Microsoft DeepSpeed 实现最快的 BERT 训练时间
好消息!DeepSpeed 取得了最快的 BERT 训练记录:在 1024 块 NVIDIA V100 GPU 上耗时 44 分钟。 这比已发布的最佳结果(在相同数量和代次的 GPU 上实现相同精度所需的 67 分钟端到端训练时间)提高了 30%。这种改进并非以过度硬件资源为代价,而是来自于软件效率的提升。例如,DeepSpeed 在 NVIDIA V100 GPU 上可实现惊人的 64 teraflops 单 GPU 性能,这超过了硬件峰值的 50%。
在这篇博客文章中,我们将讨论使 DeepSpeed 能够实现这一破纪录的 BERT 训练时间的四项技术改进。
- 高度优化的 Transformer 内核,以提高计算效率
- 通过异步预取队列实现 I/O 与计算重叠
- 稀疏输出处理,以消除浪费的计算
- Layer-norm 重新排序,以实现训练稳定性和更快收敛
这些优化不仅使 BERT 受益;它们也适用于许多其他基于 Transformer 的模型,例如 RoBERTa、XLNet 和 UniLM。此外,除了预训练方面的改进,DeepSpeed 在下游任务(如 Bing-BERT SQuAD 的微调)中实现了高达 1.5 倍的加速。
BERT 预训练的性能结果
与 SOTA 相比,DeepSpeed 显著提高了基于 Transformer 的模型(如 BERT)的单 GPU 性能。图 1 展示了通过 DeepSpeed 优化训练 BERT-Large 的单 GPU 吞吐量,并与来自 NVIDIA BERT 和 Hugging Face BERT 的两个知名 PyTorch 实现进行了比较。对于序列长度为 128 和 512 的情况,DeepSpeed 分别达到了 64 和 53 teraflops 的吞吐量(对应每秒 272 和 52 个样本),吞吐量比 NVIDIA BERT 提高了 28%,比 HuggingFace BERT 提高了 62%。我们还支持高达 1.8 倍的更大批量大小,而不会出现内存不足的情况。
