DeepSpeed 数据效率:一个可组合的库,旨在更好地利用数据、提高训练效率和改善模型质量
近年来,大规模深度学习模型正在许多方面赋能我们实现更多,例如通过代码生成提高编程效率以及通过文本到图像生成提供艺术灵感。为了实现这些服务并持续提高质量,深度学习模型架构发展迅速,模型规模也在以惊人的速度增长。例如,从GPT到GPT-3,模型规模在2年内增长了1500倍。模型规模的增长导致了前所未有的训练成本,这使得许多AI从业者难以训练自己的模型。另一方面,一个较少被强调的观点是,数据规模实际上与模型规模以相似的速度增长,并且训练成本与两者都成正比。在下面的图1中,我们绘制了过去5年中几个代表性语言模型的模型和数据规模。从左侧最旧的模型到右侧最新的模型,模型和数据规模都以相似的速度增长。这表明提高数据效率的重要性:用更少的数据和更低的训练成本实现相同的模型质量,或者用相同的数据量和相似的训练成本实现更好的模型质量。
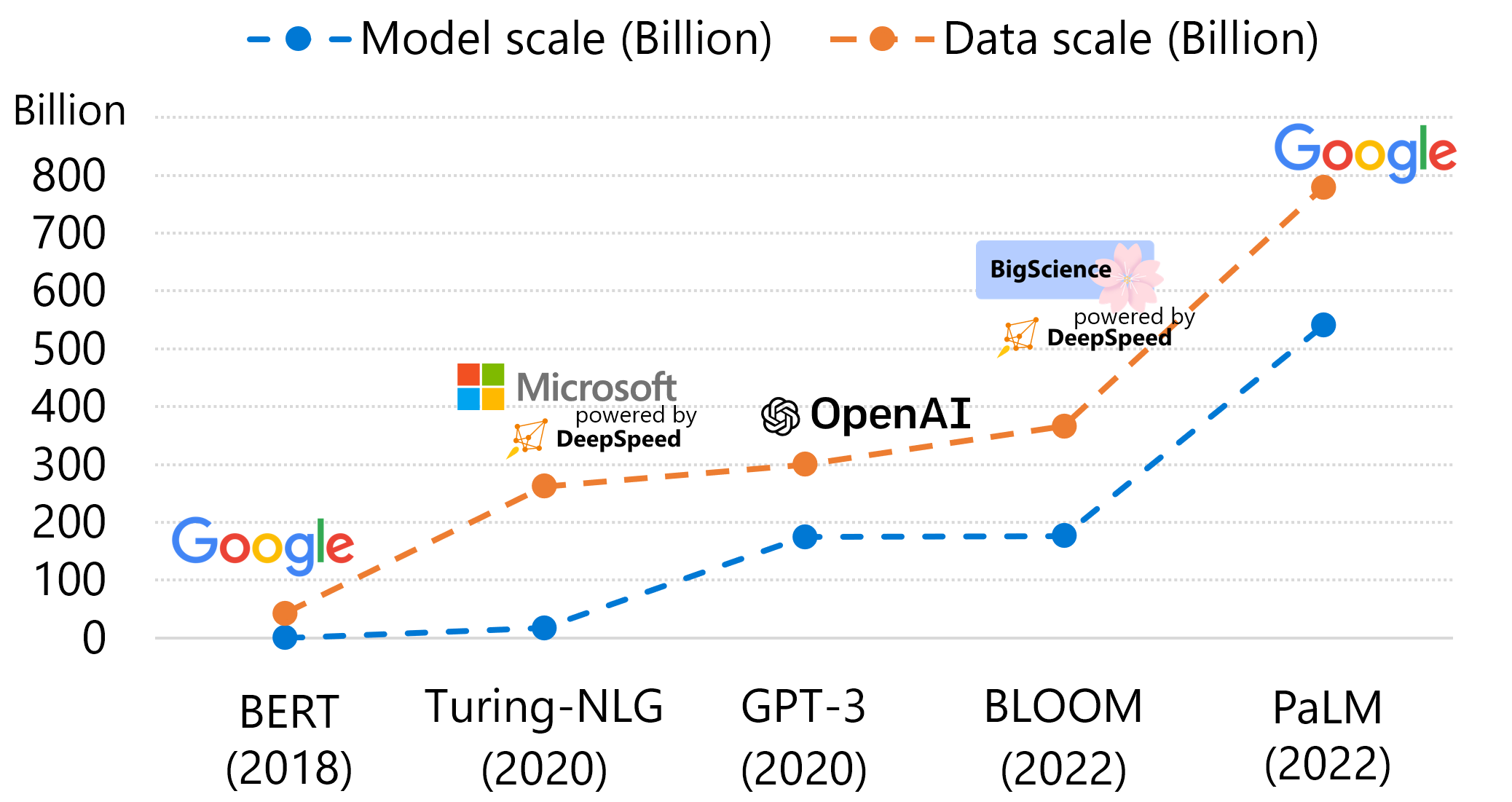
图1:过去5年中代表性语言模型的模型规模(参数数量)和数据规模(训练期间消耗的令牌数量)。
现有数据效率技术中有两个流行的研究方向:数据采样技术旨在通过从整个数据池中采样最合适的下一个数据批次来提高收敛速度;数据路由技术旨在通过将每个数据只路由到模型组件的子集来减少计算。这些技术提高了数据和训练效率,但现有解决方案在可扩展性、灵活性和可组合性方面存在局限性。它们通常是为特定训练任务设计的,这使得它们难以通过自定义策略进行扩展,并且在应用于不同用户的多样化工作负载时灵活性较差。此外,不同的技术是独立实现的,这使得组合多个解决方案以进一步提高数据和训练效率变得具有挑战性。
为了应对这些挑战,我们,作为微软大规模AI计划一部分的DeepSpeed团队,自豪地宣布推出DeepSpeed数据效率库——一个可组合的框架,旨在更好地利用数据、提高训练效率和改善模型质量。DeepSpeed数据效率考虑了可扩展性、灵活性和可组合性,并具体展示了以下创新:
