Megatron-LM GPT2
如果您还没有,我们建议您先阅读入门指南,然后再学习本教程。
在本教程中,我们将为 Megatron-LM GPT2 模型(一个大型、功能强大的 transformer)添加 DeepSpeed。Megatron-LM 支持模型并行和多节点训练。更多详情请参阅相关论文:Megatron-LM: 使用模型并行训练数十亿参数语言模型。
首先,我们讨论数据和环境设置以及如何使用原始 Megatron-LM 训练 GPT-2 模型。接下来,我们逐步启用该模型以使用 DeepSpeed 运行。最后,我们演示使用 DeepSpeed 带来的性能提升和内存占用减少。
使用原始 Megatron-LM 训练 GPT-2
我们已将原始模型代码从 Megatron-LM 复制到 DeepSpeed Megatron-LM 并将其作为子模块提供。要下载,请执行
git submodule update --init --recursive
训练数据设置
- 按照 Megatron 的说明下载
webtext数据并将其符号链接放置在DeepSpeedExamples/Megatron-LM/data下。
运行未修改的 Megatron-LM GPT2 模型
- 对于单 GPU 运行
- 更改
scripts/pretrain_gpt2.sh,将其--train-data参数设置为"webtext"。 - 运行
bash scripts/pretrain_gpt2.sh
- 更改
- 对于多 GPU 和/或多节点运行
- 更改
scripts/pretrain_gpt2_model_parallel.sh- 将其
--train-data参数设置为"webtext" GPUS_PER_NODE表示每个节点参与测试的 GPU 数量NNODES表示参与测试的节点数量
- 将其
- 运行
bash scripts/pretrain_gpt2_model_parallel.sh
- 更改
启用 DeepSpeed
要使用 DeepSpeed,我们将修改三个文件
arguments.py:参数配置pretrain_gpt2.py:训练主入口utils.py:检查点保存和加载实用程序
参数解析
第一步是使用 deepspeed.add_config_arguments() 在 arguments.py 中为 Megatron-LM GPT2 模型添加 DeepSpeed 参数。
def get_args():
"""Parse all the args."""
parser = argparse.ArgumentParser(description='PyTorch BERT Model')
parser = add_model_config_args(parser)
parser = add_fp16_config_args(parser)
parser = add_training_args(parser)
parser = add_evaluation_args(parser)
parser = add_text_generate_args(parser)
parser = add_data_args(parser)
# Include DeepSpeed configuration arguments
parser = deepspeed.add_config_arguments(parser)
初始化和训练
我们将修改 pretrain.py 以启用 DeepSpeed 训练。
初始化
我们使用 deepspeed.initialize 创建 model_engine、optimizer 和 LR scheduler。下面是其定义
def initialize(args,
model,
optimizer=None,
model_parameters=None,
training_data=None,
lr_scheduler=None,
mpu=None,
dist_init_required=True,
collate_fn=None):
对于 Megatron-LM GPT2 模型,我们在其 setup_model_and_optimizer() 函数中初始化 DeepSpeed,如下所示,以传递原始的 model、optimizer、args、lr_scheduler 和 mpu。
def setup_model_and_optimizer(args):
"""Setup model and optimizer."""
model = get_model(args)
optimizer = get_optimizer(model, args)
lr_scheduler = get_learning_rate_scheduler(optimizer, args)
if args.deepspeed:
import deepspeed
print_rank_0("DeepSpeed is enabled.")
model, optimizer, _, lr_scheduler = deepspeed.initialize(
model=model,
optimizer=optimizer,
args=args,
lr_scheduler=lr_scheduler,
mpu=mpu,
dist_init_required=False
)
请注意,当启用 FP16 时,Megatron-LM GPT2 会为 Adam 优化器添加一个包装器。DeepSpeed 有自己的 FP16 优化器,因此我们需要将 Adam 优化器直接传递给 DeepSpeed,无需任何包装。当启用 DeepSpeed 时,我们从 get_optimizer() 返回未包装的 Adam 优化器。
def get_optimizer(model, args):
"""Setup the optimizer."""
......
# Use Adam.
optimizer = Adam(param_groups,
lr=args.lr, weight_decay=args.weight_decay)
if args.deepspeed:
# fp16 wrapper is not required for DeepSpeed.
return optimizer
使用训练 API
由 deepspeed.initialize 返回的 model 是DeepSpeed 模型引擎,我们将使用它通过前向、反向和步进 API 训练模型。
前向传播
前向传播 API 与 PyTorch 兼容,无需更改。
反向传播
通过直接在模型引擎上调用 backward(loss) 来完成反向传播。
def backward_step(optimizer, model, lm_loss, args, timers):
"""Backward step."""
