DeepSpeed 稀疏注意力
本教程将介绍如何使用 DeepSpeed 稀疏注意力 (SA) 及其构建块内核。使用 SA 最简单的方法是通过 DeepSpeed 启动器。我们将在如何在 DeepSpeed 启动器中使用稀疏注意力一节中通过一个例子进行描述。但在此之前,我们先在下一节介绍 DeepSpeed SA 提供的模块。
注意:目前,DeepSpeed 稀疏注意力只能在 NVIDIA V100 或 A100 GPU 上使用,且需 Torch >= 1.6 和 CUDA 10.1、10.2、11.0 或 11.1。
稀疏注意力模块
- MatMul:此模块处理块稀疏矩阵-矩阵乘法。目前它支持DeepSpeed 稀疏注意力部分中描述的 SDD、DSD 和 DDS。
- Softmax:此模块应用块稀疏 softmax。它处理前向和后向传播。
- SparseSelfAttention:此模块使用 MatMul 和 Softmax 内核,并根据 Query、Keys 和 Values 生成 Context 层输出。它是任何自注意力层中常见操作的简化版本。它还可以应用
相对位置嵌入注意力掩码Key padding mask应用于中间注意力分数。有关自注意力的更多详细信息,请查看MultiHeadAttention。
- BertSparseSelfAttention:此模块包含一个简化的 BertSelfAttention 层,可用于替代原始的密集 Bert 自注意力层。我们的实现基于DeepSpeedExample。
- SparseAttentionUtils:此模块提供了一些实用函数,用于处理预训练模型与稀疏注意力的适配
replace_model_self_attention_with_sparse_self_attention:如果您当前已加载模型并想用稀疏自注意力替换自注意力模块,您可以直接使用此函数为您处理。它目前处理基于 BERT 和 RoBERTa 的预训练模型,但如果您的模型类型不同于这两种,您可以根据您的模型类型进行扩展。您还需要扩展位置嵌入以处理新的序列长度;这可以通过extend_position_embedding函数完成。update_tokenizer_model_max_length:此函数简单地使用新值更新您的分词器中的最大位置嵌入。extend_position_embedding:此函数根据当前值扩展位置嵌入。例如,如果您有一个最大序列长度为 128 的模型并将其扩展到 1k 序列长度,它会将当前嵌入复制 8 次以初始化新的嵌入。实验表明,这种初始化方式比从头开始初始化效果更好;可以更快地收敛。pad_to_block_size:此函数在序列长度维度上填充输入 token 和注意力掩码,使其成为块大小的倍数;这是 SA 的要求。unpad_sequence_output:如果模型输入已填充,此函数将取消填充序列输出。
- SparsityConfig:这是一个稀疏性结构的抽象类。任何稀疏性结构都需要扩展此类别并编写自己的稀疏模式构建;即
make_layout函数。DeepSpeed 目前提供以下结构,将在如何配置稀疏结构一节中进行描述FixedSparsityConfigBSLongformerSparsityConfigBigBirdSparsityConfigVariableSparsityConfigDenseSparsityConfig
注意:目前 DeepSpeed Transformer Kernels 不支持稀疏注意力。要使用稀疏注意力,您需要禁用 Transformer Kernels!
如何在 DeepSpeed 启动器中使用稀疏注意力
在本节中,我们将描述如何通过我们的 bing_bert 代码使用 DeepSpeed 稀疏注意力。
- 更新注意力模块:首先,您需要根据稀疏计算更新您的注意力模块。这里,我们使用BertSparseSelfAttention,它是我们bing_bert代码中
BertSelfAttention的稀疏版本。它重写了BertSelfAttention,其中它替换了
attention_scores = torch.matmul(query_layer, key_layer)
attention_scores = attention_scores / math.sqrt(
self.attention_head_size)