通过课程学习实现高效数据采样。课程学习(CL)通过从较简单的数据中采样来提高数据效率。我们提出了一个通用的课程学习库,它使用户能够以最大可扩展性将课程学习应用于他们的模型:用户可以根据各种可自定义的策略轻松分析、索引和采样他们的训练数据。使用该库,我们能够探索GPT-3和BERT预训练的不同CL策略,并确定最佳解决方案,该方案可在保持相似模型质量的同时,实现高达1.5倍的数据节省。
通过随机逐层令牌丢弃实现高效数据路由。我们提出了一种新颖的数据路由技术,称为随机逐层令牌丢弃(random-LTD),用于在所有中间层跳过一部分输入令牌的计算。random-LTD采用了一种简单而有效的路由策略,并且只需要最小的模型架构更改。它能够灵活地应用于各种任务(GPT-3/BERT预训练和GPT/ViT微调),并且我们实现了显著的数据效率提升(在保持模型质量的同时,高达1.5倍的数据节省)。
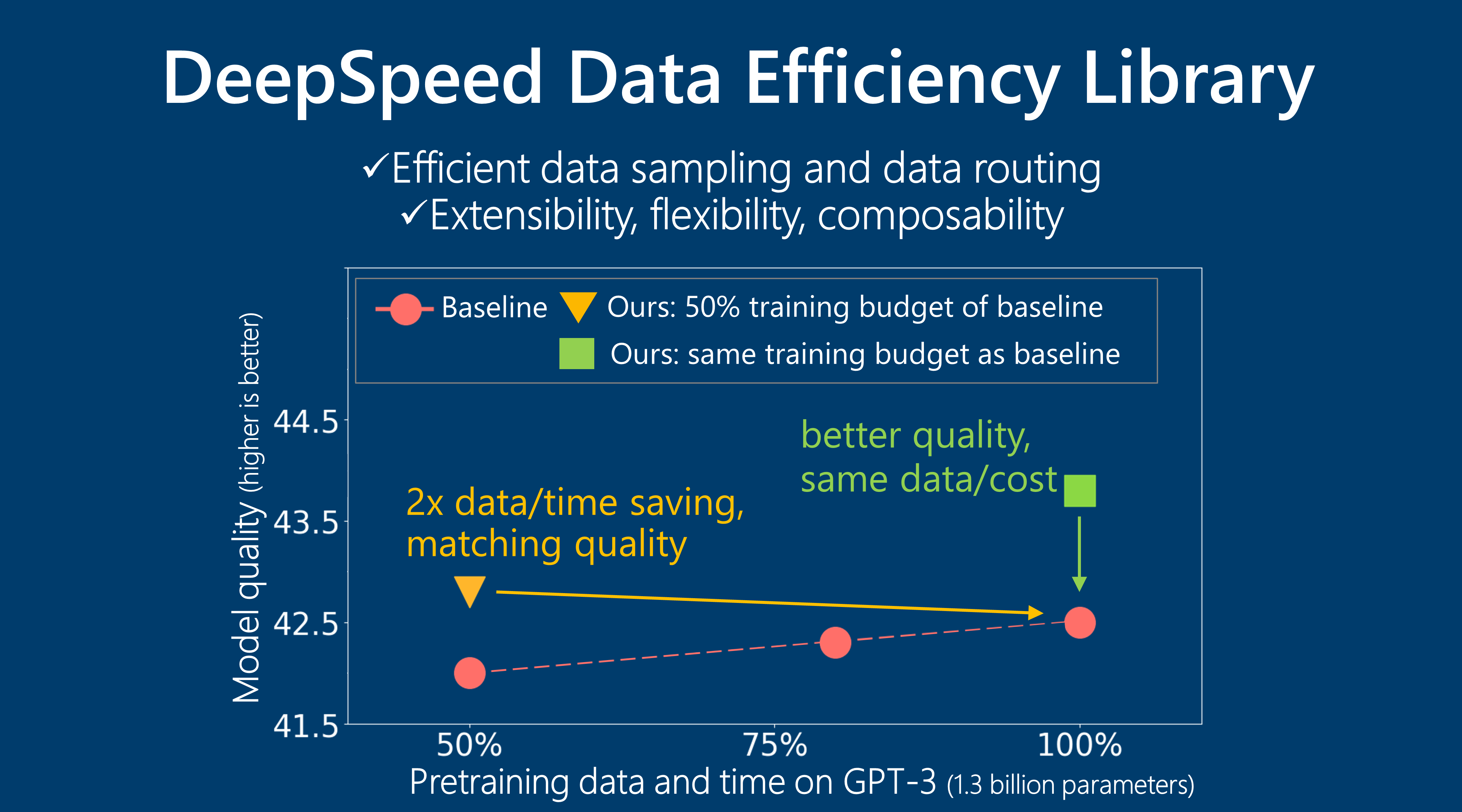
无缝组合多种方法。所提出的DeepSpeed数据效率框架无缝地组合了课程学习和random-LTD技术,并且只需用户代码端进行最小的更改。此外,通过组合这两种方法,我们可以实现更好的数据和训练效率:对于GPT-3 1.3B预训练,与基线训练相比,我们实现了2倍的数据和2倍的时间节省,同时模型质量更好或相似。当使用相同数据量时,我们的方法进一步提高了模型质量,超越了基线。用户还可以通过添加额外的数据效率技术来扩展和贡献该库,以实现组合。
这些进展将在下面的博客文章中进一步探讨。有关更多技术细节,请阅读我们的论文,“Random-LTD: Random and Layerwise Token Dropping Brings Efficient Training for Large-scale Transformers”(描述random-LTD技术),以及“DeepSpeed Data Efficiency: Improving Deep Learning Model Quality and Training Efficiency via Efficient Data Sampling and Routing”(描述课程学习技术和整体DeepSpeed数据效率框架)。
通过课程学习实现高效数据采样
动机