# Total loss.
loss = lm_loss
# Backward pass.
if args.deepspeed:
model.backward(loss)
else:
optimizer.zero_grad()
if args.fp16:
optimizer.backward(loss, update_master_grads=False)
else:
loss.backward()
在权重使用 mini-batch 更新后,DeepSpeed 会自动处理梯度归零。
此外,DeepSpeed 在内部处理分布式数据并行和 FP16,从而简化了多处代码。
(A) DeepSpeed 还在梯度累积边界处自动执行梯度平均。因此我们跳过 allreduce 通信。
if args.deepspeed:
# DeepSpeed backward propagation already addressed all reduce communication.
# Reset the timer to avoid breaking timer logs below.
timers('allreduce').reset()
else:
torch.distributed.all_reduce(reduced_losses.data)
reduced_losses.data = reduced_losses.data / args.world_size
if not USE_TORCH_DDP:
timers('allreduce').start()
model.allreduce_params(reduce_after=False,
fp32_allreduce=args.fp32_allreduce)
timers('allreduce').stop()
(B) 我们也跳过更新主梯度,因为 DeepSpeed 在内部处理它。
# Update master gradients.
if not args.deepspeed:
if args.fp16:
optimizer.update_master_grads()
# Clipping gradients helps prevent the exploding gradient.
if args.clip_grad > 0:
if not args.fp16:
mpu.clip_grad_norm(model.parameters(), args.clip_grad)
else:
optimizer.clip_master_grads(args.clip_grad)
return lm_loss_reduced
更新模型参数
DeepSpeed 引擎中的 step() 函数更新模型参数和学习率。
if args.deepspeed:
model.step()
else:
optimizer.step()
# Update learning rate.
if not (args.fp16 and optimizer.overflow):
lr_scheduler.step()
else:
skipped_iter = 1
损失缩放
GPT2 训练脚本在训练期间记录损失缩放值。在 DeepSpeed 优化器内部,此值存储为 cur_scale,而不是像 Megatron 优化器中那样存储为 loss_scale。因此,我们在日志字符串中进行了适当替换。
if args.fp16:
log_string += ' loss scale {:.1f} |'.format(
optimizer.cur_scale if args.deepspeed else optimizer.loss_scale)
检查点保存与加载
DeepSpeed 引擎拥有灵活的 API,用于检查点保存和加载,以处理客户端模型及其自身的内部状态。
def save_checkpoint(self, save_dir, tag, client_state={})
def load_checkpoint(self, load_dir, tag)
要使用 DeepSpeed,我们需要更新 Megatron-LM GPT2 保存和加载检查点的 utils.py。
创建一个新函数 save_ds_checkpoint(),如下所示。新函数收集客户端模型状态并通过调用 DeepSpeed 的 save_checkpoint() 将它们传递给 DeepSpeed 引擎。
def save_ds_checkpoint(iteration, model, args):
"""Save a model checkpoint."""
sd = {}
sd['iteration'] = iteration
# rng states.
if not args.no_save_rng:
sd['random_rng_state'] = random.getstate()
sd['np_rng_state'] = np.random.get_state()
sd['torch_rng_state'] = torch.get_rng_state()
sd['cuda_rng_state'] = get_accelerator().get_rng_state()
sd['rng_tracker_states'] = mpu.get_cuda_rng_tracker().get_states()
model.save_checkpoint(args.save, iteration, client_state = sd)
在 Megatron-LM GPT2 的 save_checkpoint() 函数中,添加以下行以调用上述 DeepSpeed 函数。
def save_checkpoint(iteration, model, optimizer,
lr_scheduler, args):
"""Save a model checkpoint."""
if args.deepspeed:
save_ds_checkpoint(iteration, model, args)
else:
......
在 load_checkpoint() 函数中,使用 DeepSpeed 检查点加载 API,如下所示,并返回客户端模型的状态。
def load_checkpoint(model, optimizer, lr_scheduler, args):
"""Load a model checkpoint."""
iteration, release = get_checkpoint_iteration(args)
if args.deepspeed:
checkpoint_name, sd = model.load_checkpoint(args.load, iteration)
if checkpoint_name is None:
if mpu.get_data_parallel_rank() == 0:
print("Unable to load checkpoint.")
return iteration
else:
......
