流水线并行
DeepSpeed v0.3 包含了对流水线并行的新支持!流水线并行通过将模型层划分为可以并行处理的阶段,从而提高了深度学习训练的内存和计算效率。DeepSpeed 的训练引擎提供了混合数据并行和流水线并行,并且可以与 Megatron-LM 等模型并行进一步结合。3D 并行的示意图如下所示。我们最新的结果表明,这种 3D 并行能够训练参数超过万亿的模型。
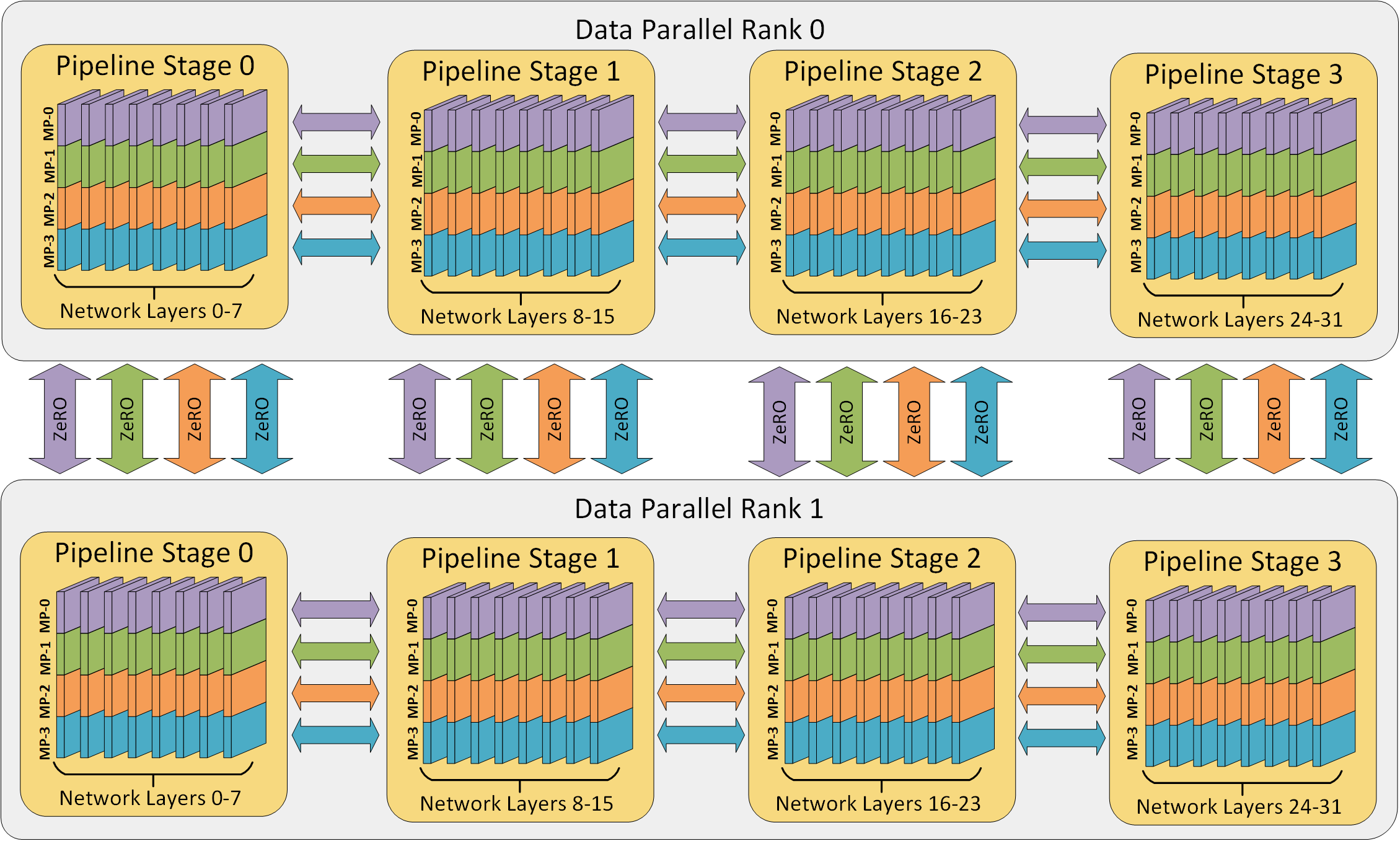
DeepSpeed 使用梯度累积来提取流水线并行(如下图所示)。每个训练数据批次被分成可以在流水线阶段并行处理的微批次。一旦某个阶段完成一个微批次的前向传播,激活内存就会传输到流水线中的下一个阶段。同样,当下个阶段完成一个微批次的后向传播时,相对于激活的梯度会通过流水线反向传输。每个后向传播都会在本地累积梯度。接下来,所有数据并行组并行执行梯度归约。最后,优化器更新模型权重。
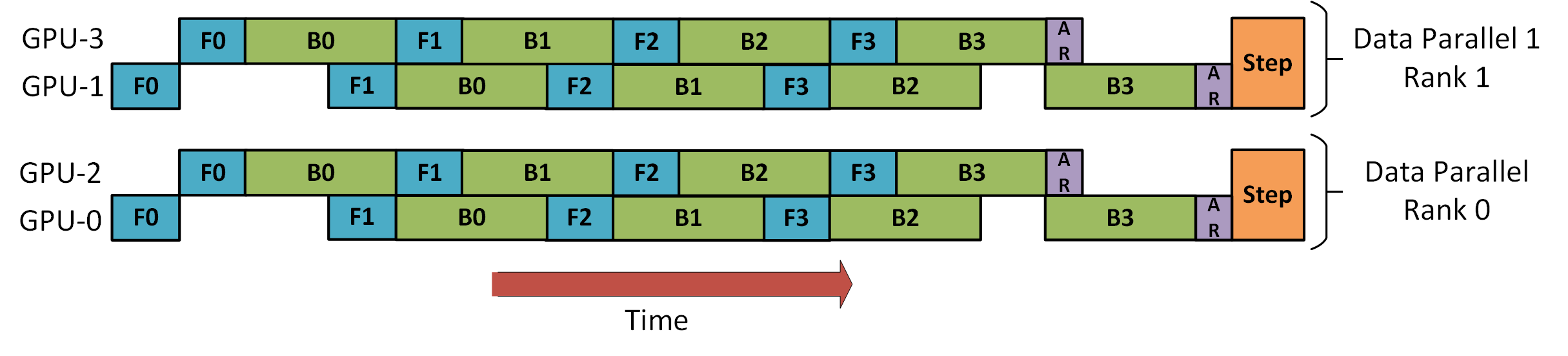
下图展示了 DeepSpeed 如何使用混合两路数据并行和两阶段流水线并行训练一个包含八个微批次的批次。GPU 0 和 2 以流水线方式排列,将交替进行前向(F)和后向(B)传播。然后,它们将分别与它们的数据并行对应方 GPU 1 和 3 进行梯度全归约(AR)。最后,两个流水线阶段更新它们的模型权重。
流水线并行入门
DeepSpeed 致力于加速并简化流水线并行训练的过程。本节通过准备 torchvision 的 AlexNet 模型,提供了混合数据并行和流水线并行训练的初步步骤。
表达流水线模型
流水线并行要求模型以层序列的形式表达。在前向传播中,每一层都消耗前一层的输出。事实上,流水线并行模型无需指定 forward() 方法!流水线并行模型的前向传播隐式地采取以下形式:
def forward(self, inputs):
x = inputs
for layer in self.layers:
x = layer(x)
return x
PyTorch 的 torch.nn.Sequential 是一个方便的容器,用于表达流水线并行模型,并且无需修改即可被 DeepSpeed 并行化。
net = nn.Sequential(
nn.Linear(in_features, hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, out_features)
)
from deepspeed.pipe import PipelineModule
net = PipelineModule(layers=net, num_stages=2)
PipelineModule 将其 layers 参数用作构成模型的层序列。初始化后,net 被分成两个流水线阶段,其层被移动到相应的 GPU。如果存在两个以上的 GPU,DeepSpeed 还会使用混合数据并行。
注意:GPU 的总数必须能被流水线阶段的数量整除。
注意:对于大型模型训练,请参阅内存高效模型构建。
AlexNet
让我们看看 torchvision 的 AlexNet 的简化实现。
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
...
