DeepSpeed 稀疏注意力
基于注意力的深度学习模型,如 Transformer,在捕获输入序列中标记之间的关系方面非常有效,即使是长距离关系也能很好地捕捉。因此,它们被用于文本、图像和声音输入,其中序列长度可以达到数千个标记。然而,尽管注意力模块在捕获长期依赖性方面非常有效,但在实践中,它们在长序列输入上的应用受到计算和内存需求的限制,因为注意力计算的需求与序列长度 n 呈平方关系增长,即 O(n^2)。
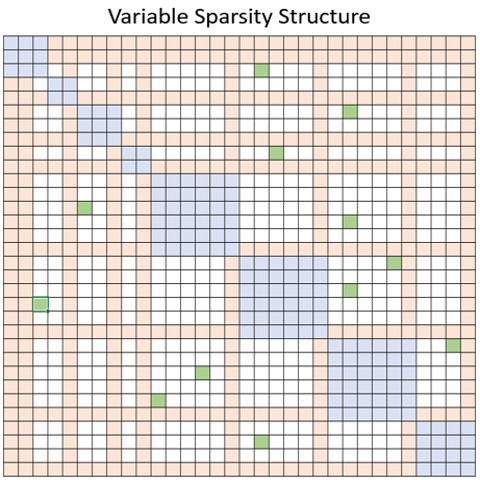
为了解决这一限制,DeepSpeed 提供了一套稀疏注意力内核——这是一项重要技术,可以通过块稀疏计算将注意力计算的计算和内存需求降低几个数量级。这套内核不仅缓解了注意力计算的内存瓶颈,还能高效地执行稀疏计算。它的 API 允许与任何基于 Transformer 的模型方便地集成。除了提供广泛的稀疏结构外,它还具有处理任何用户定义的块稀疏结构的灵活性。更具体地说,稀疏注意力(SA)可以设计为计算相邻标记之间的局部注意力,或者通过局部注意力计算的摘要标记来计算全局注意力。此外,SA 还可以允许随机注意力,或局部、全局和随机注意力的任意组合,如下图中蓝色、橙色和绿色块所示。因此,SA 将内存占用量减少到 O(wn),其中 1 < w < n 是一个参数,其值取决于注意力结构。
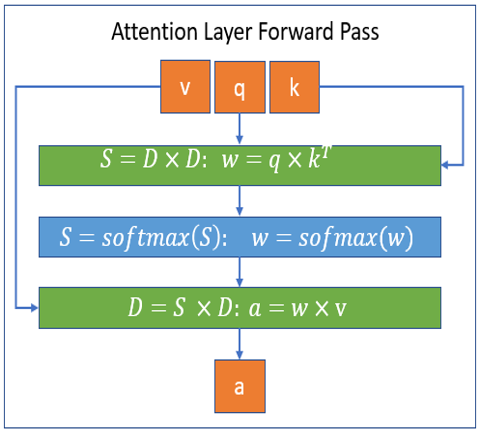
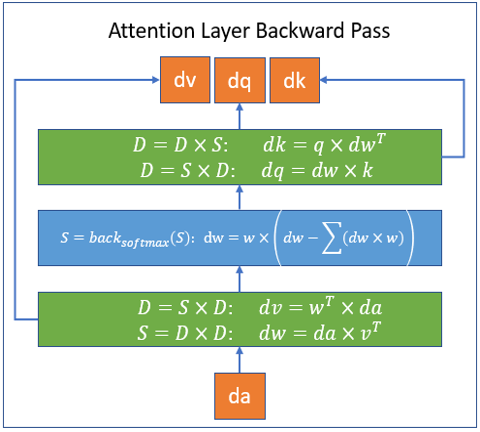
该库基于 PyTorch,并通过 Triton 平台开发所需内核;内核并非用 CUDA 编写,这为未来支持 CPU/OpenCL/Vulkan 留下了可能性。该库是 DeepSpeed 的扩展,可以通过 DeepSpeed 使用,也可以独立使用。DeepSpeed 稀疏注意力内核处理的块稀疏计算分别在以下图中展示了前向和后向传播。图中,S 代表一个 块稀疏矩阵,D 代表一个 密集矩阵。
要了解更多关于稀疏性配置(Sparsity Config)以及如何使用此库的信息,请查阅我们的教程,其中提供了详细信息。
性能结果
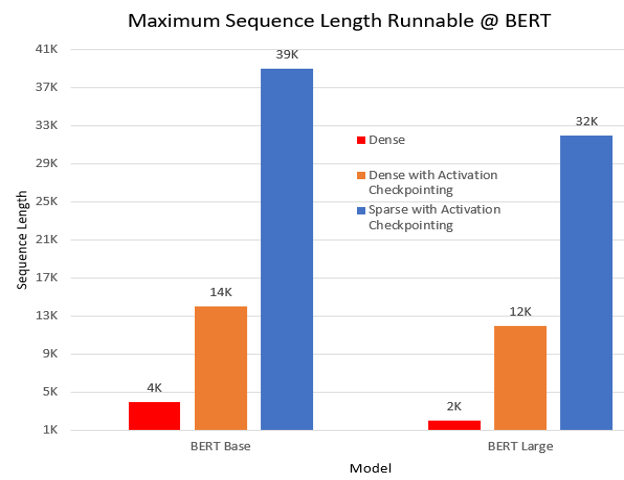
