DeepSpeed-MII:在24,000+开源DL模型上实现即时加速,推理成本降低高达40倍
深度学习 (DL) 开源社区在过去几个月里取得了巨大的发展。诸如 Bloom 176B 这样极其强大的文本生成模型,或 Stable Diffusion 这样的图像生成模型,现在通过 Hugging Face 等平台,任何拥有少量甚至单个 GPU 的人都可以使用。虽然开源使 AI 能力的获取变得民主化,但其应用仍受到两个关键因素的限制:1) 推理延迟和 2) 成本。
在 DL 模型推理的系统优化方面取得了显著进展,可以大幅降低延迟和成本,但这些优化并不容易获取。造成这种可访问性受限的主要原因是 DL 模型推理领域的多样性,模型在大小、架构、系统性能特征、硬件要求等方面各不相同。识别适用于给定模型的适当系统优化集并正确应用它们,往往超出了大多数数据科学家的能力范围,使得低延迟和低成本推理在很大程度上难以实现。
DeepSpeed 模型推理实现 (MII) 是 DeepSpeed 发布的一个新的开源 Python 库,旨在使强大模型的低延迟、低成本推理不仅可行,而且易于获取。
- MII 提供了对数千个广泛使用的 DL 模型的高度优化实现的访问。
- 与原始实现相比,MII 支持的模型实现了显著更低的延迟和成本。
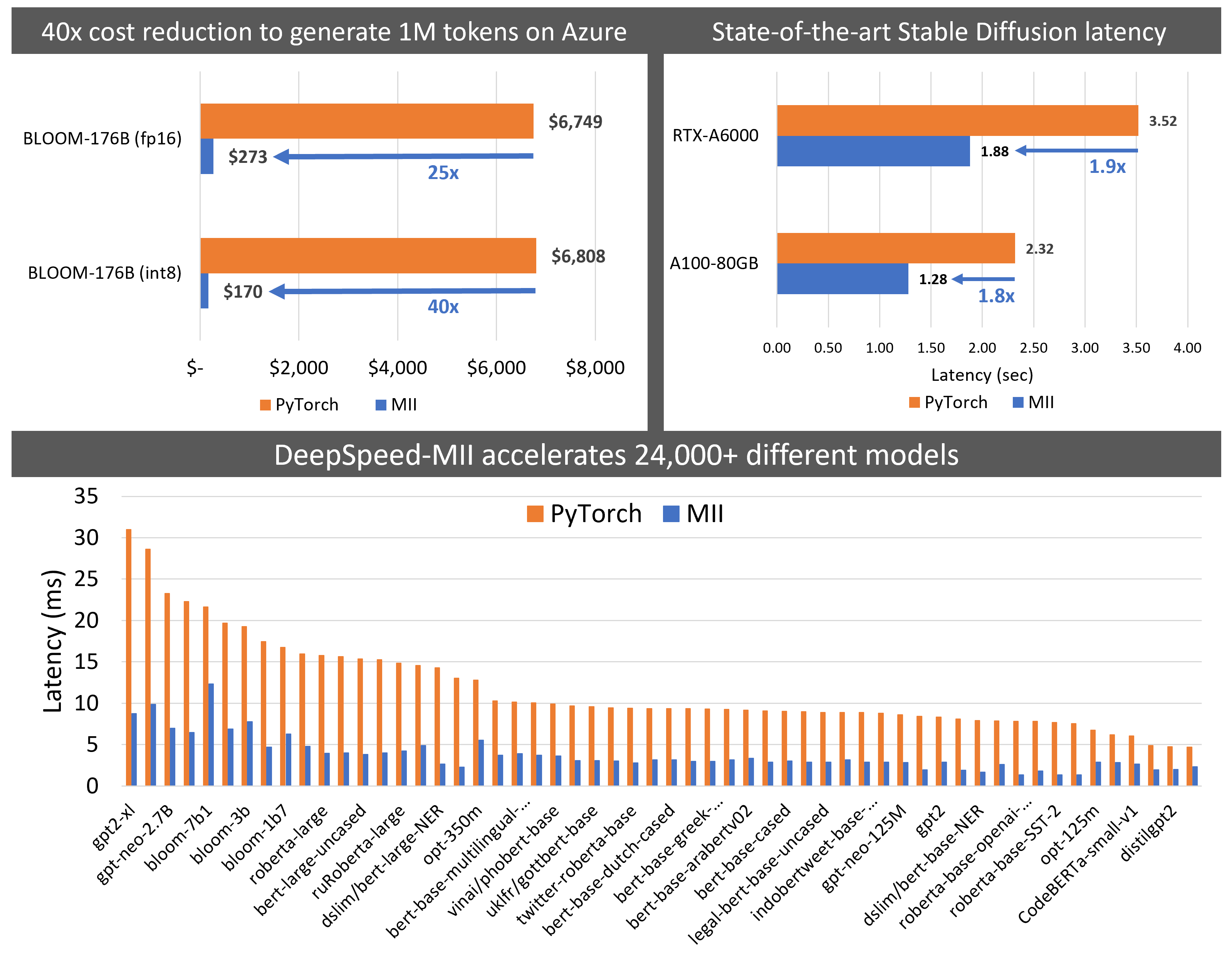
- MII 将 Big-Science Bloom 176B 模型的延迟降低了 5.7 倍,同时将成本降低了 40 倍以上,如图 2 (左) 和图 8 所示。
- MII 将部署 Stable Diffusion 的延迟和成本降低了 1.9 倍,如图 2 (右) 所示。
- 为了实现低延迟/成本推理,MII 利用了 DeepSpeed-Inference 的大量优化,例如用于 Transformer 的 deepfusion、用于多 GPU 推理的自动化 tensor-slicing、使用 ZeroQuant 进行即时量化,以及其他多项优化(详情请见下文)。
- 凭借最先进的性能,MII 仅需几行代码即可在本地和通过 AML 在 Azure 上低成本部署这些模型。
MII 如何工作?