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
pdtype = attention_scores.dtype
# Normalize the attention scores to probabilities.
attention_probs = self.softmax(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)
用
context_layer =
self.sparse_self_attention(
query_layer,
key_layer,
value_layer,
key_padding_mask=attention_mask)
其中sparse_self_attention是SparseSelfAttention的一个实例。该模块通过稀疏注意力计算注意力上下文,将底层的矩阵乘法和 softmax 替换为等效的稀疏版本。您可以类似地更新任何其他注意力模块。
- 在模型中设置稀疏注意力配置:您需要设置稀疏注意力配置。在我们的示例中,这是在
BertModel中完成的。
self.pad_token_id = config.pad_token_id if hasattr(
config, 'pad_token_id') and config.pad_token_id is not None else 0
# set sparse_attention_config if it has been selected
self.sparse_attention_config = get_sparse_attention_config(
args, config.num_attention_heads)
self.encoder = BertEncoder(
config, args, sparse_attention_config=self.sparse_attention_config)
- 更新编码器模型:此外,当启用 SA 时,您需要更新您的编码器模型以在注意力层中使用 SA。请查看我们的bing_bert 示例,其中当 SA 启用时,我们使用
BertSparseSelfAttention而不是BertSelfAttention。
if sparse_attention_config is not None:
from deepspeed.ops.sparse_attention import BertSparseSelfAttention
layer.attention.self = BertSparseSelfAttention(
config, sparsity_config=sparse_attention_config)
- 填充和取消填充输入数据:您可能还需要填充
input_ids和attention_mask的序列维度,使其成为稀疏块大小的倍数。如上文模块部分所述,DeepSpeed 提供了用于填充和取消填充的实用函数。请查看我们的bing_bert 示例,了解如何填充和取消填充模型的输入或输出。
if self.sparse_attention_config is not None:
pad_len, input_ids, attention_mask, token_type_ids, position_ids, inputs_embeds = SparseAttentionUtils.pad_to_block_size(
block_size=self.sparse_attention_config.block,
input_ids=input_ids,
attention_mask=extended_attention_mask,
token_type_ids=token_type_ids,
position_ids=None,
inputs_embeds=None,
pad_token_id=self.pad_token_id,
model_embeddings=self.embeddings)
.
.
.
# If BertEncoder uses sparse attention, and input_ids were padded, sequence output needs to be unpadded to original length
if self.sparse_attention_config is not None and pad_len > 0:
encoded_layers[-1] = SparseAttentionUtils.unpad_sequence_output(
pad_len, encoded_layers[-1])