课程学习旨在通过在训练早期呈现相对更容易或更简单的示例来提高训练收敛速度。构建一个课程学习解决方案通常需要两个组成部分:难度度量(即如何量化每个数据样本的难度)和步调函数(即在采样下一个训练数据批次时如何决定课程难度范围)。课程学习已成功应用于各种训练任务,去年我们还发布了一种针对GPT风格模型预训练的特定课程学习技术(序列长度热身,详细技术细节请参阅我们发表在NeurIPS 2022上的论文“The Stability-Efficiency Dilemma: Investigating Sequence Length Warmup for Training GPT Models”)。然而,现有工作的一个常见局限性是缺乏一个通用且可扩展的课程学习库,该库允许实践者轻松应用自定义课程难度度量、度量组合和步调函数。
设计
为了解决现有解决方案的局限性,我们设计并实现了一个通用课程学习库,强调其可扩展性。它由图2(顶部)所示的三个组件组成。首先,我们使用数据分析器执行离线仅CPU数据分析,该分析根据任何难度度量(例如序列长度、词汇稀有度或用户定义的任何内容)对整个数据池进行索引。接下来,在训练期间,课程调度器根据步调函数(例如线性、开方或其他用户提供的策略)确定当前步骤的难度阈值。然后,数据采样器将从已索引的数据池中采样所需难度的数据。总的来说,这种通用实现将使用户能够以最大程度的可定制性探索其工作负载上的课程学习(更多技术细节请参阅我们的DeepSpeed数据效率论文)。
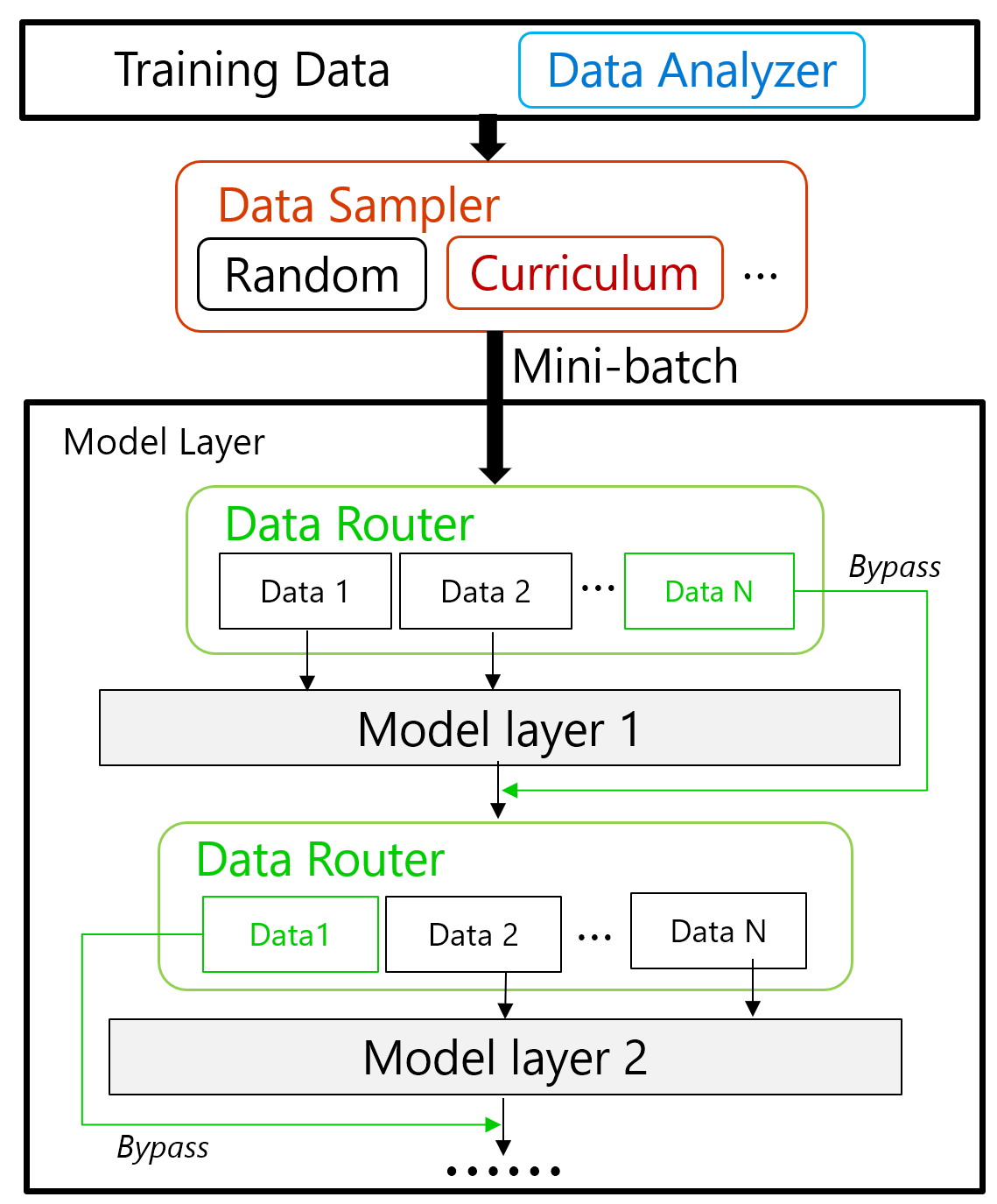
图2:DeepSpeed数据效率框架的设计。
评估结果
将这种通用且可扩展的课程学习解决方案应用于GPT-3和BERT-Large模型预训练,我们能够轻松地根据多达7种难度度量分析和索引海量训练数据,从而实现更好的数据和训练效率。对于GPT-3预训练,我们采用最佳难度度量(基于截断的序列长度和词汇稀有度的组合)的解决方案,在保持与基线模型质量相似的同时,实现了1.5倍的数据和训练成本节省(表1案例(8) 对比 (1))。对于BERT-Large预训练,我们采用最佳难度度量(词汇稀有度)的解决方案,在保持模型质量的同时实现了1.5倍的节省(表2案例(8) 对比 (1))。另一方面,当使用与基线相同的数据量时,我们的解决方案可以进一步提高模型质量(表1案例(2)到(6),表2案例(2)到(6))。
