1周期调度
本教程展示了如何在 PyTorch 中实现学习率和动量的1周期调度。
1周期调度
最近的研究表明,通过在训练期间使用循环和衰减调度来调整学习率和动量等关键超参数,可以解决大批处理大小训练的慢收敛问题。在 DeepSpeed 中,我们实现了一种名为 1-Cycle 的最先进调度,以帮助数据科学家有效利用更大的批处理大小在 PyTorch 中训练他们的模型。
先决条件
要使用 1周期调度进行模型训练,您应满足以下两个要求
- 使用开始入门指南将 DeepSpeed 集成到您的训练脚本中。
- 将配置 1周期调度的参数添加到您的模型参数中。我们将在下面定义 1周期参数。
概述
1周期调度在两个阶段运行:循环阶段和衰减阶段,这两个阶段跨越训练数据的一次迭代。具体来说,我们将回顾 1周期学习率调度的工作原理。在循环阶段,学习率在一定数量的训练步骤中在最小值和最大值之间振荡。在衰减阶段,学习率从循环阶段的最小值开始衰减。模型训练期间 1周期学习率调度的示例如下所示。
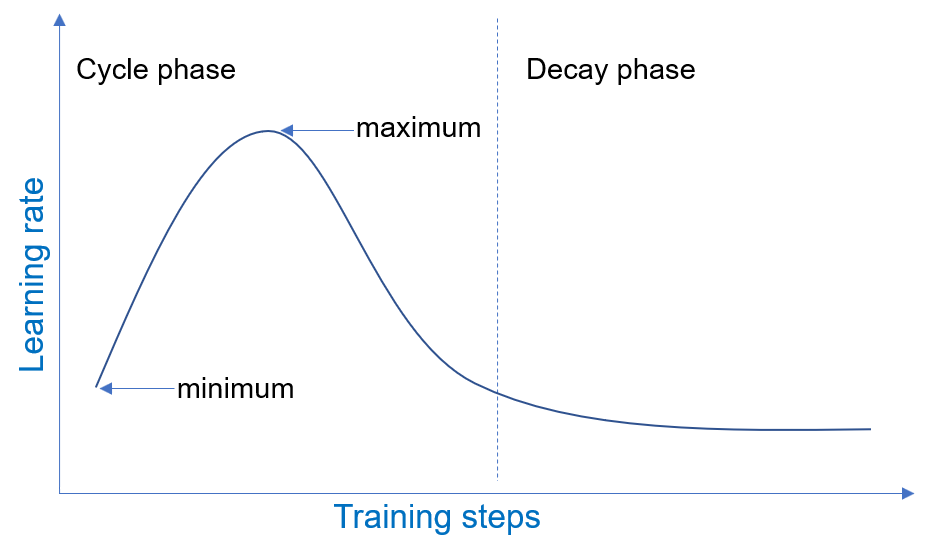
1周期参数
1周期调度由许多参数定义,这些参数允许用户探索不同的配置。文献建议同时调整学习率和动量,因为它们是相关的超参数。我们利用这一建议,通过将 1周期参数分为两组来减少配置负担
- 用于配置循环和衰减阶段的全局参数。
- 用于配置学习率和动量的局部参数。
配置 1周期阶段的全局参数为
cycle_first_step_size: 完成循环阶段第一步的训练步数。cycle_first_stair_count: 循环阶段第一步的更新(或阶梯)计数。cycle_second_step_size: 完成循环阶段第二步的训练步数。cycle_second_stair_count: 循环阶段第二步的更新(或阶梯)计数。post_cycle_decay_step_size: 衰减阶段超参数衰减的训练步长间隔。
超参数的局部参数为
学习率:
cycle_min_lr: 循环阶段的最小学习率。cycle_max_lr: 循环阶段的最大学习率。decay_lr_rate: 衰减阶段学习率的衰减率。
虽然 cycle_min_lr 和 cycle_max_lr 的适当值可以根据经验或专业知识选择,但我们建议使用 DeepSpeed 的学习率范围测试功能来配置它们。
动量
cycle_min_mom: 循环阶段的最小动量。cycle_max_mom: 循环阶段的最大动量。decay_mom_rate: 衰减阶段动量的衰减率。
所需的模型配置更改
为了说明在模型训练中使用 1周期调度所需的模型配置更改,我们将使用具有以下属性的调度