- *启用稀疏注意力:要使用 DeepSpeed 稀疏注意力,您需要在启动脚本中通过
deepspeed_sparse_attention参数启用它
--deepspeed_sparse_attention
请查看我们的 bing_bert 运行脚本,作为如何在 DeepSpeed 启动器中启用 SA 的示例。
- 添加稀疏性配置:稀疏性配置可以通过DeepSpeed JSON 配置文件进行设置。在此示例中,我们使用了
fixed稀疏模式,该模式将在如何配置稀疏结构一节中进行描述。
"sparse_attention": {
"mode": "fixed",
"block": 16,
"different_layout_per_head": true,
"num_local_blocks": 4,
"num_global_blocks": 1,
"attention": "bidirectional",
"horizontal_global_attention": false,
"num_different_global_patterns": 4
}
如何使用单个内核
DeepSpeed 稀疏注意力可以作为 DeepSpeed 的一个功能使用,如上所述,也可以简单地作为自注意力模块单独集成到任何 Transformer 模型中。此外,构建块内核,即矩阵乘法和 softmax 可以单独使用。要单独使用稀疏注意力,您只需安装 DeepSpeed 并导入模块部分中描述的任何模块;例如
from deepspeed.ops.sparse_attention import SparseSelfAttention
请参阅 Docstrings 以了解如何单独使用每个模块的详细信息。
如何配置稀疏结构
接下来我们描述支持的稀疏结构、它们的参数集以及在自注意力层上添加任意稀疏模式的灵活性。您可以使用任何支持的稀疏结构更新 DeepSpeed 配置文件并相应地设置参数。
- SparsityConfig:此模块是所有稀疏性结构的父类,并包含所有稀疏性结构的共享特性。它接受以下参数
num_heads:一个整数,表示层的注意力头数量。block:一个整数,表示块大小。当前稀疏自注意力实现基于块稀疏矩阵。此参数定义了此类方块的大小;Block X Block。different_layout_per_head:一个布尔值,确定每个头是否应分配不同的稀疏布局;默认为 false,这将根据可用性满足。
- Fixed (FixedSparsityConfig):此结构基于 OpenAI 的《Generative Modeling with Sparse Transformers》,其中局部和全局注意力由给定参数固定
num_local_blocks:一个整数,表示局部注意力窗口中的块数量。如下图所示(改编自原始论文),局部窗口中的 token 会关注它们局部内的所有 token。在自回归模型的情况下,如图所示,token 会关注它们在局部窗口中之前出现的 token。而在 Masked 模型(如 BERT)的情况下,注意力是双向的。num_global_blocks:一个整数,表示局部窗口中有多少个连续的块被用作全局注意力的窗口代表;如下图所示。attention:一个字符串,表示注意力类型。注意力可以是unidirectional(单向),例如自回归模型,其中 token 只关注上下文中它们之前出现的 token。考虑到这一点,注意力矩阵的上三角部分是空的,如上图所示。或者可以是bidirectional(双向),例如 BERT,其中 token 可以关注它们之前或之后出现的任何其他 token。那么,注意力矩阵的上三角部分是下图下三角部分的镜像。horizontal_global_attention:一个布尔值,确定作为局部窗口的全局代表的块是否也关注所有其他块。这仅在注意力类型为bidirectional时有效。从注意力矩阵来看,这意味着全局注意力不仅包括垂直块,还包括水平块。num_different_global_patterns:一个整数,表示不同全局注意力布局的数量。虽然全局注意力可以通过哪些块代表任何局部窗口来固定,但由于有多个头,每个头可以使用不同的全局代表。例如,对于由 4 个块构成局部窗口且全局注意力大小为单个块的情况,我们可以有 4 种不同版本,其中每个局部窗口的第一个、第二个、第三个或第四个块可以作为该窗口的全局代表。此参数确定我们想要多少种这样的模式。当然,这受到num_local_blocks和num_global_blocks的限制。此外,如果将其设置为大于 1,则需要将different_layout_per_head设置为True。
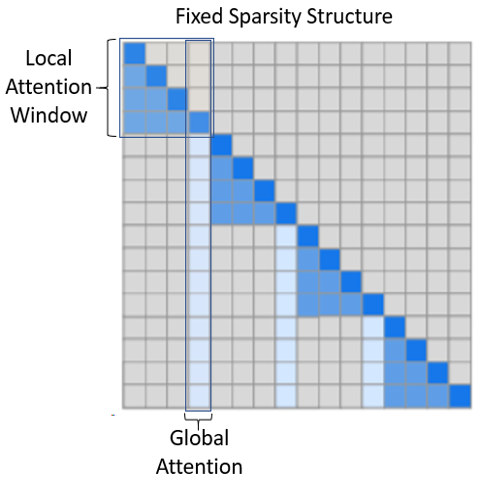