| 案例 | 预训练数据 | 平均0样本准确率 | 平均10样本准确率 |
|---|---|---|---|
| (1) 基线 | 300B | 42.5 | 44.0 |
| (2) CL 基于截断的序列长度 | 300B | 43.4 | 44.8 |
| (3) CL 基于重塑的序列长度 | 300B | 43.0 | 44.5 |
| (4) CL 词汇稀有度 | 300B | 42.3 | 44.5 |
| (5) CL 结合 (2) 和 (4) | 300B | 43.6 | 44.9 |
| (6) CL 结合 (3) 和 (4) | 300B | 43.0 | 44.4 |
| (7) 基线 | 200B (1.5倍) | 41.9 | 44.0 |
| (8) CL 结合 (2) 和 (4) | 200B (1.5倍) | 42.7 | 44.5 |
表1:GPT-3 1.3B预训练数据消耗和在19个任务上的平均评估准确率。
| 案例 | 预训练数据 | GLUE 微调得分 |
|---|---|---|
| (1) 基线 | 1049B | 87.29 |
| (2) CL 基于截断的序列长度 | 1049B | 87.31 |
| (3) CL 基于重新排序的序列长度 | 1049B | 87.48 |
| (4) CL 词汇稀有度 | 1049B | 87.36 |
| (5) CL 结合 (2) 和 (4) | 1049B | 87.60 |
| (6) CL 结合 (3) 和 (4) | 1049B | 87.06 |
| (7) 基线 | 703B (1.5倍) | 87.19 |
| (8) CL 结合 (2) 和 (4) | 703B (1.5倍) | 87.29 |
表2:BERT-Large预训练数据消耗和在8个任务上的平均GLUE微调得分。
通过随机逐层令牌丢弃实现高效数据路由
动机
标准数据路由通常将完整的图像/序列输入到模型的所有层中。然而,这个过程对于训练效率可能不是最优的,因为图像的某些部分(或句子的词语)不需要频繁的特征更新。因此,已经提出了令牌丢弃方法,如下图3 (b)所示,以跳过句子中某些令牌/词语(即图3 (b)中的G-2令牌)的计算,从而节省计算成本。
