监控
在本教程中,我们将介绍 DeepSpeed Monitor 并提供其使用示例。
概述
在训练过程中监控模型和系统指标对于确保硬件资源得到充分利用至关重要。DeepSpeed Monitor 支持通过一个或多个监控后端(如 PyTorch 的 TensorBoard、WandB、Comet)以及简单的 CSV 文件实时记录指标。
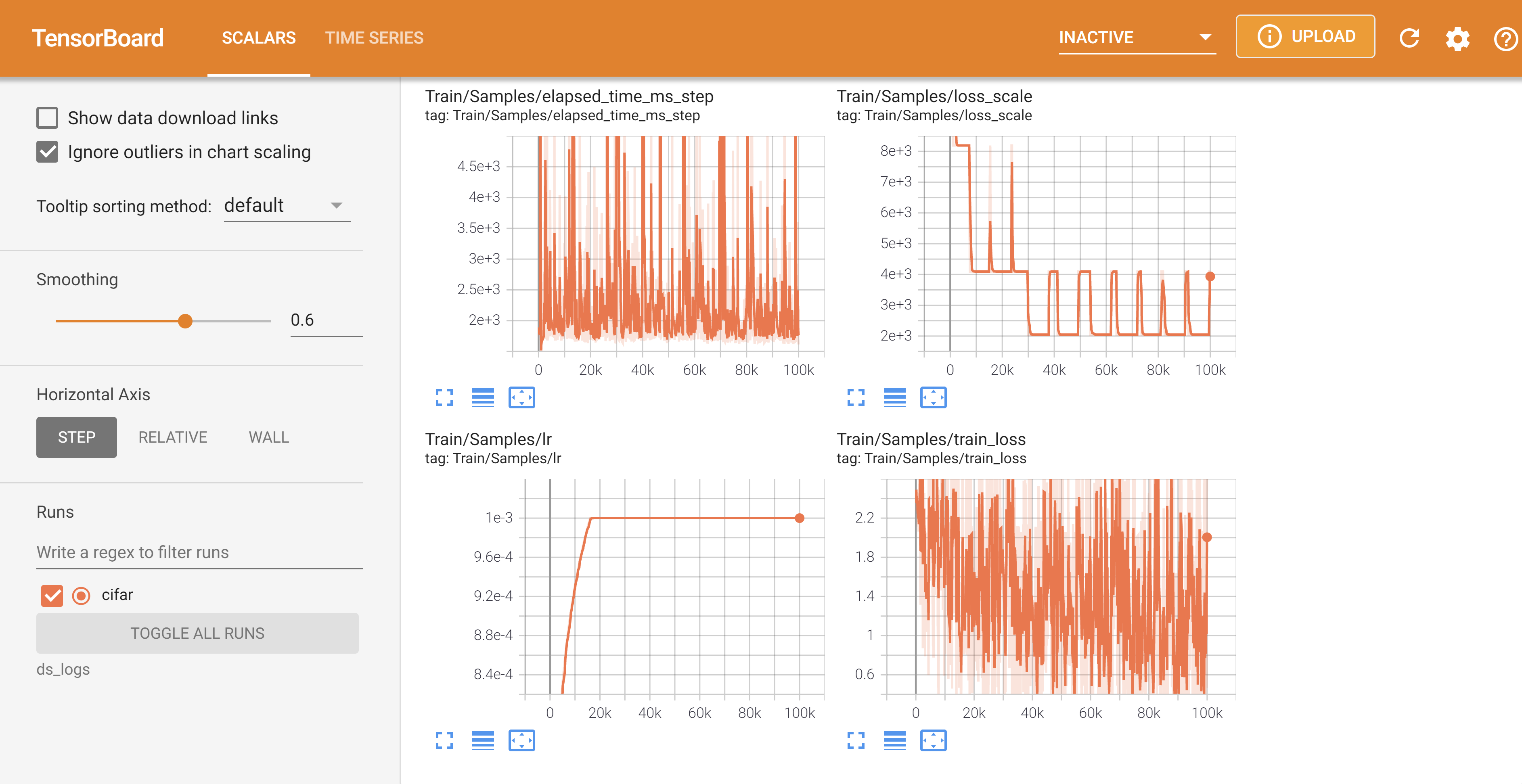
以下是 TensorBoard 的实时监控视图
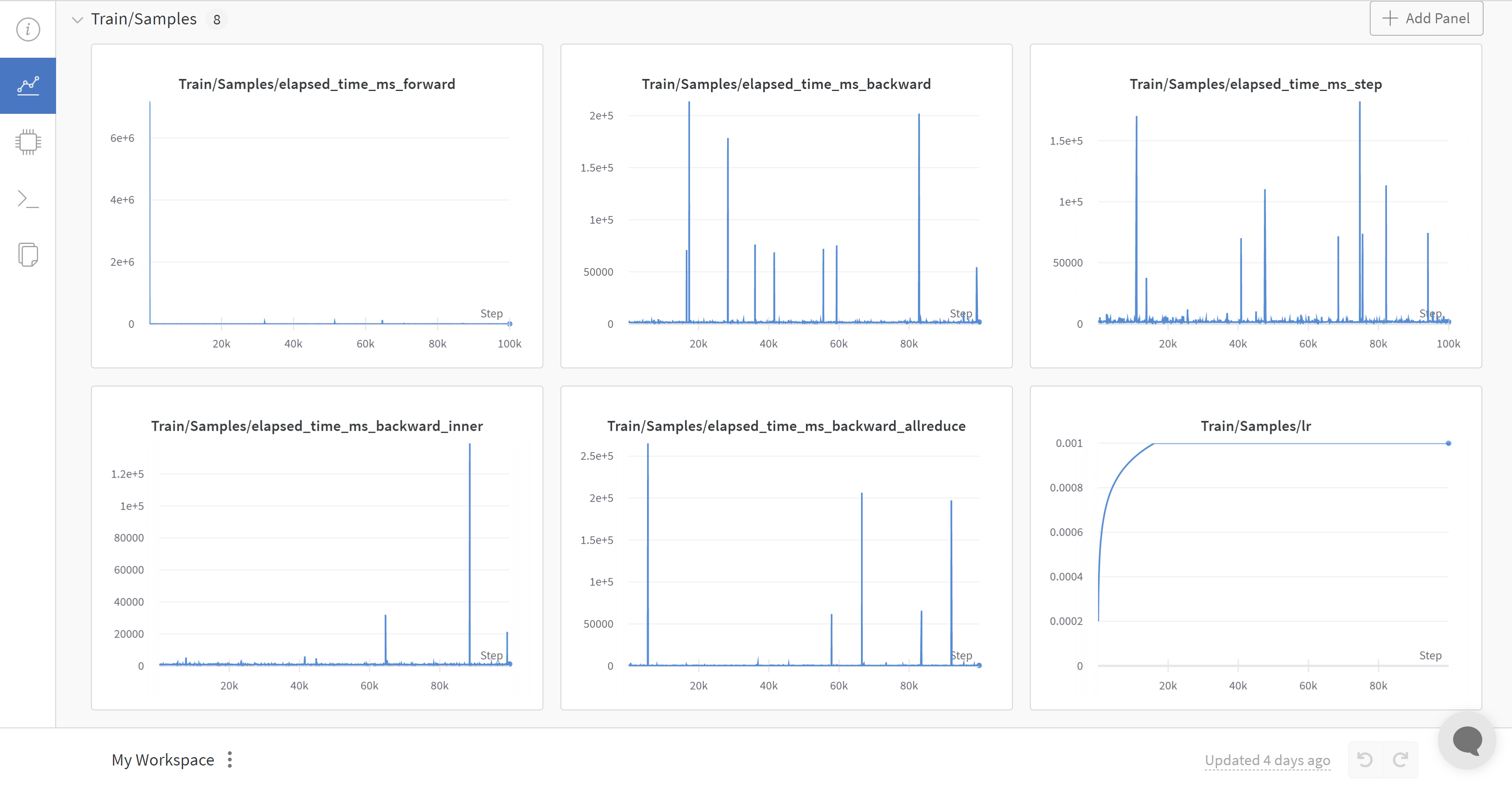
以下是 WandB 的实时监控视图
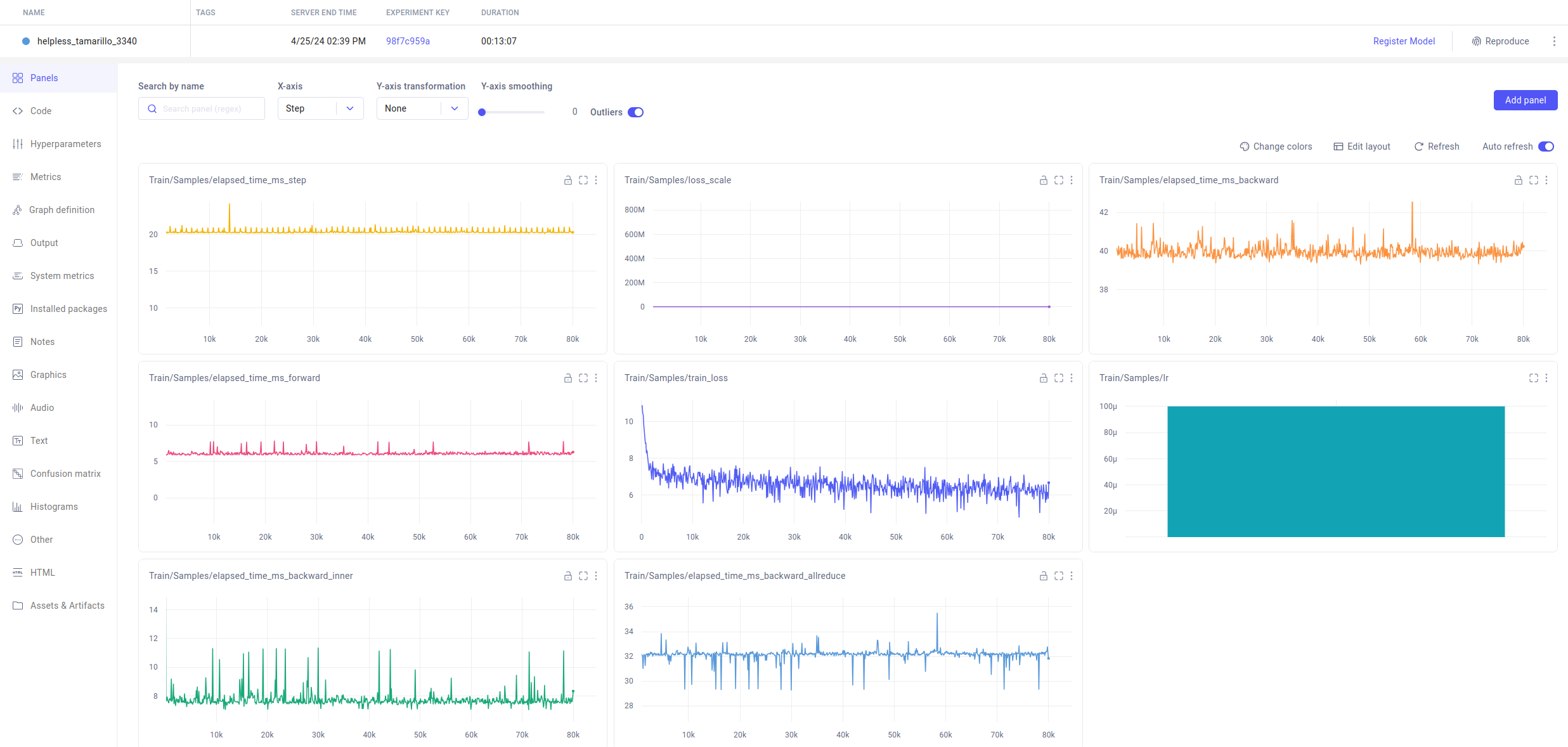
以下是 Comet 的实时监控视图
用法
DeepSpeed Monitor 在 DeepSpeed 配置文件中进行配置。DeepSpeed 将自动监控关键训练指标,包括那些使用 wall_clock_breakdown 配置选项跟踪的指标。此外,用户还可以记录自己的自定义事件和指标。
自动监控
在使用 DeepSpeed 进行模型训练时,Monitor 可以在 DeepSpeed 配置文件中进行配置。无需显式 API 调用即可使用 Monitor。通过在 DeepSpeed 的 JSON 配置文件中添加以下字段即可启用 Monitor。详见监控部分。
{
"tensorboard": {
"enabled": true,
"output_path": "output/ds_logs/",
"job_name": "train_bert"
}
"wandb": {
"enabled": true,
"team": "my_team",
"group": "my_group",
"project": "my_project"
}
"comet": {
"enabled": true,
"project": "my_project",