为了达到这一性能,DeepSpeed 实现了一种随机 Transformer,它在不影响整体收敛性的前提下,展现出一定程度的非确定性噪声。此外,DeepSpeed 还实现了一种确定性 Transformer 内核,它完全可复现,代价是平均约 2% 的小幅性能下降。用户可以根据其使用场景轻松选择和切换这两种版本:随机版本追求极致的训练性能目标,而确定性版本可以通过更好地促进实验和调试来节省开发时间。我们在图 1 中报告了这两种内核的性能数据。所有批量大小和配置的性能数据都是在梯度累积步长为 10 的情况下收集的,因为在实际场景中使用的总批量大小通常在几百到几千之间。
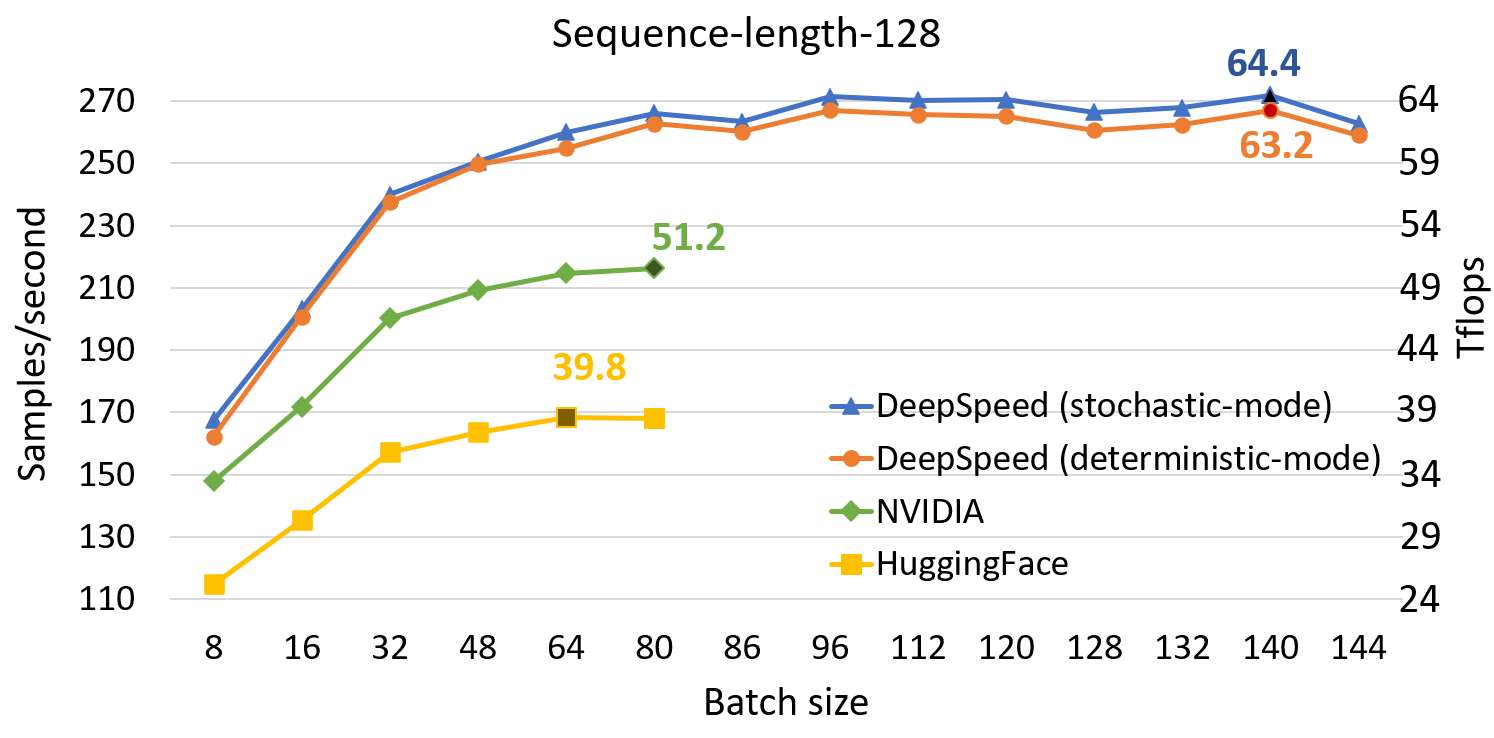
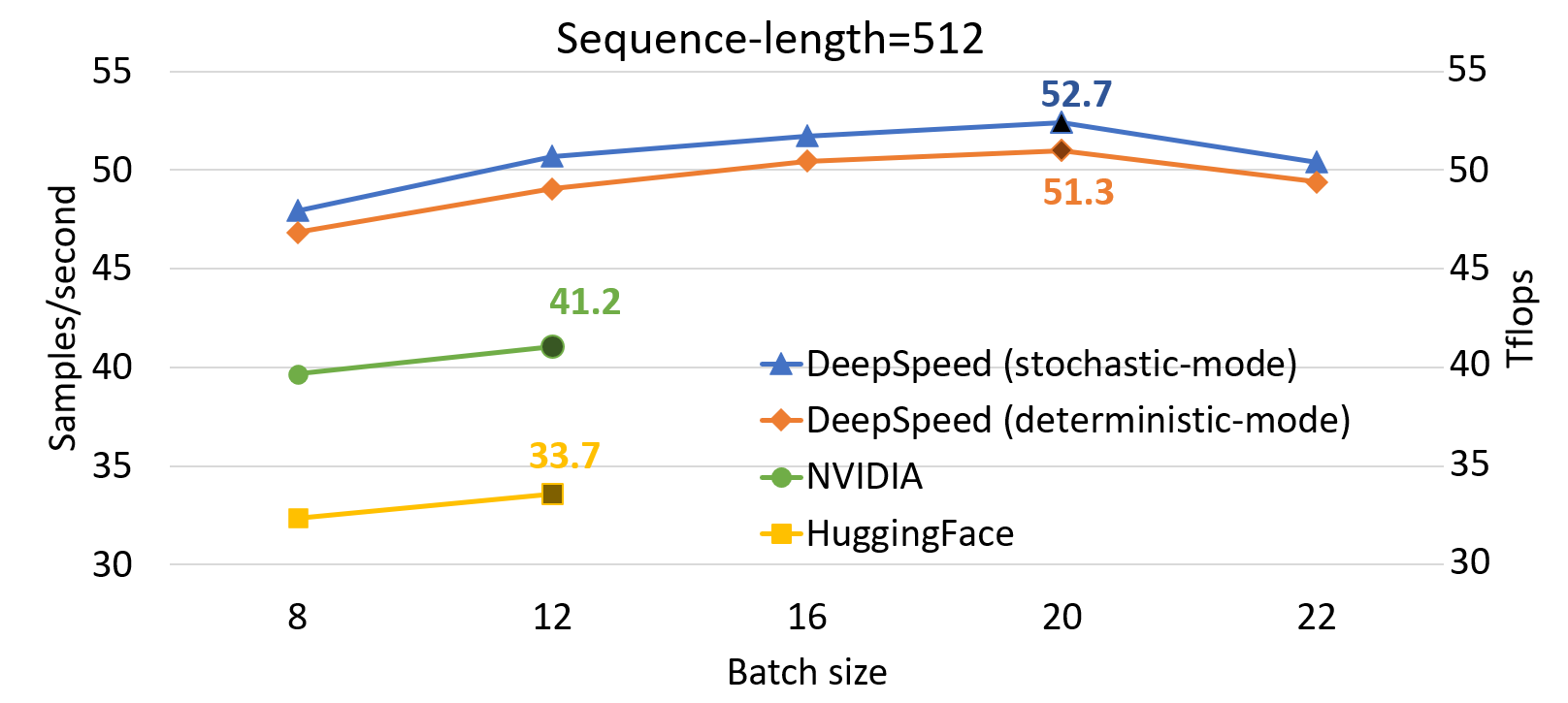
图 1:在单个 V100 GPU 上 BERT-Large 的性能评估,比较了 DeepSpeed 与 NVIDIA 和 HuggingFace 版本的 BERT 在混合序列长度训练中的表现。标记点显示了每种实现在 teraflops (Tflops) 中的最高吞吐量。DeepSpeed 提升了吞吐量并允许在不耗尽内存的情况下使用更大的批量大小。
从跨 GPU 分布式训练来看,表 1 显示了我们使用 16 到 1024 块 GPU 进行 BERT-Large 端到端预训练的时间(SQUAD 的 F1 分数为 90.5)。我们使用 1024 块 V100 GPU(64 个 NVIDIA DGX-2 节点)在 44 分钟内完成了 BERT 预训练。相比之下,NVIDIA 此前的 SOTA 使用 1472 块 V100 GPU 耗时 47 分钟。DeepSpeed 不仅更快,而且使用的资源减少了 30%。在使用相同的 1024 块 GPU 的情况下,NVIDIA BERT 耗时 67 分钟 [1],而 DeepSpeed 仅需 44 分钟,将训练时间缩短了 30%。同样,在 256 块 GPU 上,NVIDIA BERT 耗时 236 分钟,而 DeepSpeed 仅需 144 分钟(快 39%)。
