BERT 预训练
注意: 2022 年 8 月 15 日,我们添加了另一个 BERT 预训练/微调示例,地址为 github.com/deepspeedai/Megatron-DeepSpeed/tree/main/examples_deepspeed/bert_with_pile,其中包含一个描述如何使用的 README.md 文件。与下述示例相比,Megatron-DeepSpeed 中的新示例增加了对 ZeRO 和张量切片模型并行(从而支持更大的模型规模)的支持,使用了公共且更丰富的 Pile 数据集(用户也可以使用自己的数据),并根据 这篇论文 对模型架构和训练超参数进行了一些更改。因此,通过新示例训练的 BERT 模型能够提供比原始 BERT 更好的 MNLI 结果,但模型架构略有不同,计算要求也更高。如果您想训练更大规模或更高质量的 BERT 风格模型,我们建议遵循 Megatron-DeepSpeed 中的新示例。如果您的目标是严格复现原始 BERT 模型,我们建议遵循 DeepSpeedExamples/bing_bert 下的示例(如下所述)。另一方面,无论您使用哪个 BERT 示例,下面的教程都将有助于解释如何将 DeepSpeed 集成到预训练代码库中。
在本教程中,我们将应用 DeepSpeed 来预训练 BERT(来自 Transformer 的双向编码器表示),该模型广泛用于许多自然语言处理 (NLP) 任务。BERT 的详细信息可在此处找到:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding。
我们将介绍如何设置数据管道以及如何运行原始 BERT 模型。然后我们将逐步展示如何修改模型以利用 DeepSpeed。最后,我们将演示使用 DeepSpeed 带来的性能评估和内存使用量减少。
不使用 DeepSpeed 预训练 Bing BERT
我们基于 huggingface/transformers 和 NVIDIA/DeepLearningExamples 的改编版本。我们已将此仓库 Fork 到 DeepSpeedExamples/bing_bert 下,并对其脚本进行了一些修改。
- 我们采用了 NVIDIA BERT 在
bing_bert/nvidia/下的模型代码。 - 我们扩展了 Project Turing 在
bing_bert/turing/下的数据管道。
训练数据设置
注意: 下载和预处理说明即将发布。
下载 Wikipedia 和 BookCorpus 数据集,并在模型配置文件 DeepSpeedExamples/bing_bert/bert_large_adam_seq128.json 中指定它们的路径。
{
...
"datasets": {
"wiki_pretrain_dataset": "/data/bert/bnorick_format/128/wiki_pretrain",
"bc_pretrain_dataset": "/data/bert/bnorick_format/128/bookcorpus_pretrain"
},
...
}
运行 Bing BERT 模型
在 DeepSpeedExamples/bing_bert 目录下,运行
python train.py \
--cf bert_large_adam_seq128.json \
--train_batch_size 64 \
--max_seq_length 128 \
--gradient_accumulation_steps 1 \
--max_grad_norm 1.0 \
--fp16 \
--loss_scale 0 \
--delay_allreduce \
--max_steps 10 \
--output_dir <path-to-model-output>
启用 DeepSpeed
要使用 DeepSpeed,我们需要编辑两个文件:
train.py:训练的主要入口点utils.py:训练参数和检查点保存/加载实用程序
参数解析
我们首先需要使用 deepspeed.add_config_arguments() 将 DeepSpeed 的参数解析添加到 train.py。此步骤允许应用程序识别 DeepSpeed 特定的配置。
def get_arguments():
parser = get_argument_parser()
# Include DeepSpeed configuration arguments
parser = deepspeed.add_config_arguments(parser)
args = parser.parse_args()
return args
初始化与训练
我们修改 train.py 以启用 DeepSpeed 训练。
初始化
我们使用 deepspeed.initialize() 创建模型、优化器和学习率调度器。对于 Bing BERT 模型,我们如下所示在其 prepare_model_optimizer() 函数中初始化 DeepSpeed,以传递原始模型和优化器(通过命令选项指定)。
def prepare_model_optimizer(args):
# Loading Model
model = BertMultiTask(args)
# Optimizer parameters
optimizer_parameters = prepare_optimizer_parameters(args, model)
model.network, optimizer, _, _ = deepspeed.initialize(args=args,
model=model.network,
model_parameters=optimizer_parameters,
dist_init_required=False)
return model, optimizer
请注意,对于 Bing BERT,原始模型保存在 model.network 中,因此我们传递 model.network 作为参数,而不是仅仅传递 model。
训练
deepspeed.initialize 返回的 model 是 DeepSpeed 模型引擎,我们将使用它通过 forward、backward 和 step API 训练模型。由于模型引擎暴露了与 nn.Module 对象相同的正向传播 API,因此正向传播没有变化。因此,我们只修改反向传播和优化器/调度器步骤。