- 一个对称的循环阶段,其中循环的每一半跨越相同数量的训练步数。对于此示例,学习率将需要 1000 个训练步从 0.0001 增加到 0.0010(10 倍缩放),然后又降低回 0.0001。动量将在相似的步数内在 0.85 和 0.99 之间相应循环。
- 一个衰减阶段,学习率每 1000 步衰减 0.001,而动量不衰减。
请注意,这些参数由 DeepSpeed 作为会话参数处理,因此应将其添加到模型配置的相应部分。
PyTorch 模型
PyTorch 1.0.1 及更高版本提供了一个实现超参数调度器的功能,称为学习率调度器。我们已使用此功能实现了 1周期调度。您将添加一个类型为“OneCycle”的调度器条目,如下所示。
"scheduler": {
"type": "OneCycle",
"params": {
"cycle_first_step_size": 1000,
"cycle_first_stair_count": 500,
"cycle_second_step_size": 1000,
"cycle_second_stair_count": 500,
"decay_step_size": 1000,
"cycle_min_lr": 0.0001,
"cycle_max_lr": 0.0010,
"decay_lr_rate": 0.001,
"cycle_min_mom": 0.85,
"cycle_max_mom": 0.99,
"decay_mom_rate": 0.0
}
},
批处理缩放示例
作为 1周期调度如何实现有效批处理缩放的示例,我们简要分享了我们在 Microsoft 内部模型上的经验。在这种情况下,该模型在单个 GPU 上已针对快速收敛(在数据样本中)进行了良好调整,但在 8 个 GPU(8 倍批处理大小)上训练时,收敛到目标性能 (AUC) 的速度很慢。下图显示了 8 个 GPU 在这些学习率调度下的模型收敛情况
- 固定:使用 1 个 GPU 训练的最佳固定学习率。
- 线性缩放:使用固定学习率的 8 倍的固定学习率。
- 1周期:使用 1周期调度。
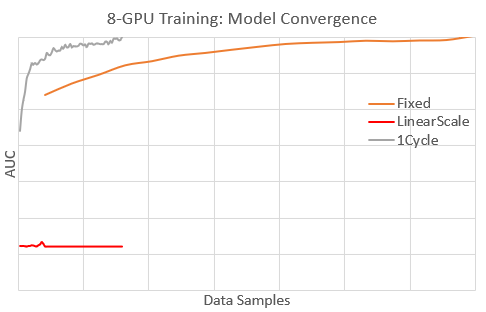
使用 1周期,模型比其他调度更快地收敛到目标 AUC。实际上,1周期的收敛速度与最佳的 1-GPU 训练(未显示)一样快。对于固定,收敛速度慢约 5 倍(需要多 5 倍的数据样本)。使用线性缩放,模型发散,因为学习率过高。下图通过报告 8-GPU 训练期间的学习率值来说明这些调度。
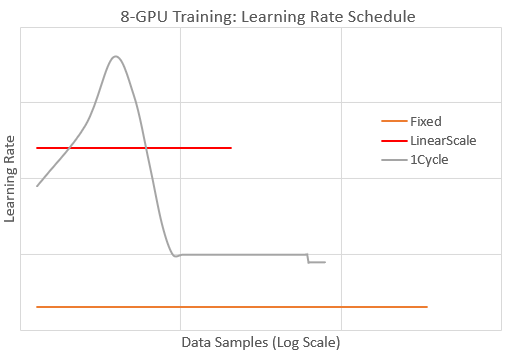
我们看到,1周期的学习率始终大于固定,并且在短时间内大于线性缩放以实现更快的收敛。此外,1周期在训练后期会降低学习率以避免模型发散,这与线性缩放不同。总而言之,通过配置适当的 1周期调度,我们能够有效地将此模型的训练批处理大小缩放 8 倍,而不会损失收敛速度。