| 节点数量 | V100 GPU 数量 | 时间 |
|---|---|---|
| 1 个 DGX-2 | 16 | 33 小时 13 分钟 |
| 4 个 DGX-2 | 64 | 8 小时 41 分钟 |
| 16 个 DGX-2 | 256 | 144 分钟 |
| 64 个 DGX-2 | 1024 | 44 分钟 |
表 1:使用 1 到 64 个 DGX-2 搭配 DeepSpeed 进行 BERT-Large 训练的时间。
在最近的 GTC 2020 大会上,NVIDIA 发布了下一代硬件 A100,其硬件峰值性能比 V100 GPU 提高了 2.5 倍。假设 A100 GPU 能让我们达到与 V100 GPU 相同的硬件峰值性能百分比(50%),我们预计通过将软件优化与新硬件结合,将获得更高的吞吐量。我们预计在由 1024 块 A100 GPU 组成的集群上,BERT 训练时间将进一步缩短到 25 分钟以内。
微调任务的性能结果
除了预训练所示的性能优势外,我们还评估了定制内核在微调下游任务时的性能。表 2 和表 3 显示了在使用 PyTorch 和 DeepSpeed Transformer 内核、在 NVIDIA V100 上运行 Bing-BERT SQuAD 时(分别使用 16 GB 和 32 GB 内存)每秒处理的样本数。对于 16 GB V100,我们可以在支持每 GPU 2 倍大批量大小的同时实现高达 1.5 倍的加速。另一方面,使用 32 GB 内存,我们可以支持高达 32 的批量大小(比 PyTorch 多 2.6 倍),同时为端到端微调训练提供 1.3 倍的加速。请注意,对于 PyTorch 出现内存不足(OOM)的情况,我们使用最佳的每秒样本数来计算加速比。
| 微批量大小 | PyTorch | DeepSpeed | 加速比 (x) |
|---|---|---|---|
| 4 | 36.34 | 50.76 | 1.4 |
| 6 | 内存不足 | 54.28 | 1.5 |
| 8 | 内存不足 | 54.16 | 1.5 |