- BSLongformer (BSLongformerSparsityConfig):此结构是Longformer: The Long-Document Transformer的修改版本,其中我们提供的是块状 token 稀疏性,而非单个 token 稀疏性。定义此模式的参数有
num_sliding_window_blocks:一个整数,表示滑动局部注意力窗口中的块数量。global_block_indices:一个整数列表,确定哪些块被视为全局注意力。给定索引,确定所有其他 token 块都关注的块,并且它们也关注所有其他 token 块。请注意,如果设置了global_block_end_indices参数,则此参数用作每个全局窗口的起始索引。global_block_end_indices:一个整数列表,表示全局窗口块的结束索引。默认情况下不使用此参数。但如果设置了,它必须与global_block_indices参数大小相同,并且结合这两个参数,对于每个索引i,从global_block_indices[i]到global_block_end_indices[i](不包括)的块都被视为全局注意力块。
- BigBird (BigBirdSparsityConfig):此结构基于《Big Bird: Transformers for Longer Sequences》。它以某种方式结合了
fixed和longformer模式以及随机注意力的思想。以下参数定义了此结构num_random_blocks:一个整数,表示每行块中随机关注的块的数量。num_sliding_window_blocks:一个整数,表示滑动局部注意力窗口中的块数量。num_global_blocks:一个整数,表示从索引 0 开始,有多少个连续的块被视为全局注意力。全局块 token 将被所有其他块 token 关注,并且也将关注所有其他块 token。
- Variable (VariableSparsityConfig):此结构也结合了局部、全局和随机注意力的思想。此外,它还具有定义可变大小局部窗口的灵活性。以下是定义此结构的参数列表
num_random_blocks:一个整数,表示每行块中随机关注的块的数量。local_window_blocks:一个整数列表,用于确定每个局部注意力窗口中的块数量。它假定第一个数字确定第一个局部窗口中的块数量,第二个数字确定第二个窗口中的块数量,依此类推,最后一个数字确定剩余局部窗口中的块数量。global_block_indices:一个整数列表,确定哪些块被视为全局注意力。给定索引,确定所有其他 token 块都关注的块,并且它们也关注所有其他 token 块。请注意,如果设置了global_block_end_indices参数,则此参数用作每个全局窗口的起始索引。global_block_end_indices:一个整数列表,表示全局窗口块的结束索引。默认情况下不使用此参数。但如果设置了,它必须与global_block_indices参数大小相同,并且结合这两个参数,对于每个索引i,从global_block_indices[i]到global_block_end_indices[i](不包括)的块都被视为全局注意力块。attention:一个字符串,表示注意力类型。注意力可以是unidirectional(单向),例如自回归模型,其中 token 只关注上下文中它们之前出现的 token。考虑到这一点,注意力矩阵的上三角部分是空的,如上图所示。或者可以是bidirectional(双向),例如 BERT,其中 token 可以关注它们之前或之后出现的任何其他 token。那么,注意力矩阵的上三角部分是下图下三角部分的镜像。horizontal_global_attention:一个布尔值,确定作为局部窗口全局代表的块是否也关注所有其他块。这仅在注意力类型为bidirectional时有效。从注意力矩阵来看,这意味着全局注意力不仅包括垂直块,还包括水平块。下图展示了variable稀疏性的一个例子,其中蓝色、橙色和绿色块分别表示局部、全局和随机注意力块。
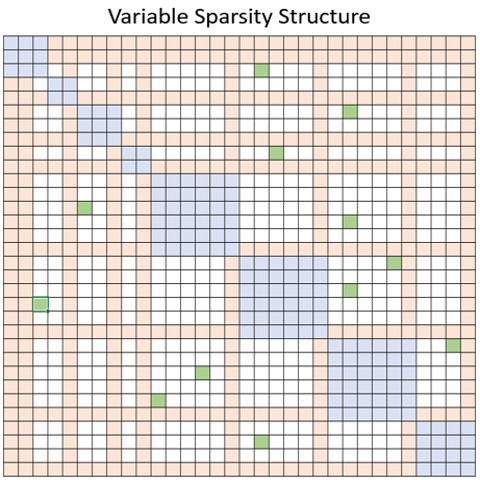
此外,我们提供了一个dense模式(DenseSparsityConfig),可用于测试,同时它代表了完整的注意力。
如何支持新的用户定义稀疏结构
我们的构建块内核,即基于块的MatMul和Softmax,可以接受任何基于块的稀疏性。这提供了将任何基于块的稀疏模式应用于注意力分数的灵活性。要定义和应用新的稀疏模式,您只需遵循上述任何稀疏结构即可。您需要添加一个新类来扩展SparsityConfig,并根据稀疏模式的结构定义make_layout函数。您可以添加任何您可能需要的额外参数,或者只使用父类的默认参数。