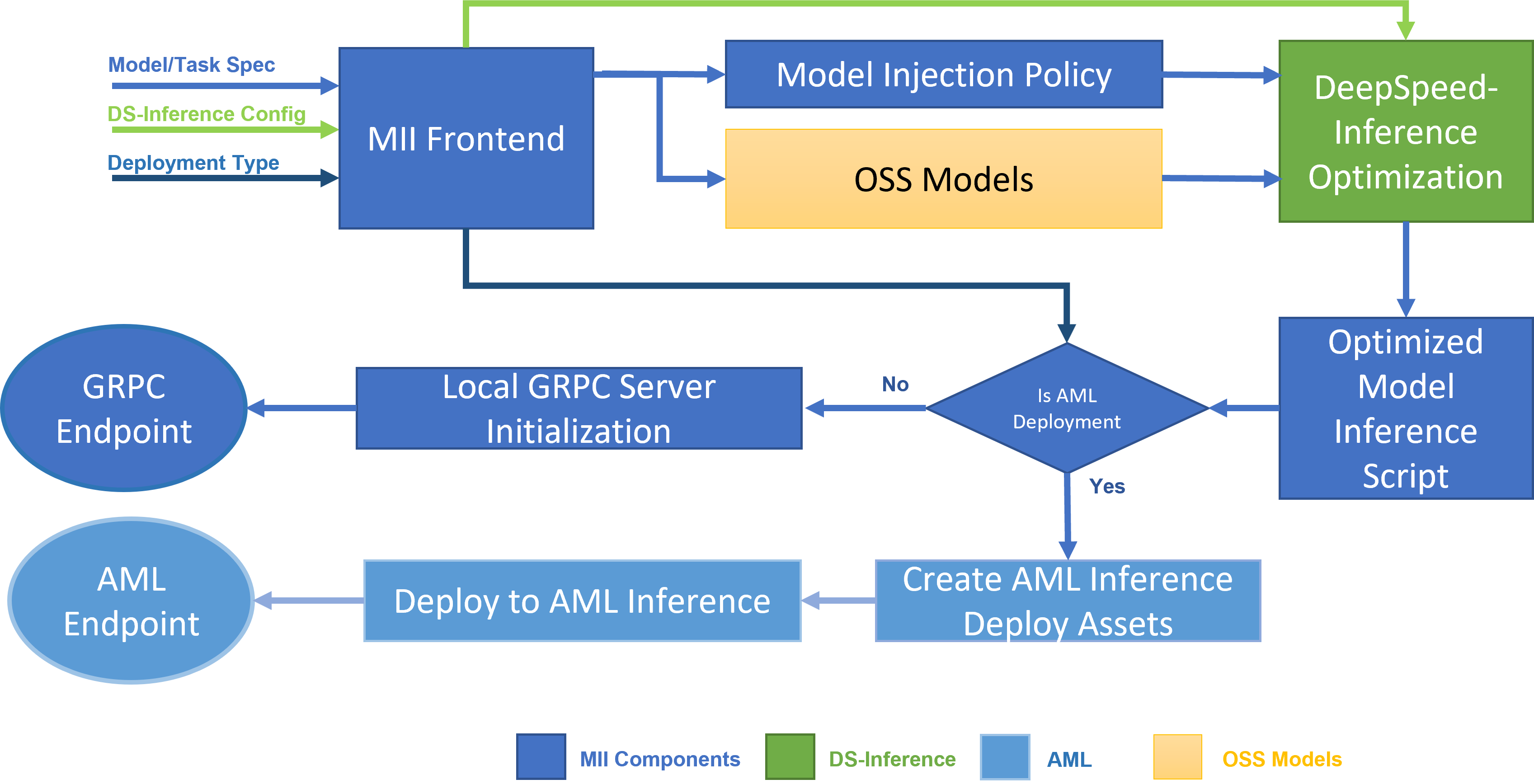
图 1:MII 架构图,展示了 MII 如何自动使用 DS-Inference 优化 OSS 模型,然后通过 GRPC 部署到本地,或通过 AML Inference 部署到 Microsoft Azure。
MII 的底层由 DeepSpeed-Inference 提供支持。根据模型类型、模型大小、批处理大小和可用硬件资源,MII 会自动应用 DeepSpeed-Inference 中适当的系统优化集,以最小化延迟并最大化吞吐量。它通过使用众多预设模型注入策略之一来实现这一点,该策略允许 MII 和 DeepSpeed-Inference 识别底层 PyTorch 模型架构并将其替换为优化实现(参见图 1)。通过这样做,MII 使 DeepSpeed-Inference 中广泛的优化自动可用于其支持的数千个流行模型。
支持的模型和任务
MII 支持越来越多的任务,例如文本生成、问答、文本分类等,涵盖通过 Hugging Face、FairSeq、EluetherAI 等多个开源模型仓库提供的数千种 Transformer 模型。