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
...
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
AlexNet 主要由多个 Sequential 子模块组成。我们可以通过将其子模块扁平化为单个层序列,将其转换为 PipelineModule。
class AlexNetPipe(AlexNet):
def to_layers(self):
layers = [
*self.features,
self.avgpool,
lambda x: torch.flatten(x, 1),
*self.classifier
]
return layers
from deepspeed.pipe import PipelineModule
net = AlexNetPipe()
net = PipelineModule(layers=net.to_layers(), num_stages=2)
注意:上面 layers 中间的 lambda 不是 torch.nn.Module 类型。任何实现了 __call__() 的对象都可以成为 PipelineModule 中的一层:这使得在流水线中进行方便的数据转换成为可能。
输入和输出
遵循 torch.nn.Sequential,每一层的输入和输出必须是单个 torch.Tensor 或一个张量 tuple。实际上,某些模型可能需要修改其前向传播以打包和解包 forward() 的参数。考虑一个 Transformer 块堆栈的简化实现:
class TransformerBlock(nn.Module)
...
def forward(self, hidden, mask):
output = self.compute(hidden, mask)
return output
...
stack = [ TransformerBlock() for _ in range(num_layers) ]
需要对 TransformerBlock 进行两项修改:
- 参数必须收集到一个
tuple中。 mask也必须从forward()返回,以便传递给下一层。
这些修改可以通过一个简单的子类来实现:
class TransformerBlockPipe(TransformerBlock)
def forward(self, inputs):
hidden, mask = inputs
output = super().forward(hidden, mask)
return (output, mask)
stack = [ TransformerBlockPipe() for _ in range(num_layers) ]
训练循环
流水线并行交错进行前向和后向传播,因此训练循环不能被分成独立的 forward()、backward() 和 step() 阶段。相反,DeepSpeed 的流水线引擎提供了一个 train_batch() 方法,该方法会推动流水线引擎运行,直到消耗完下一个训练数据批次并更新模型权重。
train_iter = iter(train_loader)
loss = engine.train_batch(data_iter=train_iter)
上述 train_batch() 示例等同于使用传统数据并行 DeepSpeed 的以下代码:
train_iter = iter(train_loader)
for micro_batch in engine.gradient_accumulation_steps():
batch = next(data_iter)
loss = engine(batch)
engine.backward(loss)
engine.step()
处理数据
数据并行训练通常在每个批次开始时由每个工作进程独立执行 I/O。然而,在流水线并行环境中,只有第一阶段使用输入数据,而只有最后一阶段使用标签进行损失计算。
注意:流水线引擎期望数据加载器返回一个包含两个元素的 tuple。第一个返回的元素是输入批次数据,第二个元素是用于损失计算的数据。如前所述,输入和标签应为 torch.Tensor 类型或张量 tuple。
为了方便起见,当数据集提供给 deepspeed.initialize() 时,DeepSpeed 流水线引擎可以构建一个分布式数据加载器。DeepSpeed 处理数据加载的其余复杂性,因此流水线训练循环变为:
engine, _, _, _ = deepspeed.initialize(
args=args,
model=net,
model_parameters=[p for p in net.parameters() if p.requires_grad],
training_data=cifar_trainset())
for step in range(args.steps):
loss = engine.train_batch()