尽管现有方法显示出有希望的结果,但它们也存在一些注意事项:(1)大多数工作只关注BERT(仅文本数据上的编码器)预训练,不包括解码器预训练和/或其他模态(例如图像);(2)跳过层的能力有限,这限制了总的计算节省量。通过分析现有方法,我们发现限制其跳过和覆盖能力的主要潜在问题是所有跳过的层的G-2令牌的注意力机制的丢失,因为多头注意力在不同的层深度上关注不同的令牌,并且注意力图在Transformer架构的中间部分与依赖关系对齐最强。
设计
为了解决这个主要问题,我们提出了random-LTD,一种随机和逐层令牌丢弃机制,它只处理所有中间层中整个数据批次中的一部分令牌,以节省计算成本(更多详情请参阅我们的Random-LTD论文)。因此,每个令牌很少会绕过所有中间层,并且其与其他令牌的依赖关系可以被模型捕获。random-LTD与基线的比较如下图3所示,其中random-LTD将输入令牌分为两组,只有第一组涉及计算。
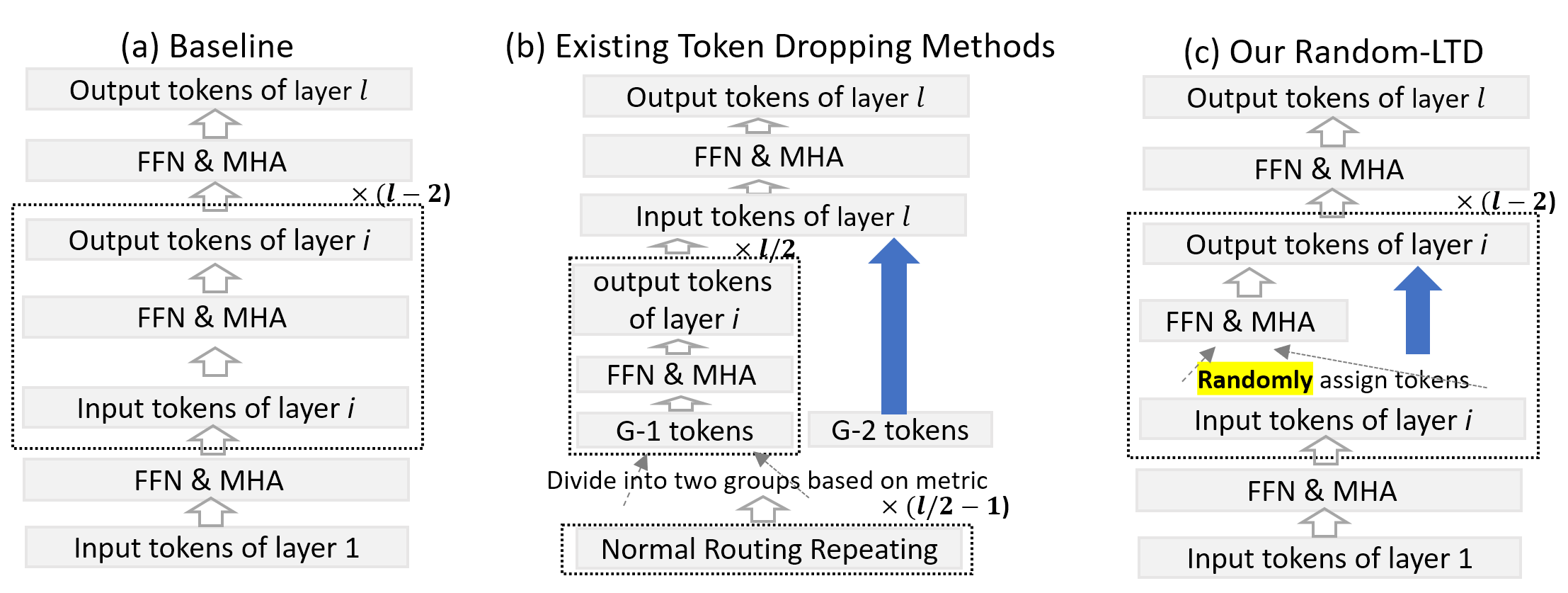
图3:基线、现有令牌丢弃方法和random-LTD之间的比较。请注意,对于random-LTD,输入的一部分(组1)才用于第i层。
Random-LTD简单但非常有效。特别是,与其他现有令牌丢弃方法相比,random-LTD(1)为每层对两个不同组进行纯随机选择,因此我们不需要任何专家设计选择标准;(2)能够应用于所有中间层以实现更好的节省率;(3)对编码器和解码器模型都显示出极佳的泛化能力;并且(4)易于使用,无需大量模型更改。这些优势使得在将random-LTD应用于各种工作负载时具有最大灵活性。
评估结果
由于其出色的灵活性,我们能够将random-LTD方法应用于更广泛的应用,包括BERT和GPT预训练以及ViT和GPT微调任务。在所有情况下,random-LTD在使用更少数据的情况下实现与基线相似的模型质量,和/或在使用相同数据量的情况下实现更好的模型质量(表3到6)。对于GPT-3和BERT-Large预训练,random-LTD实现了1.5-2倍的数据节省,同时保持相同的模型质量。对于GPT-3,我们还测试了使用全部数据的random-LTD,这与基线相比进一步提高了模型质量。