它支持基于 BERT、RoBERTa、GPT、OPT 和 BLOOM 架构的密集模型,其大小从数亿参数到数百亿参数不等。同时,它还支持最新的图像生成模型,例如 Stable Diffusion。
有关 MII 支持的模型和任务的最新列表,请参阅 MII GitHub 仓库。
使用 MII 进行推理优化
这里我们总结了通过 MII 提供的 DeepSpeed-inference 的广泛优化集。有关更多详细信息,请参阅 [1, 2]
Transformer 的 DeepFusion: 对于基于 Transformer 的模型,如 Bert、Roberta、GPT-2 和 GPT-J,MII 利用 DeepSpeed-Inference 中的 Transformer 内核,这些内核经过优化,可在小批处理大小下实现低延迟,在大批处理大小下使用 DeepFusion 实现高吞吐量。
使用张量切片的多 GPU 推理: 对于像 Bloom 176B 这样的大型模型,MII 会自动启用节点内的张量并行,以利用多个 GPU 的聚合内存带宽和计算能力,从而实现比目前任何其他可用方案更低的延迟和更高的吞吐量。
使用 ZeroQuant 的 INT8 推理: 对于具有数百亿或数千亿参数的大型模型,MII 支持使用 ZeroQuant 的 INT8 推理。使用此功能不仅可以减少内存占用和推理所需的 GPU 数量,还可以通过支持更大的批处理大小和使用 INT8 计算来提高推理吞吐量,从而与 FP16 相比降低成本。
针对资源受限系统的 ZeRO-Inference: 像 Bloom 176B 这样的模型,即使有 INT8 支持,也需要超过 176 GB 的内存才能容纳模型本身。在缺乏部署此类模型所需的多个 GPU 的聚合 GPU 内存的情况下,MII 启用了 ZeRO-Inference,该功能可以利用系统 CPU 内存,仅用一个内存有限的 GPU 来部署这些大型模型。
编译器优化: 在适用情况下,除了上述优化之外,MII 还会自动通过 TorchScript、nvFuser 和 CUDA graph 应用基于编译器的优化,以进一步降低延迟并提高吞吐量。
MII-Public 和 MII-Azure
MII 可以与 DeepSpeed-Inference 的两种变体协同工作。第一种,称为 ds-public,包含上述大多数优化,也可通过我们的开源 DeepSpeed 库获取。