阅浮点运算分析器教程。
监控
DeepSpeed Monitor 将实时训练指标记录到一个或多个监控后端,包括 PyTorch 的 TensorBoard、WandB 或简单地记录到 CSV 文件中。Monitor 可以在 deepspeed_config 文件中配置一个或多个后端,如下所示
{
"tensorboard": {
"enabled": true,
"output_path": "output/ds_logs/",
"job_name": "train_bert"
}
"wandb": {
"enabled": true,
"team": "my_team",
"group": "my_group",
"project": "my_project"
}
"csv_monitor": {
"enabled": true,
"output_path": "output/ds_logs/",
"job_name": "train_bert"
}
}
Monitor 还可以添加日志自定义指标和客户端代码。有关更多详细信息,请参阅Monitor教程。
通信日志
DeepSpeed 提供 deepspeed.comm 中启动的所有通信操作的日志记录。通信日志器可以在 deepspeed_config 文件中如下配置
{
"comms_logger": {
"enabled": true,
"verbose": false,
"prof_all": true,
"debug": false
}
}
然后,客户端代码可以通过调用 deepspeed.comm.log_summary() 打印摘要。有关更多详细信息和示例用法,请参阅通信日志教程。
稀疏注意力
DeepSpeed 提供稀疏注意力以支持长序列。请参阅稀疏注意力教程。
--deepspeed_sparse_attention
"sparse_attention": {
"mode": "fixed",
"block": 16,
"different_layout_per_head": true,
"num_local_blocks": 4,
"num_global_blocks": 1,
"attention": "bidirectional",
"horizontal_global_attention": false,
"num_different_global_patterns": 4
}
专家混合 (MoE)
要了解更多关于使用 DeepSpeed 训练专家混合 (MoE) 模型的信息,请参阅我们的教程以获取更多详细信息。