表 2:在 NVIDIA V100 (16-GB) 上使用 PyTorch 和 DeepSpeed Transformer 内核运行 SQuAD 微调的每秒样本数。
| 微批量大小 | PyTorch | DeepSpeed | 加速比 (x) |
|---|---|---|---|
| 4 | 37.78 | 50.82 | 1.3 |
| 6 | 43.81 | 55.97 | 1.3 |
| 12 | 49.32 | 61.41 | 1.2 |
| 24 | 内存不足 | 60.70 | 1.2 |
| 32 | 内存不足 | 63.01 | 1.3 |
表 3:在 NVIDIA V100 (32-GB) 上使用 PyTorch 和 DeepSpeed Transformer 内核运行 SQuAD 微调的每秒样本数。
BERT 高度优化的 Transformer 内核
GPU 具有非常高的浮点峰值吞吐量,但大多数框架实现中的默认 Transformer 块远未达到此峰值。图 2 显示了 Transformer 块的结构,其中 LayerNorm 放置在两个子层(Attention 和 Feed-Forward)的输入流上。为了接近 GPU 峰值性能,我们在自己的 Transformer 内核实现中采用了两类优化:高级融合和可逆算子。
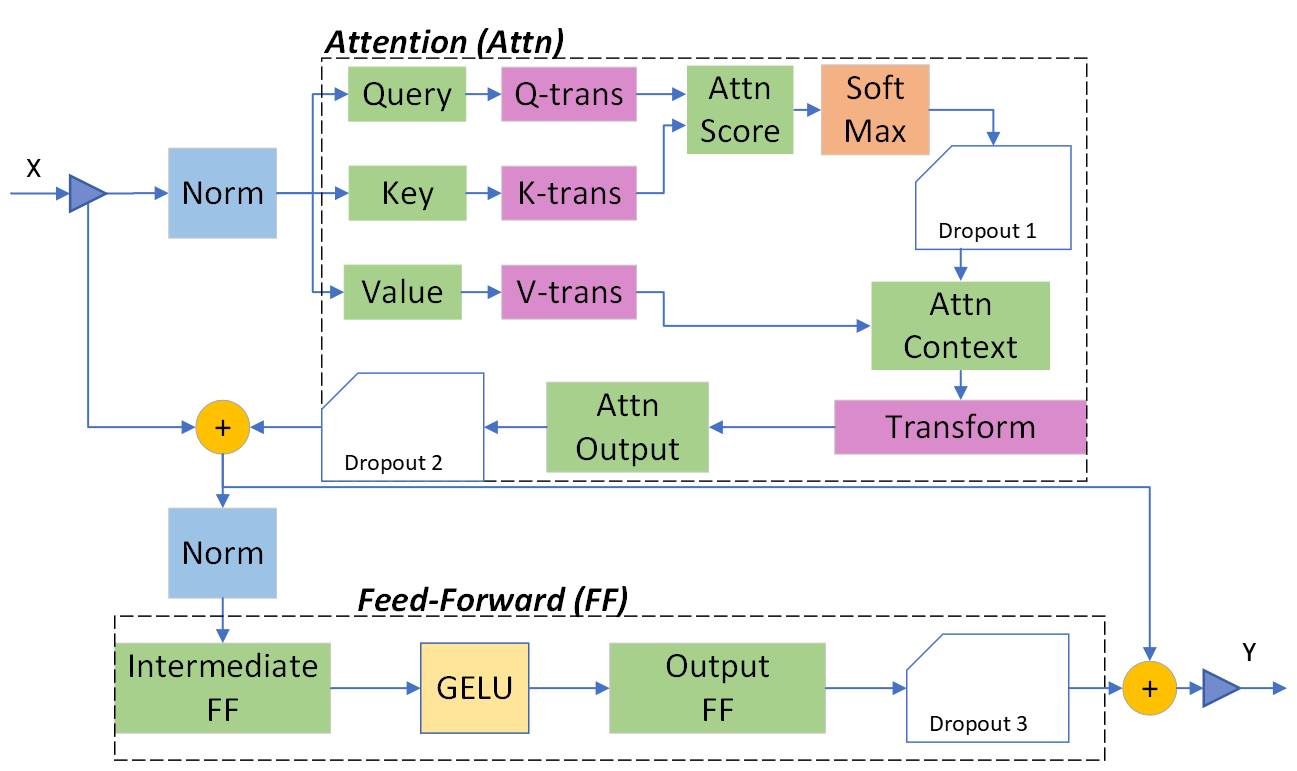
图 2:采用 Pre-LayerNorm 架构的 Transformer 层
(a) 先进的融合内核以减少数据移动
我们观察到,基于 Transformer 的网络会触发大量以生产者-消费者方式运行的 CUDA 内核调用,这增加了大量将数据传输到全局内存和从全局内存传出的成本,以及内核启动的开销。现有基于编译器的方案执行细粒度融合(例如,逐元素操作的融合),导致错失融合机会。相比之下,我们充分利用了细粒度和粗粒度融合,并为 Transformer 块进行了定制。
QKV 和各种融合。 我们将三个 Query (Q)、Key (K) 和 Value (V) 权重矩阵合并,以调度更大的 QKV GEMM,从而在 GPU 的共享内存和寄存器文件中暴露出更多的并行性并提高数据局部性,如图 3 所示。接下来,我们将 QKV 输出矩阵的数据布局转换与偏置加法相结合。然后,我们将大型 QKV 矩阵划分为三个转换后的矩阵,用于后续的自注意力计算。