第二种,称为 ds-azure,与 Azure 集成更紧密,并通过 MII 提供给所有 Microsoft Azure 客户。我们将运行这两种 DeepSpeed-Inference 变体的 MII 分别称为 MII-Public 和 MII-Azure。
与开源 PyTorch 实现 (基线) 相比,MII-Public 和 MII-Azure 都提供了显著的延迟和成本降低。然而,对于某些生成式工作负载,它们可能具有差异化的性能:MII-Azure 提供了超越 MII-Public 的进一步改进。我们将在下一节中量化这两种变体的延迟和成本降低。
量化延迟和成本降低
推理工作负载可以是延迟敏感型,其主要目标是最小化延迟;也可以是成本敏感型,其主要目标是最小化成本。在本节中,我们量化了在延迟敏感型和成本敏感型场景中使用 MII 的好处。
延迟关键场景
对于通常使用小批处理大小(1)的延迟敏感场景,MII 可以将各种开源模型在多个任务上的延迟降低多达 6 倍。更具体地说,我们展示了模型延迟降低情况1:
-
对于使用大型模型(如 Big Science Bloom、Facebook OPT 和 EluetherAI NeoX)进行文本生成的多 GPU 推理,速度提升高达 5.7 倍(图 2 (左))
-
使用 Stable Diffusion 进行图像生成任务时,速度提升高达 1.9 倍(图 2 (右))
-
对于基于 OPT、BLOOM 和 GPT 架构的相对较小的文本生成模型(多达 7B 参数),在单个 GPU 上运行时,速度提升高达 3 倍(图 3 和图 4)
-
使用基于 RoBERTa 和 BERT 的模型进行各种文本表示任务(如完形填空、文本分类、问答和 token 分类)时,速度提升高达 9 倍(图 5 和图 6)。
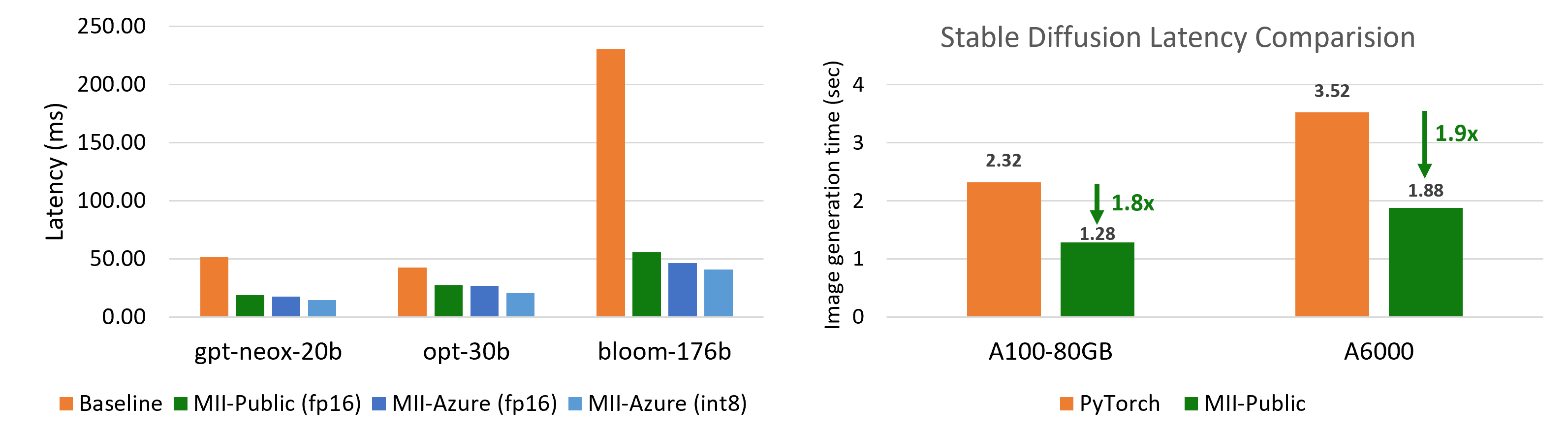 图 2:(左)大型模型的最佳可实现延迟。MII-Azure (int8) 比基线对于 Bloom-176B 提供 5.7 倍的更低延迟。(右)Stable Diffusion 文本到图像生成延迟比较。
图 2:(左)大型模型的最佳可实现延迟。MII-Azure (int8) 比基线对于 Bloom-176B 提供 5.7 倍的更低延迟。(右)Stable Diffusion 文本到图像生成延迟比较。
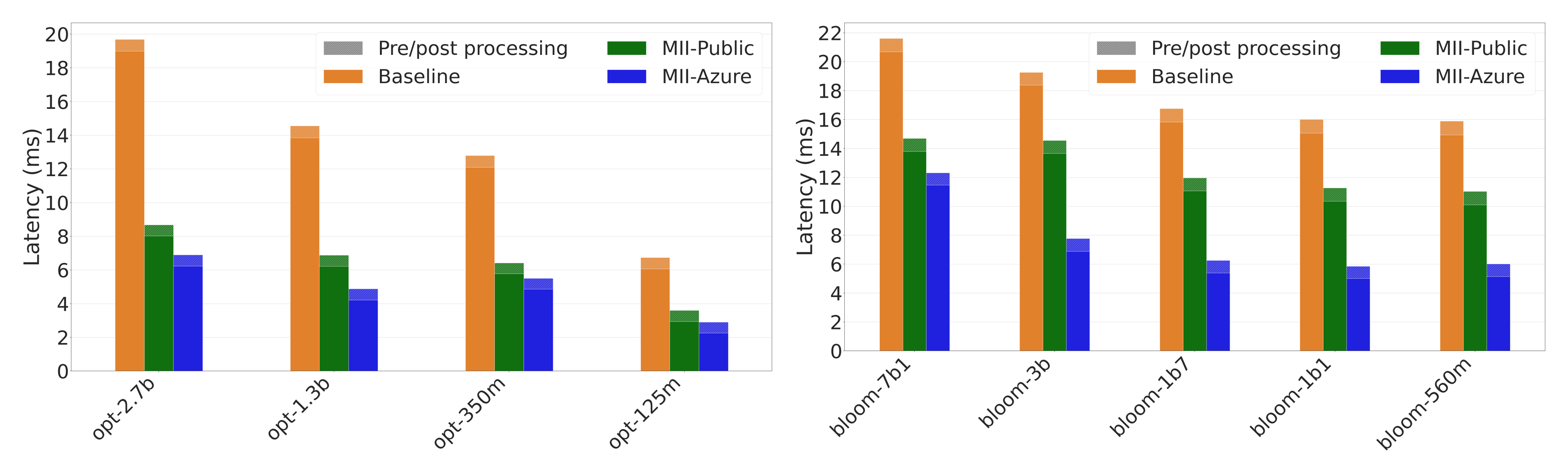 图 3:OPT 和 BLOOM 模型的延迟比较。MII-Azure 比基线快 2.8 倍。