DeepSpeed 激活检查点 (可选)
DeepSpeed 可以通过在模型并行 GPU 之间划分激活检查点或将其卸载到 CPU 来减少模型并行训练期间的激活内存。这些优化是可选的,除非激活内存成为瓶颈,否则可以跳过。要启用分区激活,我们使用 deepspeed.checkpointing API 替换 Megatron 的激活检查点和随机状态跟踪器 API。替换应在这些 API 首次调用之前发生。
a) 在 pretrain_gpt.py 中替换
# Optional DeepSpeed Activation Checkpointing Features
#
if args.deepspeed and args.deepspeed_activation_checkpointing:
set_deepspeed_activation_checkpointing(args)
def set_deepspeed_activation_checkpointing(args):
deepspeed.checkpointing.configure(mpu,
deepspeed_config=args.deepspeed_config,
partition_activation=True)
mpu.checkpoint = deepspeed.checkpointing.checkpoint
mpu.get_cuda_rng_tracker = deepspeed.checkpointing.get_cuda_rng_tracker
mpu.model_parallel_cuda_manual_seed =
deepspeed.checkpointing.model_parallel_cuda_manual_seed
b) 在 mpu/transformer.py 中替换
if deepspeed.checkpointing.is_configured():
global get_cuda_rng_tracker, checkpoint
get_cuda_rng_tracker = deepspeed.checkpoint.get_cuda_rng_tracker
checkpoint = deepspeed.checkpointing.checkpoint
通过这些替换,各种 DeepSpeed 激活检查点优化(例如激活分区、连续检查点和 CPU 检查点)可以通过 deepspeed.checkpointing.configure 或在 deepspeed_config 文件中指定。
训练脚本
我们假设 webtext 数据已在上一步中准备好。要开始使用 DeepSpeed 训练 Megatron-LM GPT2 模型,请执行以下命令开始训练。
- 单 GPU 运行
- 运行
bash scripts/ds_pretrain_gpt2.sh
- 运行
- 多 GPU/节点运行
- 运行
bash scripts/ds_zero2_pretrain_gpt2_model_parallel.sh
- 运行
使用 GPT-2 进行 DeepSpeed 评估
DeepSpeed 通过先进的 ZeRO 优化器实现了有效训练超大型模型。2020 年 2 月,我们在 DeepSpeed 中发布了 ZeRO 的一个子集优化,执行优化器状态分区。我们称之为 ZeRO-1。2020 年 5 月,我们将 DeepSpeed 中的 ZeRO-1 扩展,以包括 ZeRO 的其他优化,包括梯度和激活分区,以及连续内存优化。我们将此版本称为 ZeRO-2。