如图 3 所示,我们按连续的行(由红框显示)读取 QKV 矩阵,并将它们写入三个转换后的 Q、K 和 V 矩阵中。由于每个矩阵从不同的偏移量开始,我们可能会对主内存进行非合并访问。因此,我们使用共享内存作为中间缓冲区,以便重新排列数据,使其可以放入内存的连续部分。尽管我们在访问共享内存时会产生非合并模式,但我们减少了对主内存进行非合并访问的成本,以更好地利用内存带宽,从而在端到端训练中实现了 3% 到 5% 的性能提升。
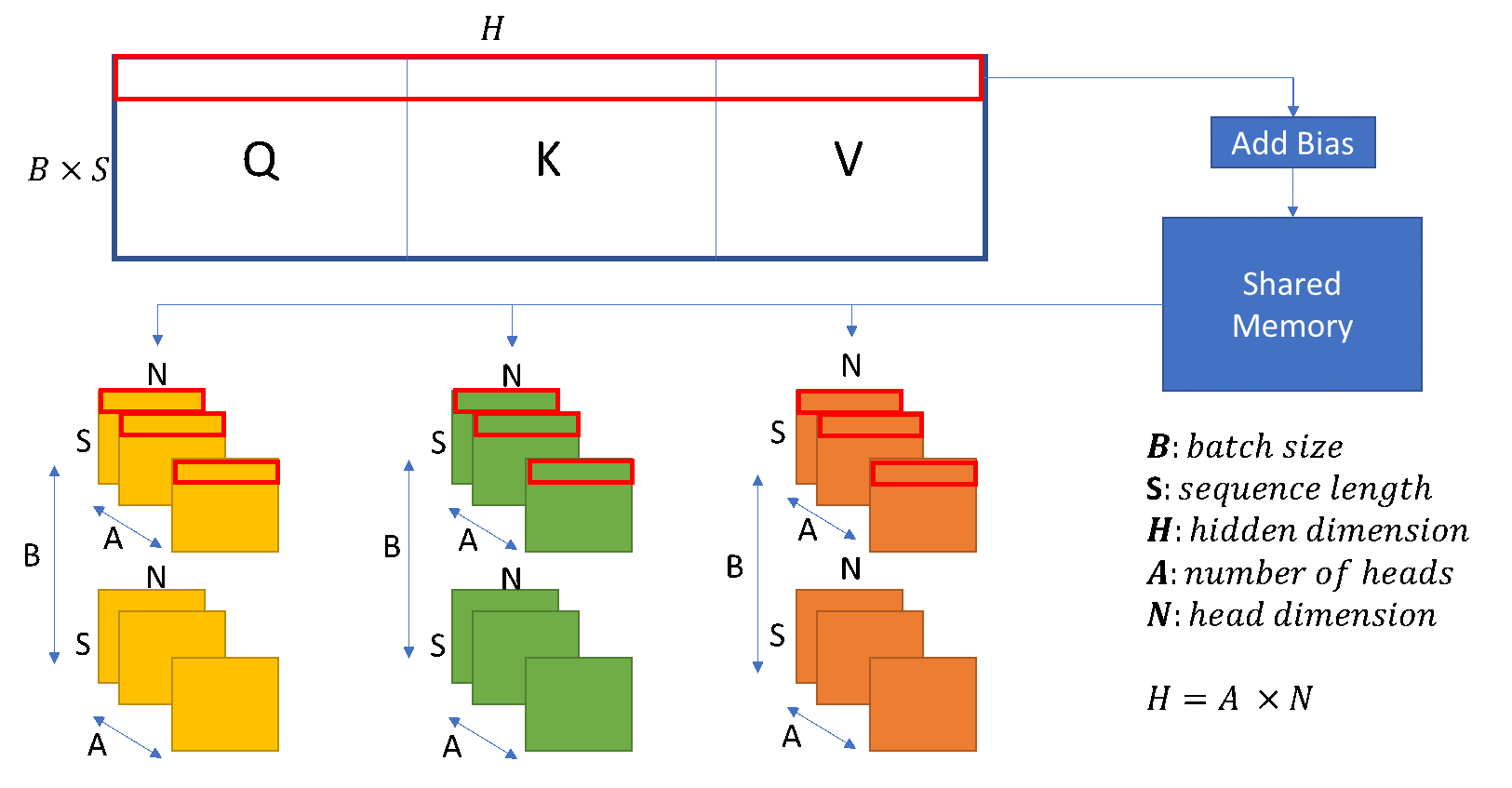
图 3:QKV 的 GEMM 和转换内核融合
我们还进行了额外的融合,例如将注意力输出 GEMM 中的偏置加法与残差连接中的加法以及 dropout 进行合并,这使得访问可以在寄存器文件和共享内存中进行,其速度比昂贵的写回全局内存快几个数量级。
Warp 级通信。 为了减轻并行 GPU 核之间的同步开销并进一步提高融合内核的资源利用率,我们使用 warp 级(数据混洗指令)而非默认的 inter-warp 通信。以层归一化和 SoftMax 内核为例,我们在一个 warp 内部执行每个归约操作,同时将不同的归约操作分布到不同的 warp。通过这种方式,我们减轻了并行线程之间的同步,并进一步提高了 GPU 资源利用率。
随机与确定性内核。 深度学习训练通常对一定程度的随机性具有鲁棒性,在某些情况下,受控噪声(如 dropout)可作为正则化器,从而提高泛化能力。在设计我们的 Transformer 内核时,我们接受一定程度的随机性以提高吞吐量,方法是允许内核中存在有限的数据竞争条件:我们利用隐式 warp 同步编程来实现 warp 级协作操作的更高性能 [3]。缺少显式 warp 级同步可作为非确定性噪声,在不影响 Transformer 内核整体收敛行为的同时,提供可观的吞吐量提升。