图 3:OPT 和 BLOOM 模型的延迟比较。MII-Azure 比基线快 2.8 倍。
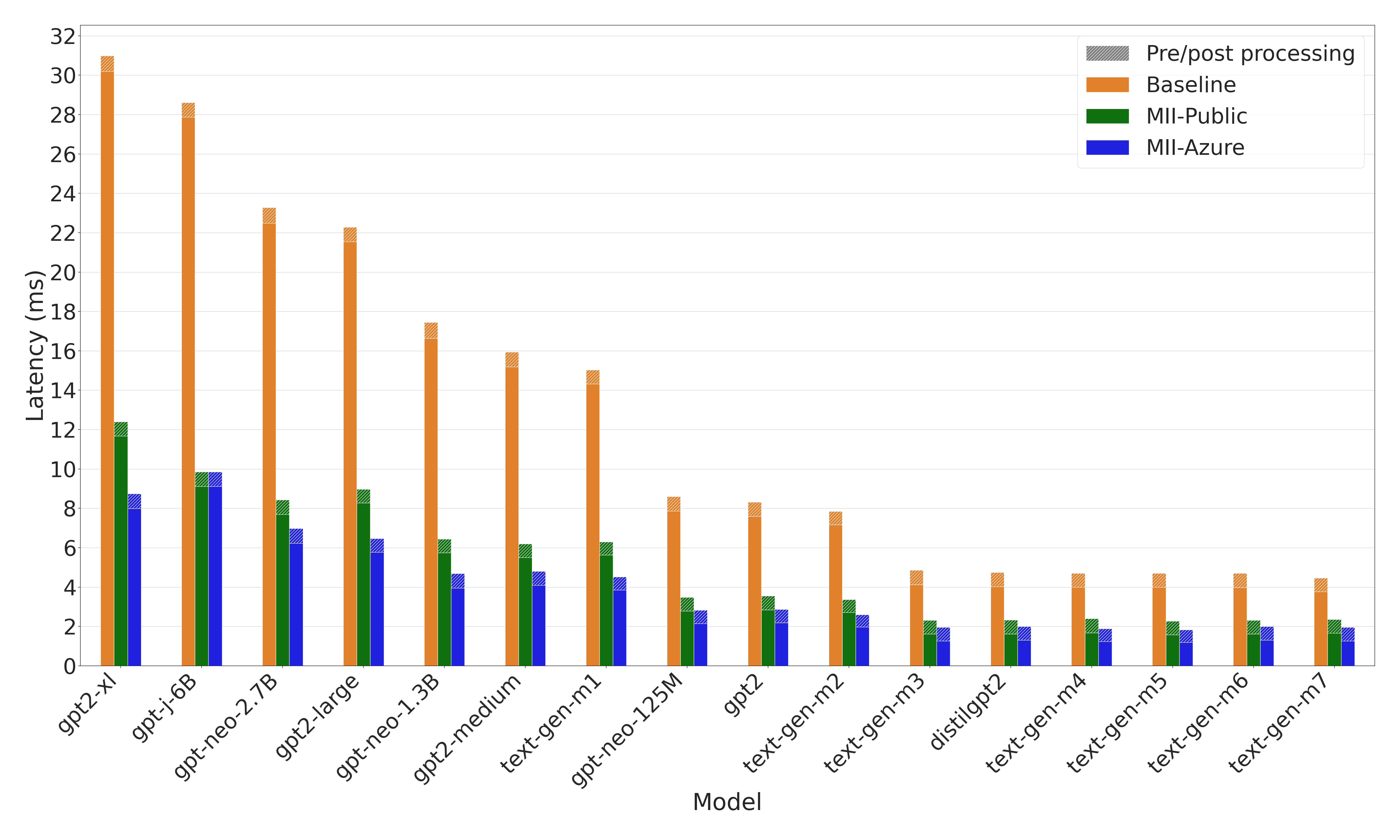 图 4:GPT 模型的延迟比较。MII-Azure 比基线快 3 倍。
图 4:GPT 模型的延迟比较。MII-Azure 比基线快 3 倍。
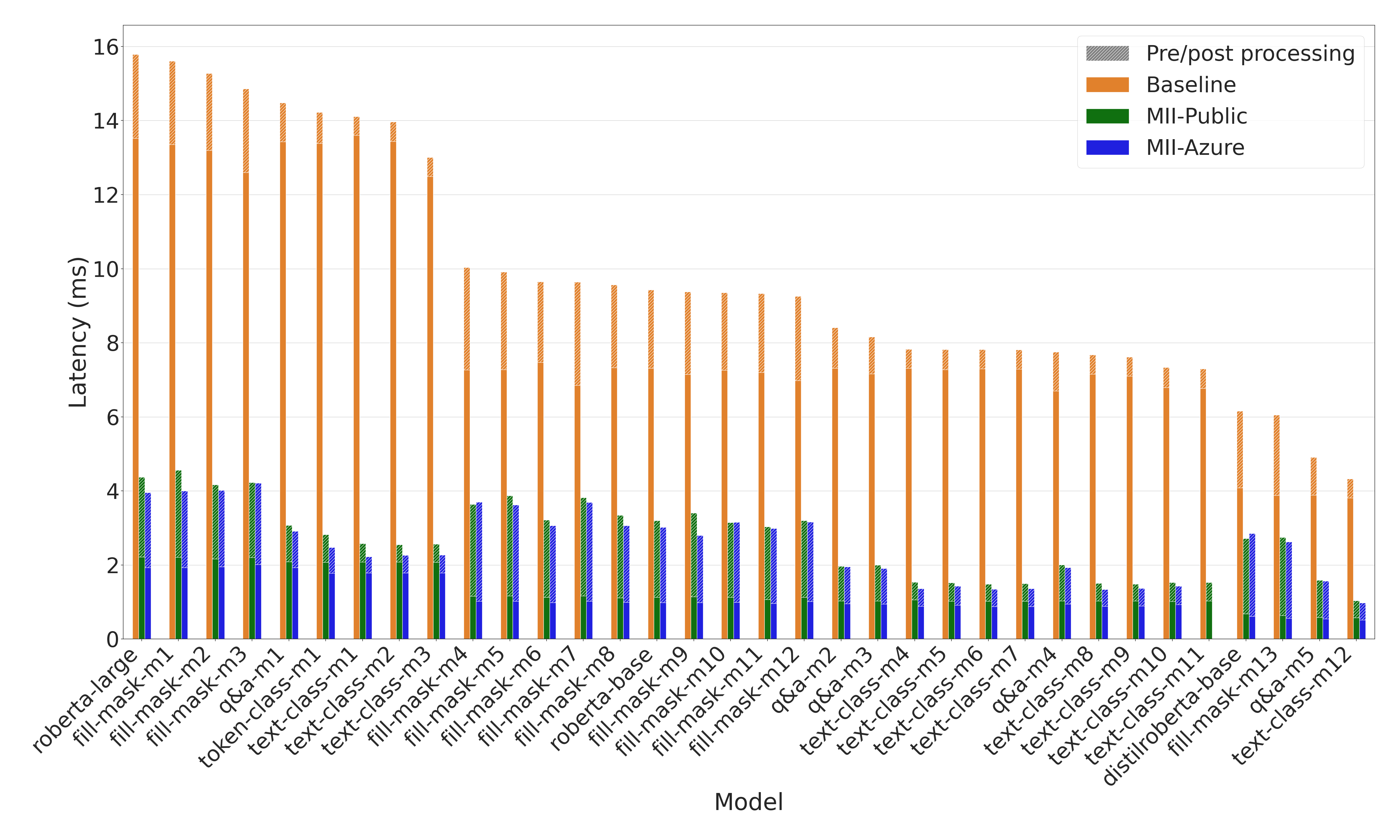 图 5:RoBERTa 模型的延迟比较。在多个任务和 RoBERTa 变体上,MII 提供了高达 9 倍的模型延迟降低和高达 3 倍的端到端延迟降低1。
图 5:RoBERTa 模型的延迟比较。在多个任务和 RoBERTa 变体上,MII 提供了高达 9 倍的模型延迟降低和高达 3 倍的端到端延迟降低1。
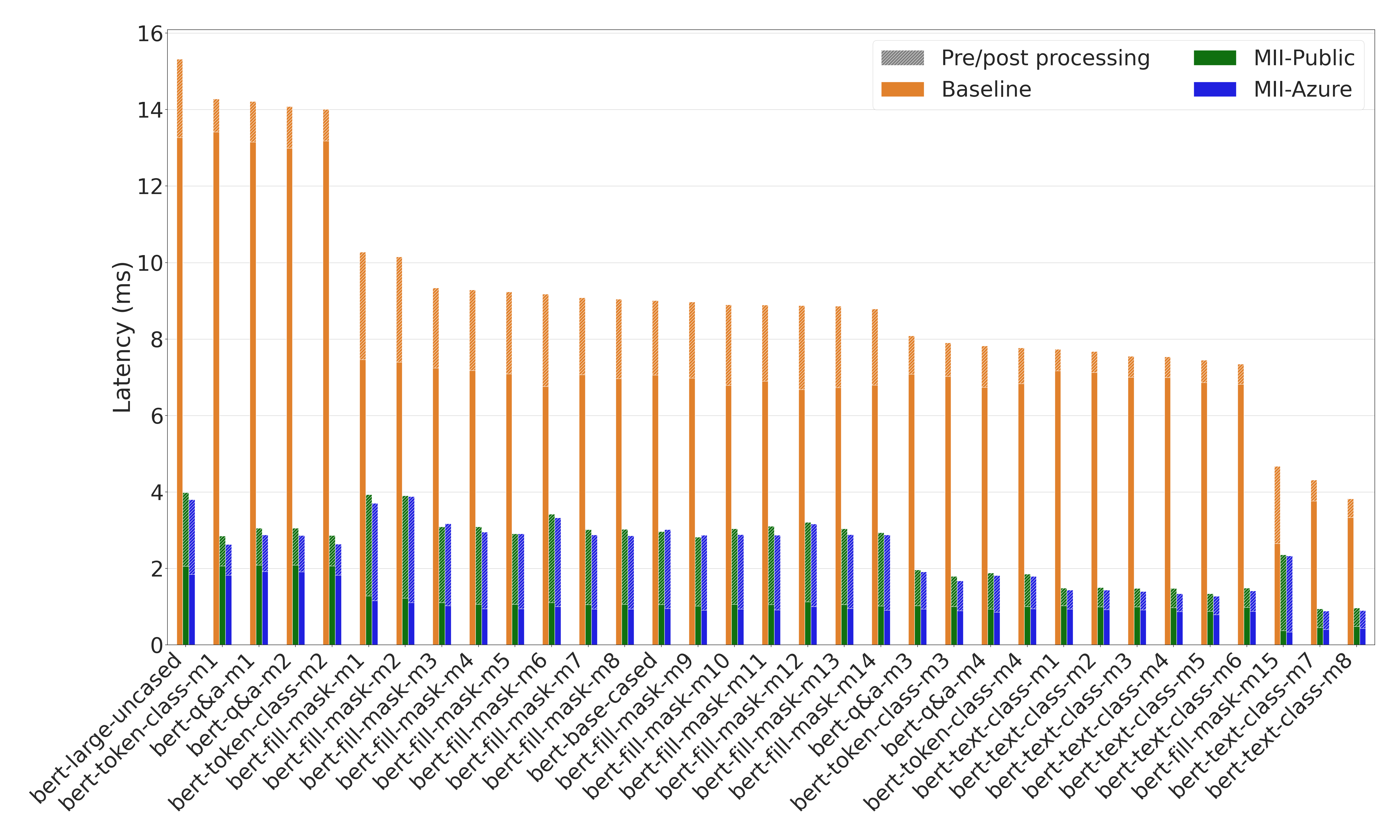 图 6:BERT 模型的延迟比较。MII 在多个任务和 BERT 变体上提供了高达 8.9 倍的模型延迟降低和高达 4.5 倍的端到端延迟降低1。