| 案例 | 预训练数据 | 平均0样本准确率 |
|---|---|---|
| (1) 基线 | 300B | 42.5 |
| (2) Random-LTD | 300B | 43.7 |
| (3) Random-LTD | 200B (1.5倍) | 42.5 |
表3:GPT-3 1.3B预训练数据消耗和在19个任务上的平均评估准确率。
| 案例 | 预训练数据 | GLUE 微调得分 |
|---|---|---|
| (1) 基线 | 1049B | 87.29 |
| (2) Random-LTD | 524B (2倍) | 87.32 |
表4:BERT-Large预训练数据消耗和在8个任务上的平均GLUE微调得分。
| 案例 | 训练数据 | ImageNet Top-1 准确率 |
|---|---|---|
| (1) 基线 | 100% | 84.65 |
| (2) Random-LTD | 77.7% (1.3倍) | 84.70 |
表5:ViT在ImageNet上的微调结果。
| 案例 | 训练数据 | PTB PPL |
|---|---|---|
| (1) 基线 | 100% | 16.11 |
| (2) Random-LTD | 100% | 15.9 |
表6:GPT-2 350M在PTB任务上的微调结果。
组合数据效率技术以实现更多
课程学习和random-LTD技术是互补的。在DeepSpeed数据效率框架内部,我们无缝地组合了这两种技术,如上图2所示,其中课程学习有助于采样下一个数据批次,而random-LTD有助于决定如何在模型内部路由每个采样数据。DeepSpeed数据效率解决了组合这两种技术时的几个复杂性,因此用户可以轻松地将每种技术或两者都应用于其训练管道。DeepSpeed数据效率的可组合性也普遍适用于数据采样和路由技术,从而提供了一个平台来实现和组合额外的数据效率技术。