反向传播通过直接调用模型引擎的 backward(loss) 来执行。
# Compute loss
if args.deepspeed:
model.network.backward(loss)
else:
if args.fp16:
optimizer.backward(loss)
else:
loss.backward()
DeepSpeed 引擎中的 step() 函数更新模型参数和学习率。在每次步骤后更新权重后,DeepSpeed 会自动处理梯度归零。
if args.deepspeed:
model.network.step()
else:
optimizer.step()
optimizer.zero_grad()
检查点保存与加载
DeepSpeed 的模型引擎具有灵活的 API,用于检查点保存和加载,以处理客户端模型状态及其内部状态。
def save_checkpoint(self, save_dir, tag, client_state={})
def load_checkpoint(self, load_dir, tag)
在 train.py 中,我们如下所示在 checkpoint_model() 函数中使用 DeepSpeed 的检查点 API,我们在其中收集客户端模型状态并通过调用 save_checkpoint() 将它们传递给模型引擎。
def checkpoint_model(PATH, ckpt_id, model, epoch, last_global_step, last_global_data_samples, **kwargs):
"""Utility function for checkpointing model + optimizer dictionaries
The main purpose for this is to be able to resume training from that instant again
"""
checkpoint_state_dict = {'epoch': epoch,
'last_global_step': last_global_step,
'last_global_data_samples': last_global_data_samples}
# Add extra kwargs too
checkpoint_state_dict.update(kwargs)
success = model.network.save_checkpoint(PATH, ckpt_id, checkpoint_state_dict)
return
在 load_training_checkpoint() 函数中,我们使用 DeepSpeed 的加载检查点 API 并返回客户端模型的状态。
def load_training_checkpoint(args, model, PATH, ckpt_id):
"""Utility function for checkpointing model + optimizer dictionaries
The main purpose for this is to be able to resume training from that instant again
"""
_, checkpoint_state_dict = model.network.load_checkpoint(PATH, ckpt_id)
epoch = checkpoint_state_dict['epoch']
last_global_step = checkpoint_state_dict['last_global_step']
last_global_data_samples = checkpoint_state_dict['last_global_data_samples']
del checkpoint_state_dict
return (epoch, last_global_step, last_global_data_samples)
DeepSpeed JSON 配置文件
使用 DeepSpeed 的最后一步是创建一个配置文件 JSON 文件(例如,deepspeed_bsz4096_adam_config.json)。此文件提供用户定义的 DeepSpeed 特定参数,例如每个 GPU 的批次大小、优化器及其参数,以及是否启用 FP16 训练。
{
"train_batch_size": 4096,
"train_micro_batch_size_per_gpu": 64,
"steps_per_print": 1000,
"optimizer": {
"type": "Adam",
"params": {
"lr": 2e-4,
"max_grad_norm": 1.0,
"weight_decay": 0.01,
"bias_correction": false
}
},
"fp16": {
"enabled": true,
"loss_scale": 0,
"initial_scale_power": 16
}
}
特别是,这个示例 json 文件为 DeepSpeed 指定了以下配置参数:
train_batch_size:使用有效批次大小 4096train_micro_batch_size_per_gpu:每个 GPU 有足够的内存瞬间容纳批次大小 64optimizer:使用 Adam 训练优化器fp16:启用 FP16 混合精度训练,初始损失比例因子为 2^16。
就是这样!这是您为了使用 DeepSpeed 而需要做的所有修改。我们已经包含了一个名为 DeepSpeedExamples/bing_bert/deepspeed_train.py 的修改过的 train.py 文件,其中包含了所有更改。
启用 DeepSpeed 的 Transformer Kernel
为了实现更高的性能,首先在 utils.py 中添加一个参数 --deepspeed_transformer_kernel,我们可以将其默认设置为 False,以便于开启/关闭。
parser.add_argument('--deepspeed_transformer_kernel',
default=False,
action='store_true',
help='Use DeepSpeed transformer kernel to accelerate.')