"experiment_name": "my_experiment"
}
"csv_monitor": {
"enabled": true,
"output_path": "output/ds_logs/",
"job_name": "train_bert"
}
}
DeepSpeed 将自动记录到配置中列出的所有可用且已启用的监控后端,并生成如上所示的实时监控视图。
自定义监控
除了自动监控,用户还可以在客户端脚本中记录自己的自定义指标。目前,初始化 Monitor 对象有两种方式:
- (推荐) - 创建一个
MonitorMaster(ds_config.monitor_config)对象,该对象将自动初始化 DeepSpeed 配置中存在的所有监控后端 - 创建一个特定的
TensorBoardMonitor(ds_config.monitor_config)、WandbMonitor(ds_config.monitor_config)或csvMonitor(ds_config.monitor_config)对象,该对象将只初始化 DeepSpeed 配置中存在的特定监控后端
创建自定义监控器的步骤如下:
- 导入所需的 Monitor
- 使用 DeepSpeed 配置的
monitor_config初始化监控器 - 创建一个包含一个或多个三元组的列表,格式为
[("label", value, ds_engine.global_samples), ...]* - 对步骤 3 中的列表调用
monitor.write_events
* 注意 - 某些 Monitor 后端不支持混合样本值。请确保在每个三元组中使用 DeepSpeed 引擎对象的 global_samples 属性
有关用法示例,请参见以下修改后的 DeepSpeedExamples/cifar 示例
# Step 1: Import monitor (and DeepSpeed config, if needed)
from deepspeed.monitor.monitor import MonitorMaster
from deepspeed.runtime.config import DeepSpeedConfig
# Step 2: Initialized monitor with DeepSpeed config (get DeepSpeed config object, if needed)
ds_config = DeepSpeedConfig("ds_config.json")
monitor = MonitorMaster(ds_config.monitor_config)
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader):
pre = time.time()
inputs, labels = data[0].to(model_engine.local_rank), data[1].to(
model_engine.local_rank)
if fp16:
inputs = inputs.half()
outputs = model_engine(inputs)
loss = criterion(outputs, labels)
model_engine.backward(loss)
model_engine.step()
post = time.time()
# Step 3: Create list of 3-tuple records (single entry in this case)
events = [("Time per step", post-pre, model_engine.global_samples)]
# Step 4: Call monitor.write_events on the list from step 3
monitor.write_events(events)