当然,DeepSpeed 将与您希望使用的任何数据加载器配合使用。数据加载器应由流水线中的第一阶段和最后阶段构建。每个工作进程应加载大小为 engine.train_micro_batch_size_per_gpu() 的微批次,并且每个 train_batch() 调用总共会被查询 engine.gradient_accumulation_steps() 次。
注意!流水线引擎从迭代器中拉取数据,而不是对其进行迭代。关键是数据流不能在训练批次中间耗尽。每次调用 train_batch() 都将从数据迭代器中拉取总计 engine.gradient_accumulation_steps() 个微批次的数据。
DeepSpeed 提供了一个便利类 deepspeed.utils.RepeatingLoader,它只是简单地封装了一个可迭代对象(如数据加载器),并在达到末尾时重新启动它。
train_loader = deepspeed.utils.RepeatingLoader(train_loader)
train_iter = iter(train_loader)
for step in range(args.steps):
loss = engine.train_batch(data_iter=train_iter)
高级主题
流水线模块负载均衡
流水线并行训练的性能强烈依赖于负载均衡。DeepSpeed 提供了几种机制来在 GPU 之间划分模型。这些策略可以通过 PipelineModule 的 partition_method 关键字参数进行设置。以下是 DeepSpeed 当前提供的划分方法:
partition_method="parameters"(默认) 平衡每个流水线阶段可训练参数的数量。这在内存受限的环境中以及当层的大小与计算时间成比例时特别有用。partition_method="type:[regex]"平衡其类名匹配[regex]的层。正则表达式不区分大小写。例如,partition_method="type:transformer"将平衡每个阶段的 Transformer 层数量。partition_method="uniform"平衡每个阶段的层数量。
内存高效模型构建
构建 Sequential 容器并将其提供给 PipelineModule 是一种方便的指定流水线并行模型的方法。然而,这种方法对于大型模型会遇到可伸缩性问题,因为每个工作进程都会在 CPU 内存中复制整个模型。例如,一台拥有 16 个 GPU 的机器必须拥有相当于模型大小 16 倍的本地 CPU 内存。
DeepSpeed 提供了一个 LayerSpec 类,它将模块的构建延迟到模型层已在工作进程之间划分之后。然后,每个工作进程将只分配它被分配到的层。因此,与上一段的示例相比,使用 LayerSpec,一台拥有 16 个 GPU 的机器在其 CPU 内存中只需要分配总计 1 倍模型大小,而不是 16 倍。
下面是简化版 AlexNet 模型的一个示例,但仅使用 LayerSpecs 来表达。请注意,语法几乎没有变化:nn.ReLU(inplace=True) 简单地变成了 LayerSpec(nn.ReLU, inplace=True)。
from deepspeed.pipe import PipelineModule, LayerSpec
class AlexNetPipe(PipelineModule):
def __init__(self, num_classes=10, **kwargs):
self.num_classes = num_classes
specs = [
LayerSpec(nn.Conv2d, 3, 64, kernel_size=11, stride=4, padding=2),
LayerSpec(nn.ReLU, inplace=True),
...
LayerSpec(nn.ReLU, inplace=True),
LayerSpec(nn.Linear, 4096, self.num_classes),
]
super().__init__(layers=specs, loss_fn=nn.CrossEntropyLoss(), **kwargs)
共享层
某些模型不能完全表达为流水线并行模型,因为流水线中会重用某些层。例如,基于 Transformer 的语言模型通常在流水线早期使用嵌入层将词汇映射到隐藏状态,然后利用该嵌入在流水线末尾将隐藏状态映射回词汇。如果模型仅限于纯流水线并行,这种嵌入重用将阻止流水线并行。
DeepSpeed 提供了一个 TiedLayerSpec 类,它是 LayerSpec 的扩展。TiedLayerSpec 需要一个额外的参数:key。层的每次重用都通过 TiedLayerSpec 指定,并且 key 字段用于识别层被重用的位置。
共享层会在拥有重用实例的每个流水线阶段上进行复制。训练照常进行,但在所有反向传播完成后,会额外添加一个共享梯度全归约操作。全归约操作确保共享层的权重在所有流水线阶段之间保持同步。