然后在建模源文件的 BertEncoder 类中,如下所示使用 DeepSpeed Transformer Kernel 实例化 Transformer 层。
if args.deepspeed_transformer_kernel:
from deepspeed import DeepSpeedTransformerLayer, DeepSpeedTransformerConfig, DeepSpeedConfig
if hasattr(args, 'deepspeed_config') and args.deepspeed_config:
ds_config = DeepSpeedConfig(args.deepspeed_config)
else:
raise RuntimeError('deepspeed_config is not found in args.')
cuda_config = DeepSpeedTransformerConfig(
batch_size = ds_config.train_micro_batch_size_per_gpu,
max_seq_length = args.max_seq_length,
hidden_size = config.hidden_size,
heads = config.num_attention_heads,
attn_dropout_ratio = config.attention_probs_dropout_prob,
hidden_dropout_ratio = config.hidden_dropout_prob,
num_hidden_layers = config.num_hidden_layers,
initializer_range = config.initializer_range,
local_rank = args.local_rank if hasattr(args, 'local_rank') else -1,
seed = args.seed,
fp16 = ds_config.fp16_enabled,
pre_layer_norm=True,
attn_dropout_checkpoint=args.attention_dropout_checkpoint,
normalize_invertible=args.normalize_invertible,
gelu_checkpoint=args.gelu_checkpoint,