此外,DeepSpeed 还实现了一个非随机 Transformer 内核,该内核具有显式 warp 同步功能,可产生确定性结果,代价是性能略有下降。用户可以根据其使用场景轻松选择和切换这两种版本:随机版本追求极致的训练性能目标,而确定性版本可以通过更好地促进实验和调试来节省开发时间。
在我们的实验中,我们使用随机内核进行 BERT 预训练,而使用非随机内核进行微调,以实现完全可复现的结果。我们建议在涉及大量数据(如预训练)的训练任务中使用随机内核,而在数据有限(如微调)的情况下使用非随机版本以获得更一致的结果。
成本效益高的重物化。 在融合不同操作的内核时,我们观察到某些算子计算起来不费力,但会产生昂贵的数据移动成本,例如偏置加法和 dropout。对于这些操作,我们避免在前向传播中保存它们的结果,而是在反向传播中重新计算它们,这比将它们的结果写入并从主内存重新加载要快得多。
(b) 可逆算子以节省内存并运行大批量
我们还观察到,Transformer 块中几个算子的中间激活会消耗大量内存,例如 SoftMax 和 Layer Norm。对于这些算子,我们通过利用它们是可逆函数的事实(即它们的反向传播独立于输入,并且可以仅基于输出来 формулировать [2]),丢弃了这些层的输入,以减少激活内存的占用。图 4 和图 5 展示了 PyTorch 中 SoftMax 和 Layer-Norm 的原始实现与 DeepSpeed 中可逆 SoftMax 实现的示例。通过这项优化,我们能够将算子的激活内存减少一半,而减少的内存使我们能够使用更大的批量大小进行训练,这再次提高了 GPU 效率。
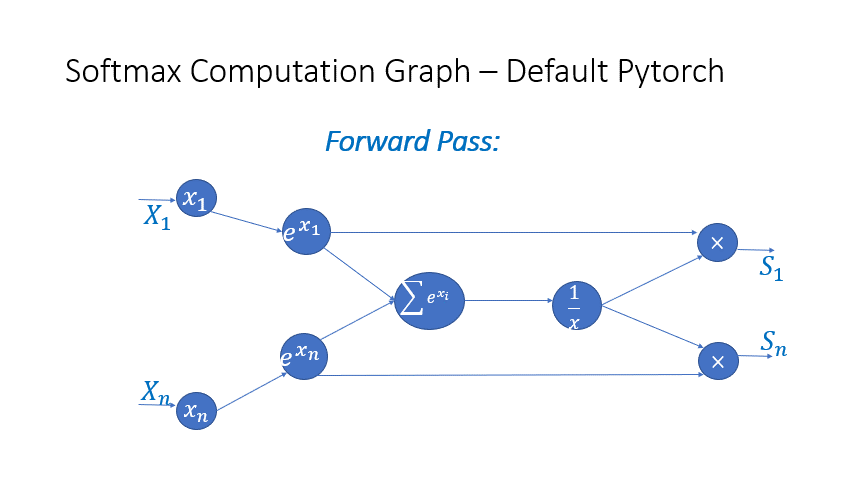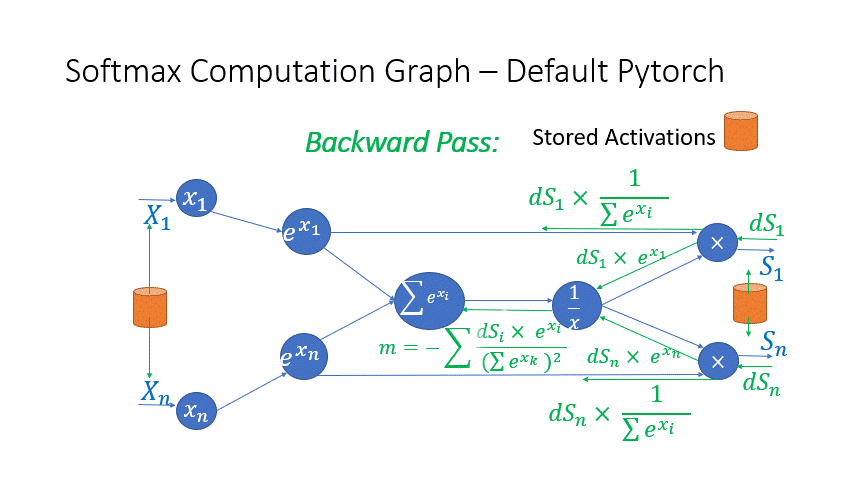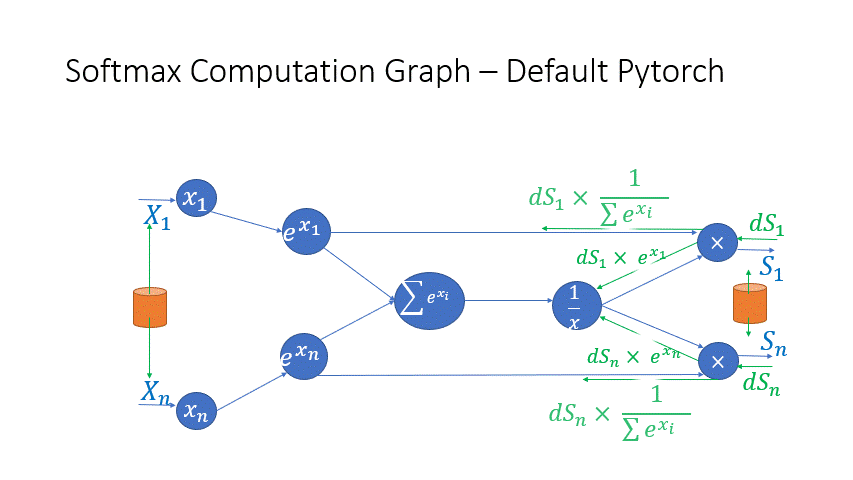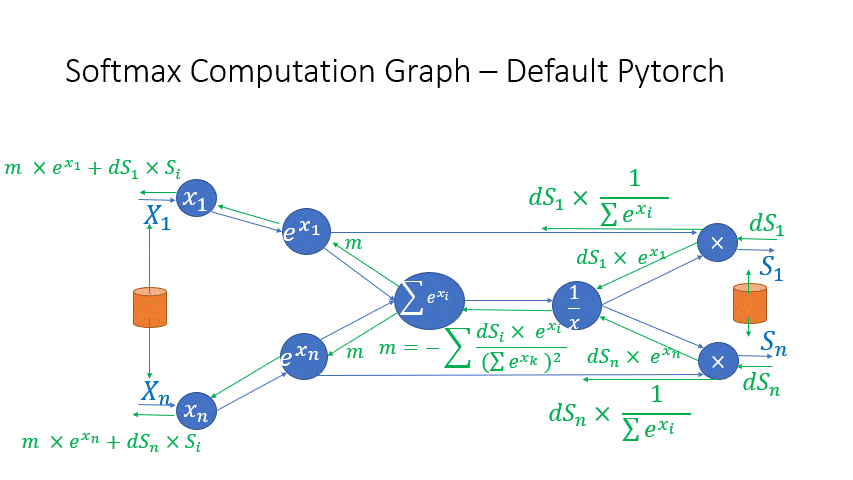
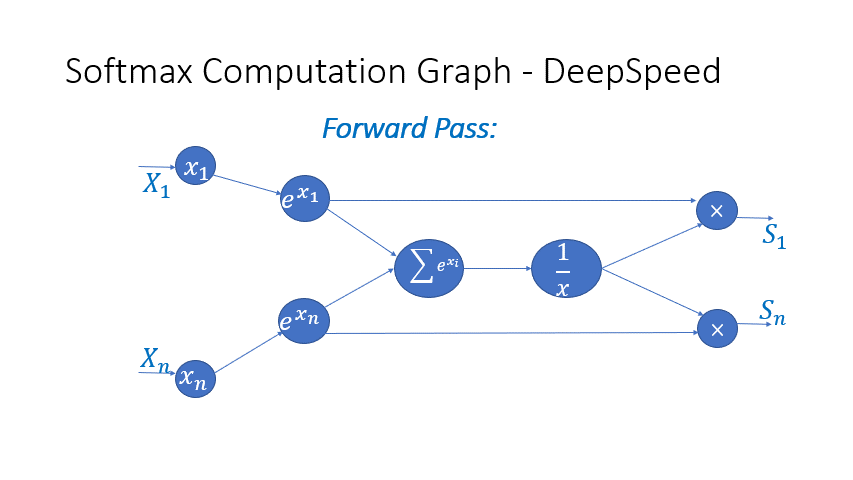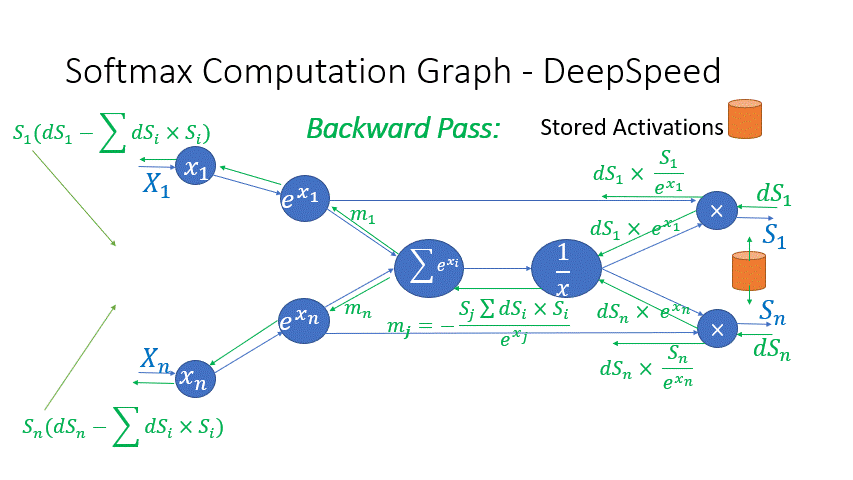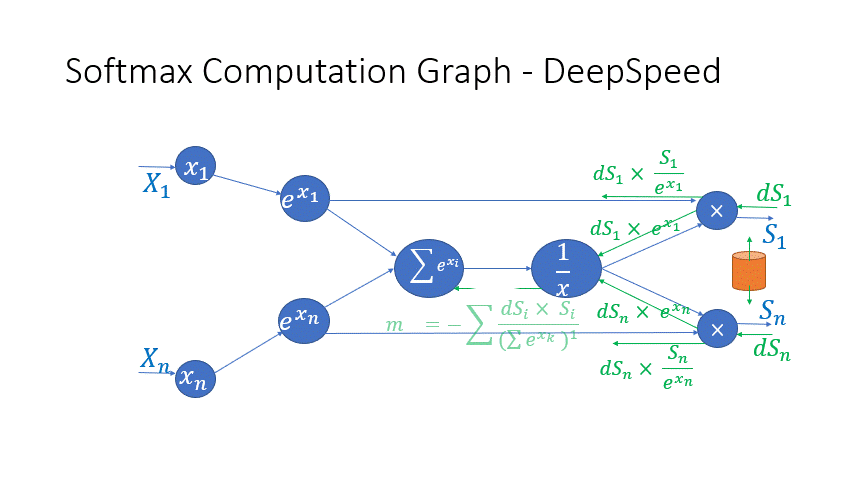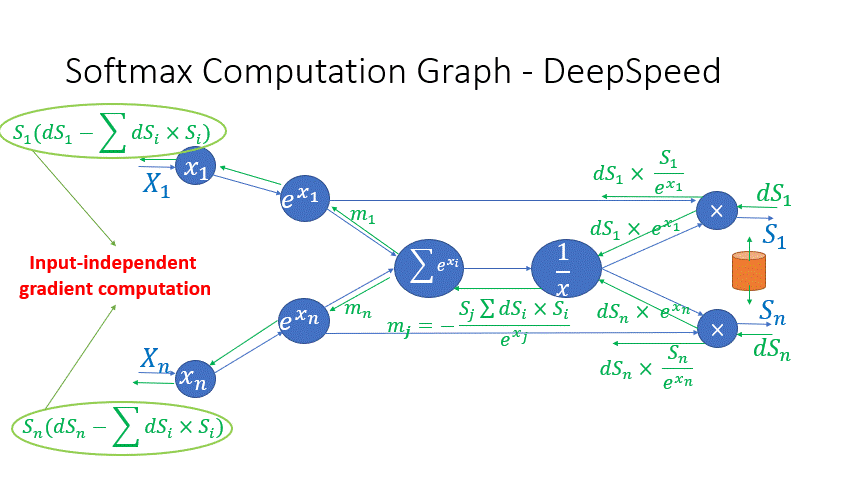