组合后的DeepSpeed数据效率解决方案利用了两种数据效率技术,并实现了更好的数据和训练效率。以GPT-3预训练任务为例,结合CL和random-LTD,使用100%数据,在我们的实验中获得了最佳模型质量(表7案例(1)到(4))。当使用50%数据进行预训练时,基线训练导致零样本和10样本评估准确率下降,而单独使用CL或random-LTD只能恢复部分10样本准确率的损失。另一方面,组合后的数据效率解决方案在100%数据下实现了与基线相同或更好的准确率结果,展示了2倍的数据和2倍的时间节省(案例(5)到(8))。在应用于BERT预训练时,也观察到了类似的益处,例如2倍的数据节省。
| 案例 | 预训练数据 | 预训练时间(在64块V100上) | 平均0样本准确率 | 平均10样本准确率 |
|---|---|---|---|---|
| (1) 基线 | 300B | 260小时 | 42.5 | 44.0 |
| (2) CL 最佳度量 | 300B | 259小时 | 43.6 | 44.9 |
| (3) random-LTD | 300B | 263小时 | 43.7 | 44.9 |
| (4) CL + random-LTD | 300B | 260小时 | 43.8 | 45.1 |
| (5) 基线 | 150B (2倍) | 130小时 (2倍) | 42.0 | 42.7 |
| (6) CL 最佳度量 | 150B (2倍) | 129小时 (2倍) | 42.6 | 43.7 |
| (7) random-LTD | 150B (2倍) | 131小时 (2倍) | 42.7 | 43.5 |
| (8) CL + random-LTD | 150B (2倍) | 130小时 (2倍) | 42.8 | 44.0 |
表7:GPT-3 1.3B预训练数据/时间消耗和在19个任务上的平均评估准确率。
总结
我们非常高兴能与社区分享DeepSpeed数据效率库,并期待根据您的反馈进行改进。请在DeepSpeed GitHub和网站上查找代码、教程和文档。如需更多技术细节,请阅读我们的Random-LTD论文和DeepSpeed数据效率论文。我们相信,我们可组合的库和新颖的数据效率技术将帮助用户在保持模型质量的同时降低训练成本,或在相似成本下实现更好的质量。我们希望DeepSpeed数据效率能够成为一个平台,激励并加速未来在深度学习数据效率方面的研究。