stochastic_mode=True)
layer = DeepSpeedTransformerLayer(cuda_config)
else:
layer = BertLayer(config)
self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(config.num_hidden_layers)])
所有配置设置都来自 DeepSpeed 配置文件和命令行参数,因此我们必须将 args 变量传递到此模型中。
注意
batch_size是输入数据的最大批次大小,所有微调训练数据或预测数据都不应超过此阈值,否则将抛出异常。在 DeepSpeed 配置文件中,微批次大小定义为train_micro_batch_size_per_gpu,例如,如果它设置为 8 且预测使用批次大小 12,我们可以使用 12 作为 transformer kernel 批次大小,或者使用 “–predict_batch_size” 参数将预测批次大小设置为 8 或更小的数字。- DeepSpeedTransformerConfig 中的
local_rank用于将 transformer kernel 分配给正确的设备。由于模型在此之前已经运行了 set_device(),因此无需在此处设置。 stochastic_mode在启用时性能更高,我们在预训练中启用它,在微调中禁用它。- Transformer Kernel 有其自己的参数,因此使用 Transformer Kernel 生成的检查点文件必须由启用了 Transformer Kernel 的模型加载(例如在微调中)。
有关 Transformer Kernel 的更多详细信息,请参阅DeepSpeed Transformer Kernel 和 DeepSpeed Fastest-Bert Training。
开始训练
在一个包含四个节点、每个节点带四个 GPU 的系统上启动 deepspeed_train.py 的示例如下:
deepspeed --num_nodes 4 \
deepspeed_train.py \
--deepspeed \
--deepspeed_config deepspeed_bsz4096_adam_config.json \
--cf /path-to-deepspeed/examples/tests/bing_bert/bert_large_adam_seq128.json \