- 支持超过 10 倍更长的序列 在一项预训练实验中,我们对 BERT 模型进行了三种设置下的运行:密集(dense)、带激活检查点(activation checkpoint)的密集,以及带激活检查点的稀疏(SA)。与密集模式相比,SA 使得 BERT base 和 large 模型分别能够支持 10 倍和 16 倍更长的序列。下图展示了 BERT base 和 large 模型可运行的最长序列长度;实验在单块 NVIDIA V100 GPU(32GB 内存)上以批处理大小 1 进行。
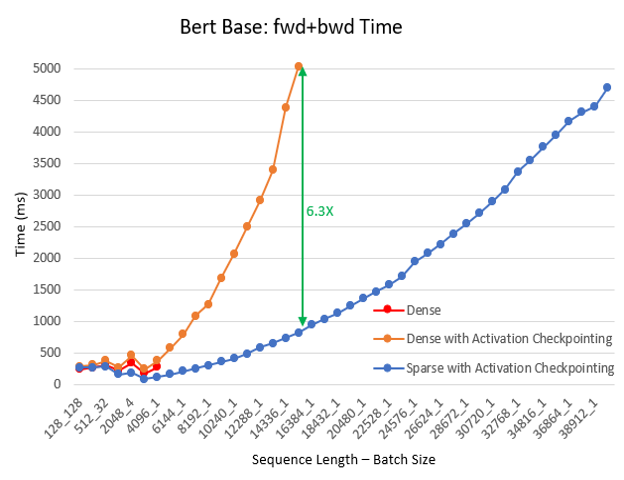
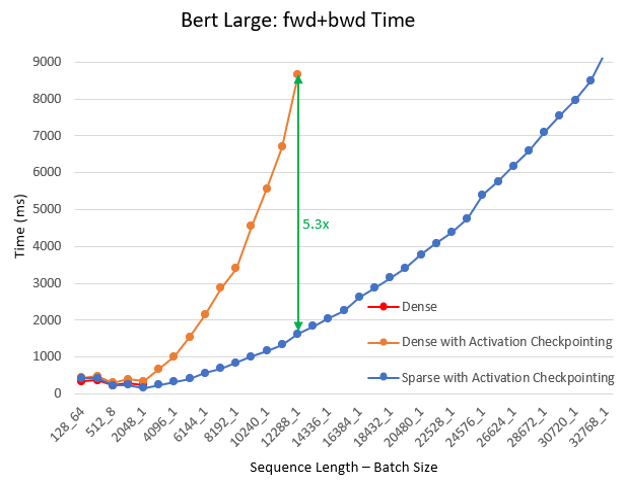
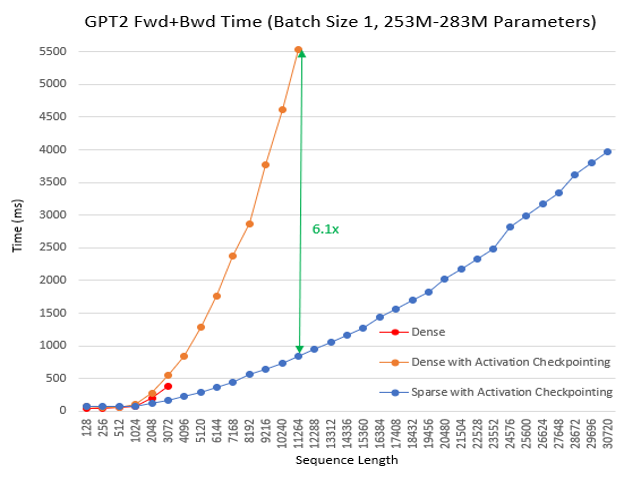
- 计算速度最高提升 6.3 倍 我们继续对不同的批处理大小和序列长度进行了预训练实验,使用了 BERT base/large 和 Megatron GPT2。在该实验中,我们让训练持续 100 迭代,并记录了最后 30 迭代的平均时间。与密集模式相比,SA 减少了总计算量并提高了训练速度:随着序列长度的增加,加速效果更为显著,其中 BERT base 最高提升 6.3 倍,BERT large 最高提升 5.3 倍,GPT2 最高提升 6.1 倍。以下图表显示了这些结果。
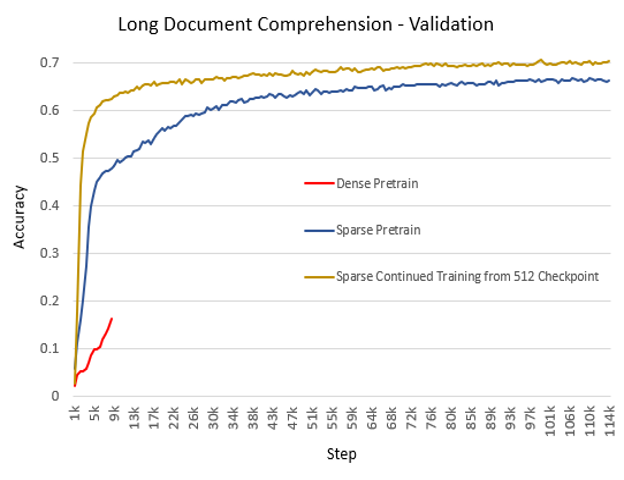
- 更高准确性 稀疏注意力相关的研究工作(Sparse Transformer、Longformer、BigBird)已经表明其准确性可与全注意力媲美或更高。我们的经验与此高度一致。除了更低的内存开销和更快的计算速度外,我们还在生产中观察到 SA 实现了更高的准确性和更快的收敛速度。下图展示了基于 BERT 的生产模型在长文档理解(2048 序列长度)任务上的训练准确性。实验在三种设置下进行:从头开始的密集模式、从头开始的 SA 模式,以及从使用 512 序列长度的密集模式检查点继续训练的 SA 模式。我们观察到,对于从头开始的预训练,SA 比密集模式收敛更快,准确性更高。此外,SA 从预训练检查点继续训练时,在时间和准确性方面表现甚至更好。
- 与最先进技术 Longformer 的比较 我们将 SA 与 Longformer 进行了比较,Longformer 是一种最先进的稀疏结构和实现。在我们的实验中,SA 使用
Fixed稀疏性,两种实现具有可比的准确性。在系统性能方面,SA 在训练和推理方面都优于 Longformer。- 在 Wikitext103 上进行 MLM 预训练时执行速度提升 1.47 倍 我们按照 Longformer 提供的notebook运行了一个实验。在这个实验中,我们使用 RoBERTa-base 检查点预训练了一个 MLM 模型。这在 8 块 V100-SXM2 GPU 上完成。下表显示了详细结果,其中使用 DeepSpeed 稀疏注意力显示出 1.47 倍的加速。