图 4:DeepSpeed 可逆 SoftMax 操作与默认 PyTorch SoftMax 操作的比较
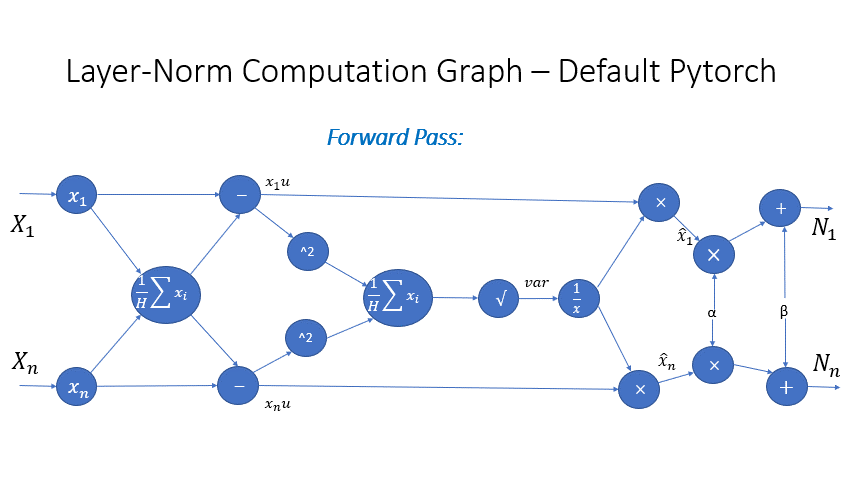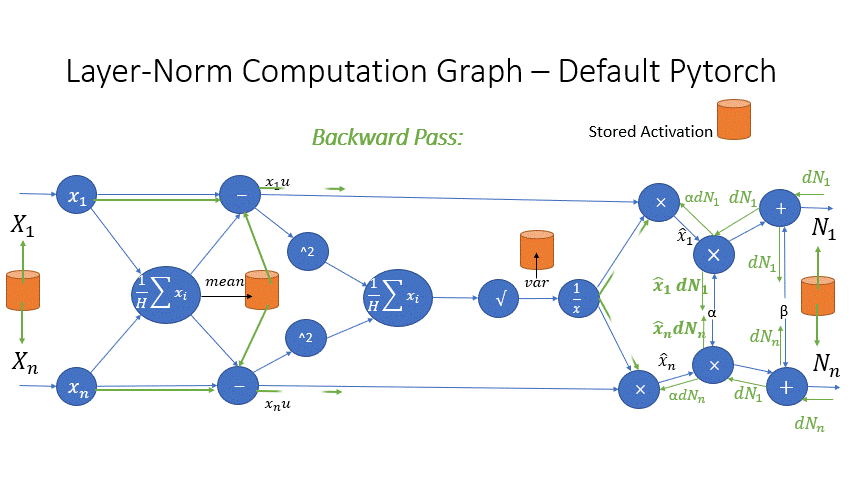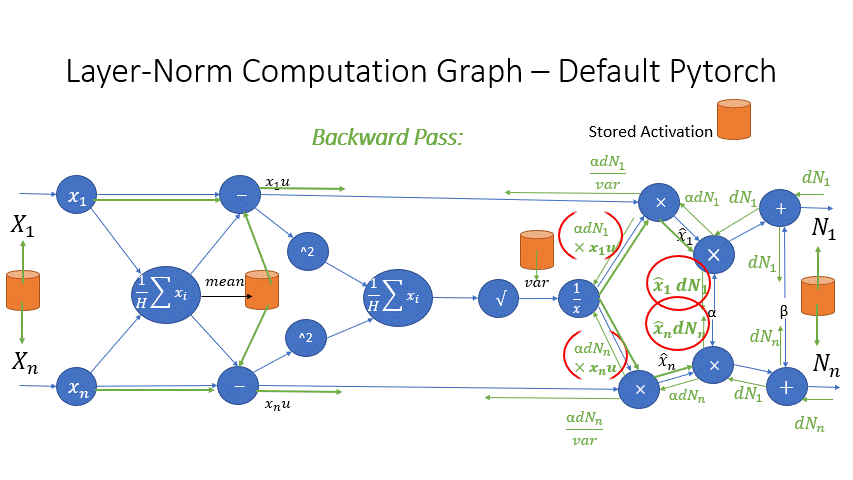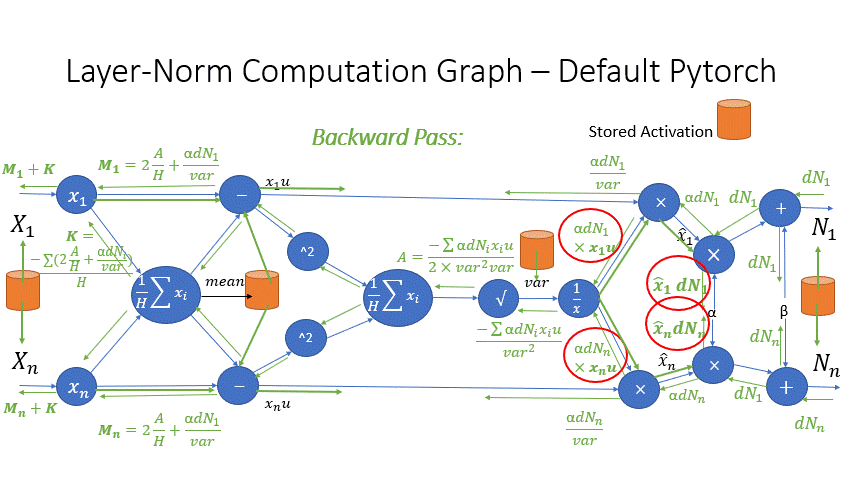
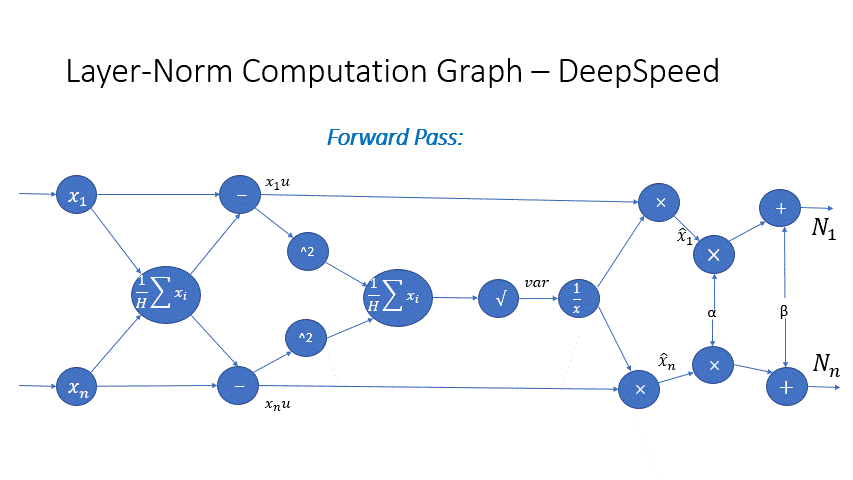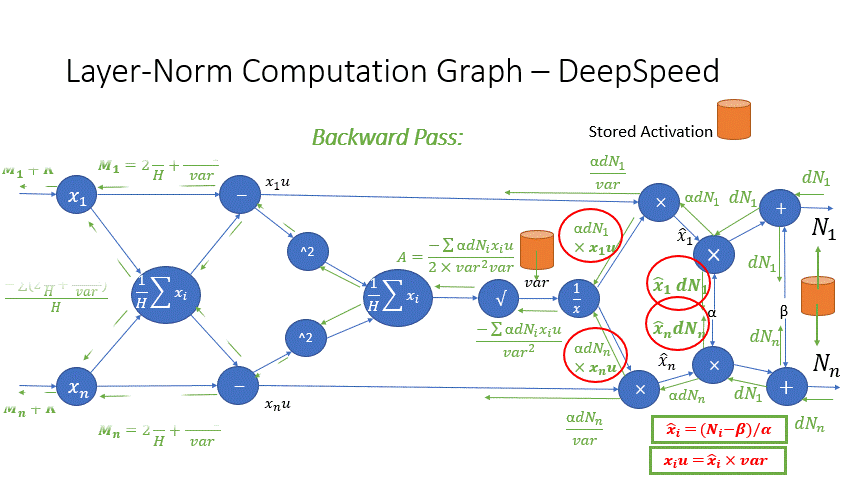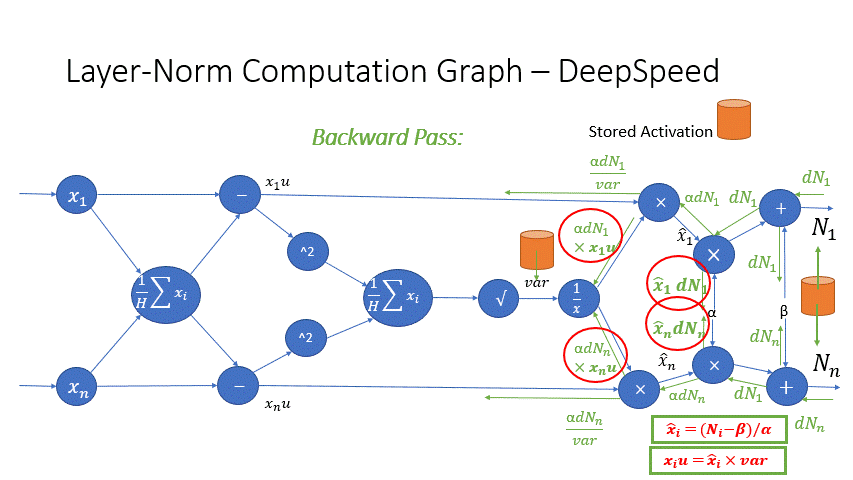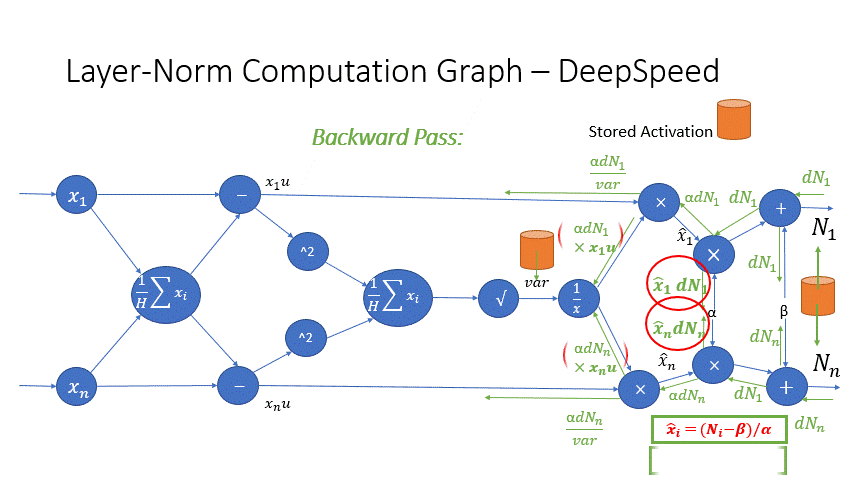
图 5:DeepSpeed 可逆 LayerNorm 操作与默认 PyTorch LayerNorm 操作的比较
通过异步预取队列实现 I/O 与计算重叠
除了高度优化的 Transformer 内核,BERT 训练还有其他性能限制因素,例如数据加载。我们开发了自己的异步工作器,它仅在“安全点”(即 CPU 空闲时,例如异步启动前向传播之后)将批次数据预取到队列中。通过这种方式,我们确保在 CPU 端进行计算时,不会发生从 CPU 到 GPU 的数据出队和复制。这与默认的 PyTorch 数据加载器不同,后者可以在任何时候预取数据并导致性能干扰。通过使用此方法,我们几乎隐藏了所有 I/O 开销,这占原始训练时间的 4%。
利用 BERT 输出处理的稀疏性
通过识别和利用 BERT 输出处理中的稀疏性,我们将端到端训练时间缩短了 5.4%。输出处理包括两个步骤:i) 使用矩阵-矩阵乘法将 BERT 从最终 Transformer 层的隐藏输出维度投影到语言词汇表,以及 ii) 对掩码输出 token 进行交叉熵以获取每个序列的预测误差。