--train_batch_size 4096 \
--max_seq_length 128 \
--gradient_accumulation_steps 4 \
--max_grad_norm 1.0 \
--fp16 \
--loss_scale 0 \
--delay_allreduce \
--max_steps 32 \
--print_steps 1 \
--deepspeed_transformer_kernel \
--output_dir <output_directory>
有关启动 DeepSpeed 的更多信息,请参阅入门指南。
使用 DeepSpeed 复现最快 BERT 训练结果
我们在 BERT 训练时间方面达到了最快,同时在 SQUAD 1.1 开发集上取得了 90.5 或更高 F1 分数的行业竞争力。请遵循 BERT 微调教程,对您通过 transformer kernel 预训练的模型进行微调,并复现 SQUAD F1 分数。
- 我们使用 1024 块 V100 GPU(64 个 NVIDIA DGX-2 节点)在 44 分钟内完成了 BERT 预训练。相比之下,NVIDIA 此前的 SOTA 使用 1472 块 V100 GPU 耗时 47 分钟。DeepSpeed 不仅更快,而且资源使用量减少了 30%。使用相同的 1024 块 GPU,NVIDIA BERT 比 DeepSpeed 慢 52%,训练耗时 67 分钟。
- 与 Google 原始 BERT 训练时间相比,它在 64 个 TPU2 芯片上耗时约 96 小时才达到同等水平,而我们在 4 个 DGX-2 节点(64 个 V100 GPU)上训练不到 9 小时。
- 在 256 块 GPU 上,我们耗时 2.4 小时,比 NVIDIA 在相同数量 GPU(链接)上使用其 superpod 达到的 SOTA 结果(3.9 小时)更快。
| 节点数 | V100 GPU 数量 | 时间 |
|---|---|---|
| 1 DGX-2 | 16 | 33 小时 13 分钟 |
| 4 DGX-2 | 64 | 8 小时 41 分钟 |
| 16 DGX-2 | 256 | 144 分钟 |
| 64 DGX-2 | 1024 | 44 分钟 |