| 模型 | 局部窗口大小 | BPC | 训练步数 | 每次迭代时间 | 时间提升 | 准确性提升 |
|---|---|---|---|---|---|---|
| RoBERTa 检查点 | 2.5326 | |||||
| Longformer | 512 | 2.6535 | 0 | 1.47 | 1.01 | |
| 稀疏注意力 | 2.6321 | |||||
| Longformer | 1.6708 | 3k | 1.6280 | 1.01 | ||
| 稀疏注意力 | 1.6613 | 1.1059 | ||||
| Longformer | 64 | 5.7840 | 0 | 1.31 | 1.46 | |
| 稀疏注意力 | 3.9737 | |||||
| Longformer | 2.0466 | 3k | 1.4855 | 1.09 | ||
| 稀疏注意力 | 1.8693 | 1.1372 |
- BERT-Base 推理执行速度提升 3.13 倍 通过我们上面描述的长文档理解应用,我们还检查了在
2048序列长度和批处理大小1的 BERT 模型上测试不同窗口大小的推理时间。在此实验中,我们将 BERT 注意力替换为 DeepSpeed 稀疏注意力而不是 Longformer 注意力后,观察到高达3.13 倍的加速。下表显示了完整结果。
| 局部窗口大小 | 时间提升 |
|---|---|
| 512 | 3.13 |
| 256 | 2.29 |
| 128 | 2.16 |
| 64 | 1.5 |
| 32 | 1.24 |
| 16 | 1.23 |
- 灵活处理任何块稀疏结构 DeepSpeed 稀疏注意力套件并非针对任何特定的稀疏结构,而是让模型科学家能够探索任何具有高效系统支持的块稀疏结构。目前,我们已添加了流行的稀疏结构,例如:
- 固定(Fixed) (来自 OpenAI Sparse Transformer)
- BigBird (来自 Google)
- BSLongformer (AI2 Longformer 的块稀疏实现)
我们还定义了一个模板,用于具有 可变 结构(上图),可用于简单地自定义任何块稀疏的随机/局部/全局注意力模式。除了此列表之外,用户还可以添加任何其他稀疏结构,如教程部分所述。