ZeRO-2 显著减少了训练大型模型的内存占用,这意味着可以用 i) 更少的模型并行度和 ii) 更大的批处理大小来训练大型模型。较低的模型并行度通过增加计算(例如矩阵乘法,其性能与矩阵大小直接相关)的粒度来提高训练效率。此外,较少的模型并行度还导致模型并行 GPU 之间的通信减少,从而进一步提高性能。更大的批处理大小具有类似的效果,即增加计算粒度并减少通信,也带来更好的性能。因此,通过 DeepSpeed 和 ZeRO-2 集成到 Megatron 中,我们将模型规模和速度提升到一个全新的水平,超越了单独使用 Megatron 的表现。
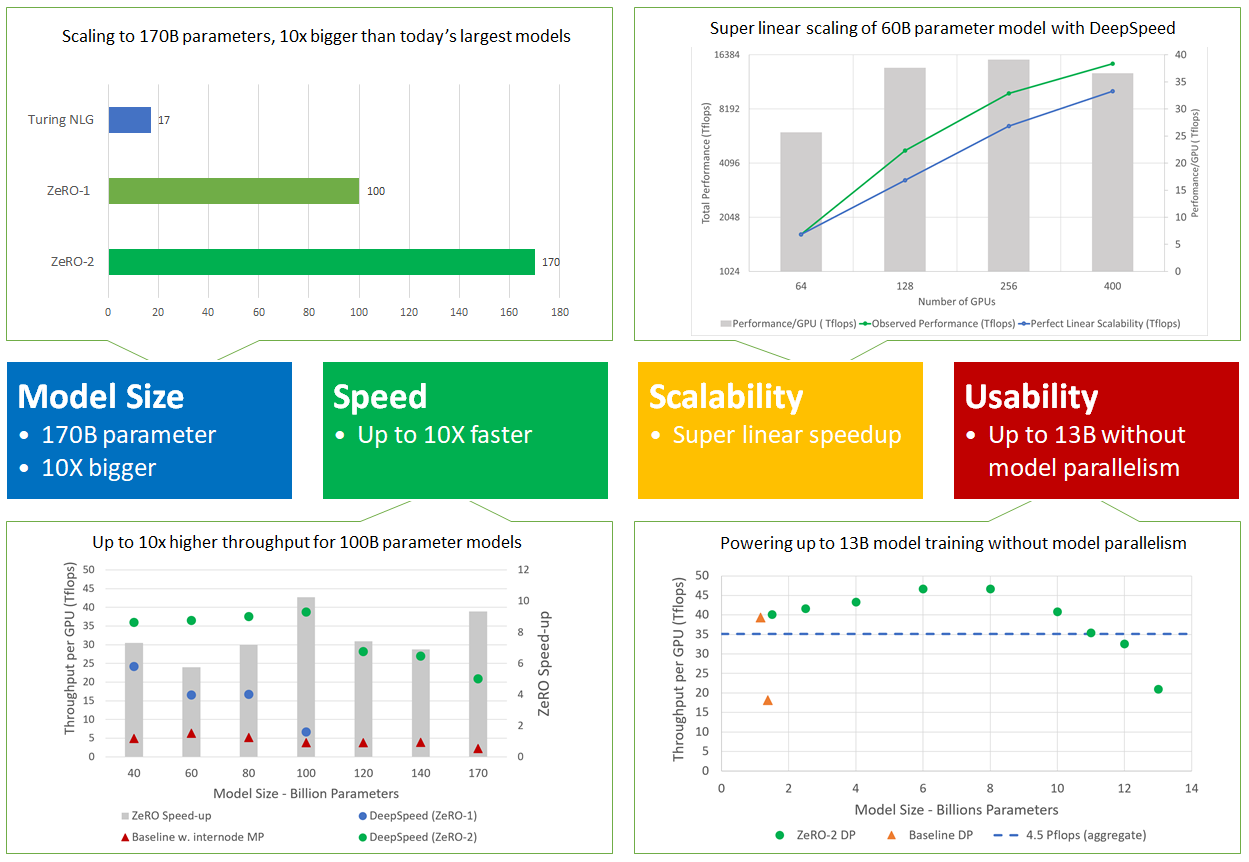
图 2:ZeRO-2 扩展到 1700 亿个参数,吞吐量提高达 10 倍,获得超线性加速,并通过避免对多达 130 亿个参数的模型进行代码重构来提高可用性。
更具体地说,DeepSpeed 和 ZeRO-2 在四个方面表现出色(如图 2 所示),支持大一个数量级的模型,速度提高达 10 倍,具有超线性可扩展性,并提高了可用性以使大型模型训练大众化。这四个方面详述如下。
模型大小:最先进的大型模型,如 OpenAI GPT-2、NVIDIA Megatron-LM、Google T5 和 Microsoft Turing-NLG 分别具有 1.5B、8.3B、11B 和 17B 参数。ZeRO-2 提供了系统支持,可以高效运行 1700 亿参数的模型,比这些最大的模型大一个数量级(图 2,左上)。
速度:改进的内存效率带来更高的吞吐量和更快的训练。图 2(左下)显示了 ZeRO-2 和 ZeRO-1 的系统吞吐量(两者都结合了 ZeRO 驱动的数据并行和 NVIDIA Megatron-LM 模型并行),以及单独使用最先进的模型并行方法 Megatron-LM(图 2,左下基线)的吞吐量。ZeRO-2 在由 400 个 NVIDIA V100 GPU 组成的集群上运行 1000 亿参数的模型,每个 GPU 的浮点运算能力超过 38 teraflops,总聚合性能超过 15 petaflops。对于相同大小的模型,ZeRO-2 的训练速度比单独使用 Megatron-LM 快 10 倍,比 ZeRO-1 快 5 倍。
可扩展性:我们观察到超线性加速(图 2,右上),当 GPU 数量翻倍时,性能提高不止一倍。ZeRO-2 随着数据并行度的增加而减少模型状态的内存占用,使我们能够在每个 GPU 上拟合更大的批处理大小,从而获得更好的性能。
大型模型训练大众化:ZeRO-2 使模型科学家能够有效地训练多达 130 亿参数的模型,而无需通常需要模型重构的模型并行性(图 2,右下)。130 亿参数比大多数最先进的大型模型(例如 Google T5,具有 110 亿参数)更大。因此,模型科学家可以自由地试验大型模型,而无需担心模型并行性。相比之下,经典数据并行方法(例如 PyTorch 分布式数据并行)在处理 14 亿参数模型时会耗尽内存,而 ZeRO-1 支持多达 60 亿参数进行比较。
此外,在没有模型并行的情况下,这些模型可以在低带宽集群上进行训练,同时仍能实现比使用模型并行性显著更好的吞吐量。例如,在连接有 40 Gbps Infiniband 互连的四节点集群上(每个节点有四个通过 PCI-E 连接的 NVIDIA 16GB V100 GPU),使用 ZeRO 驱动的数据并行性训练 GPT-2 模型比使用模型并行性快近 4 倍。因此,通过这种性能改进,大型模型训练不再局限于具有超高速互连的 GPU 集群,而是在具有有限带宽的普通集群上也可进行。