我们上面 BERT 训练结果的配置可以通过 DeepSpeedExamples 仓库中的脚本/json 配置文件复现。下表总结了配置。具体请参阅 DeepSpeedExamples 中 ds_train_bert_bsz64k_seq128.sh 和 ds_train_bert_bsz32k_seq512.sh 脚本以获取更多详细信息。
| 参数 | 128 序列 | 512 序列 |
|---|---|---|
| 总批次大小 | 64K | 32K |
| 每个 GPU 的训练微批次大小 | 64 | 8 |
| 优化器 | Lamb | Lamb |
| 学习率 | 11e-3 | 2e-3 |
初始学习率 (lr_offset) |
10e-4 | 0.0 |
| 最小 Lamb 系数 | 0.01 | 0.01 |
| 最大 Lamb 系数 | 0.3 | 0.3 |
| 学习率调度器 | warmup_exp_decay_exp |
warmup_exp_decay_exp |
| 热身比例 | 0.02 | 0.02 |
| 衰减率 | 0.90 | 0.90 |
| 衰减步数 | 250 | 150 |
| 最大训练步数 | 7500 | 7500 |
| 重新热身学习率 | 不适用 | 是 |
| 输出检查点编号 | 150 | 160-162 |
| 样本数 | 4.03 亿 | 1800 万-2200 万 |
| 纪元数 | 150 | 160-162 |
DeepSpeed 单 GPU 吞吐量结果
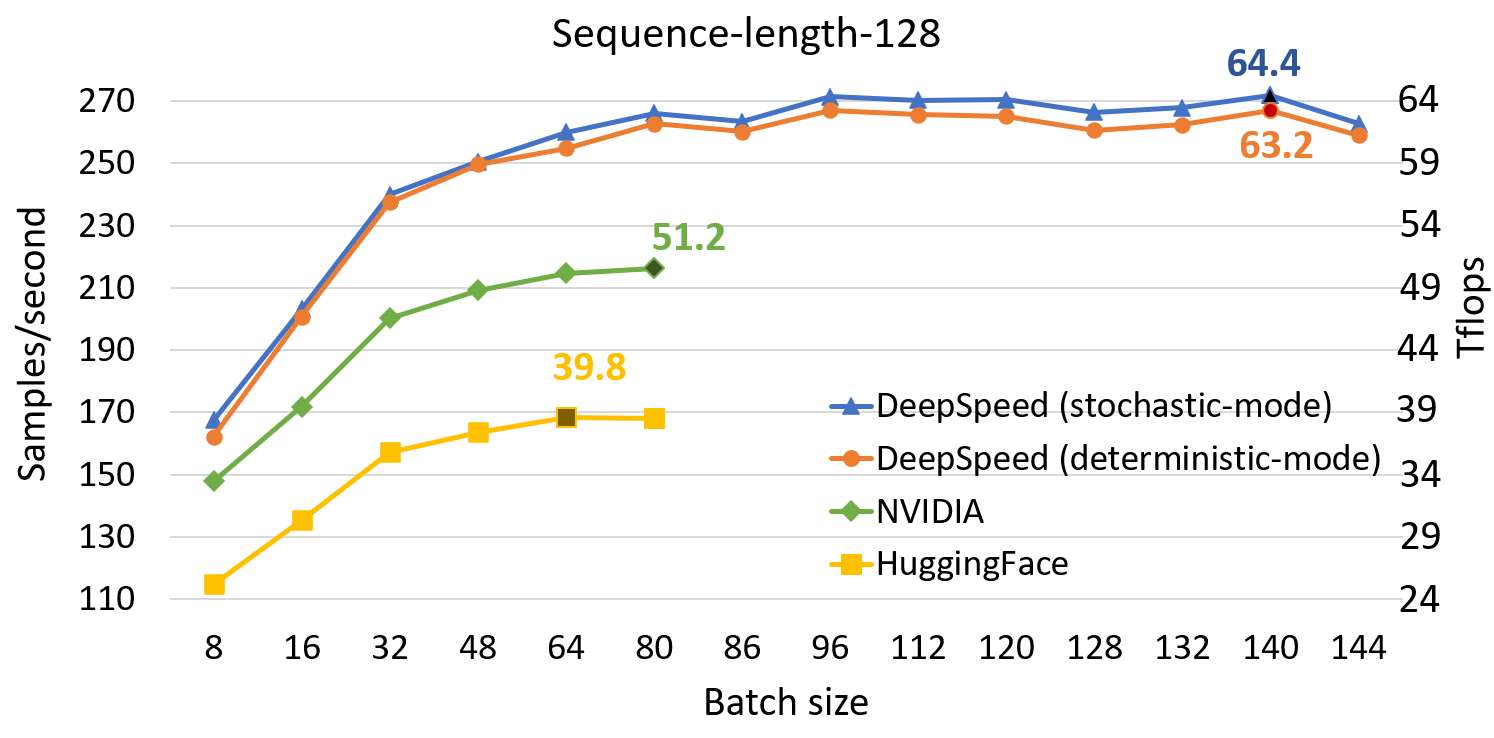
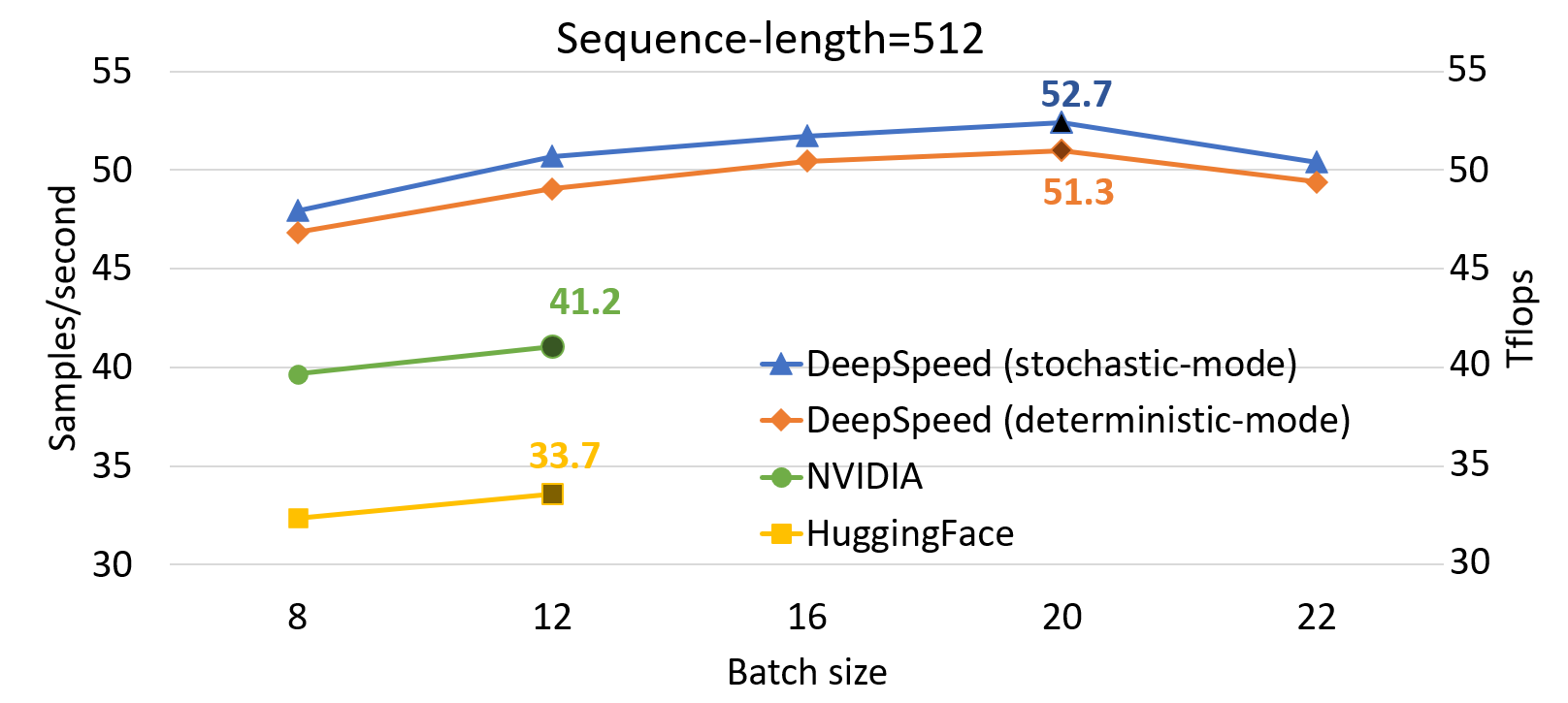
与 SOTA 相比,DeepSpeed 显著提升了基于 Transformer 的模型(如 BERT)的单 GPU 性能。上图显示了通过 DeepSpeed 优化的 BertBERT-Large 训练的单 GPU 吞吐量,与两个著名的 PyTorch 实现(NVIDIA BERT 和 HuggingFace BERT)进行了比较。DeepSpeed 在序列长度为 128 和 512 时分别达到了高达 64 和 53 teraflops 的吞吐量(对应于 272 和 52 个样本/秒),比 NVIDIA BERT 提高了 28%,比 HuggingFace BERT 提高了 62%。我们还支持高达 1.8 倍的更大批次大小而不会出现内存不足。
有关我们如何实现破纪录的 BERT 训练时间的更多详细信息,请查看深入了解 DeepSpeed BERT 的 最快 BERT 训练