第一步的成本与词汇大小、隐藏输出维度和序列长度成正比,并且可能与 Transformer 层计算一样昂贵甚至更昂贵。然而,只有大约 15% 的 token 被掩码,并且我们只需要对掩码 token 进行交叉熵计算。因此,投影可以作为一种高效的稀疏计算来完成。为此,我们在进行投影之前丢弃了最终 Transformer 层中与非掩码 token 对应的行,从而将输出处理的计算成本降低了 85%。
Pre-LayerNorm 与 Post-LayerNorm 架构
我们观察到,在大型批量大小(例如 64K)下,默认的 BERT 预训练存在训练不稳定性问题,这可能导致模型发散或收敛到不良/可疑的局部最优。进一步调查表明,默认的 BERT 存在梯度消失问题。为了缓解这个问题,我们改变了 LayerNorm 的位置(Post-LayerNorm),将其仅放置在 Transformer 块中子层的输入流上(称为 Pre-LayerNorm),这是最近几项神经机器翻译工作中所描述的一种修改。Pre-LayerNorm 带来了几个有用的特性,例如避免梯度消失、稳定的优化和性能提升。它使我们能够以 64K 的聚合批量大小进行训练,并提高学习率和加快收敛速度。
要尝试这些优化和训练方案,请查看我们的 BERT 训练教程 和 DeepSpeed GitHub 仓库 中的源代码。
参考文献
[1] “NVIDIA 创造全球最快 BERT 训练时间及最大基于 Transformer 模型,为高级对话式 AI 铺平道路” https://devblogs.nvidia.com/training-bert-with-gpus/。
[2] S. R. Bulo, L. Porzi, 和 P. Kontschieder,“用于 DNN 内存优化训练的原地激活批归一化” 2017. http://arxiv.org/abs/1712.02616。
[3] Mark Harris 和 Kyrylo Perelygin,“协作组:灵活的 CUDA 线程编程”,https://devblogs.nvidia.com/cooperative-groups/。