图 6:BERT 模型的延迟比较。MII 在多个任务和 BERT 变体上提供了高达 8.9 倍的模型延迟降低和高达 4.5 倍的端到端延迟降低1。
成本敏感场景
MII 可以显著降低 Bloom、OPT 等非常昂贵的语言模型的推理成本。为了获得最低成本,我们使用较大的批处理大小,以最大化基线和 MII 的吞吐量。这里我们使用两种不同的指标来衡量 MII 的成本降低:i) 每 GPU 每秒生成的 token 数,和 ii) 每百万 token 生成的美元成本。
图 7 和图 8 显示,与基线相比,MII-Public 的吞吐量分别提高了 10 倍以上,成本也降低了 10 倍以上。此外,MII-Azure 的吞吐量和成本比基线提高了 30 倍以上。
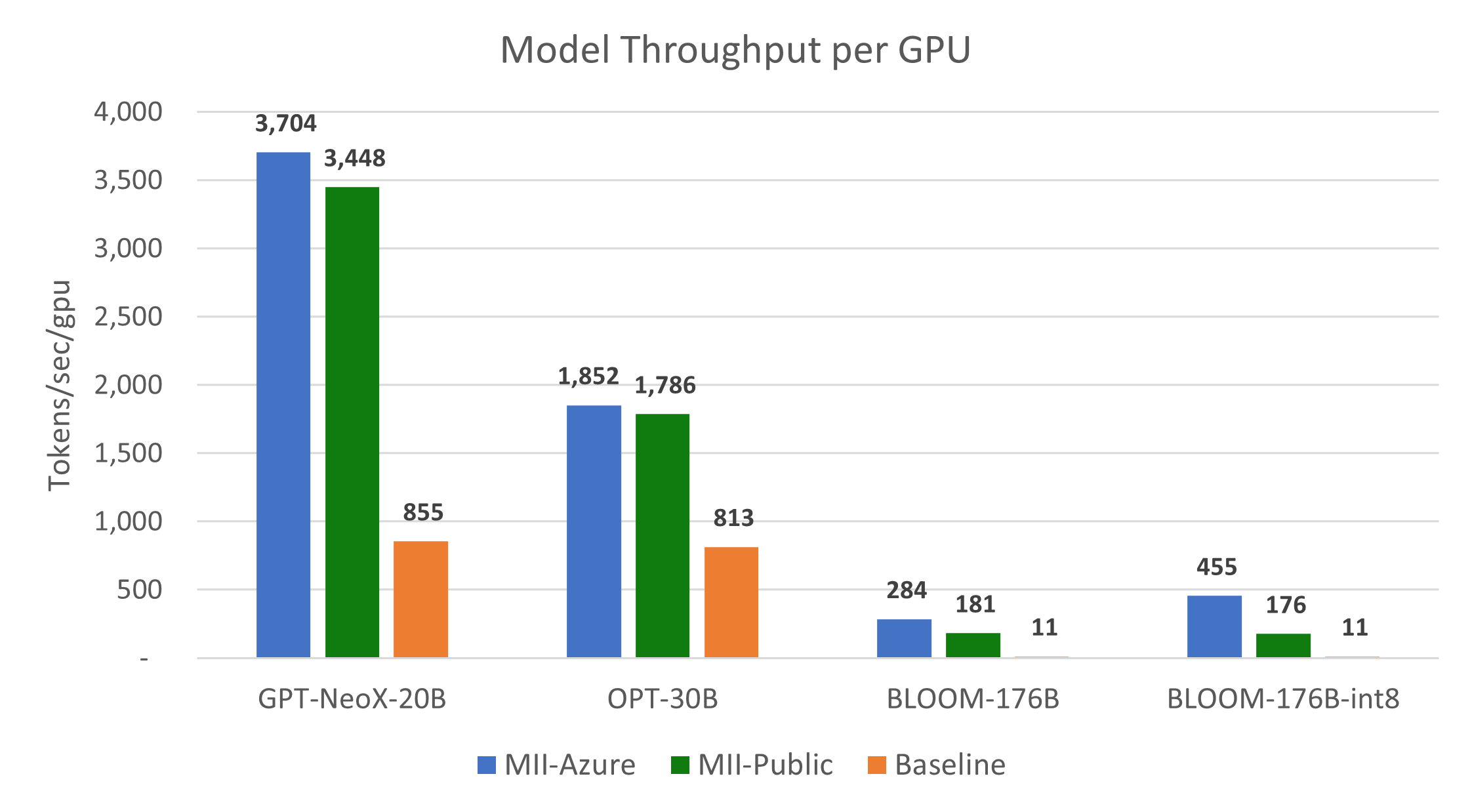 图 7:大型模型每 A100-80GB GPU 的吞吐量比较。MII-Public 提供了超过 15 倍的吞吐量提升,而 MII-Azure 提供了超过 40 倍的吞吐量提升。
图 7:大型模型每 A100-80GB GPU 的吞吐量比较。MII-Public 提供了超过 15 倍的吞吐量提升,而 MII-Azure 提供了超过 40 倍的吞吐量提升。
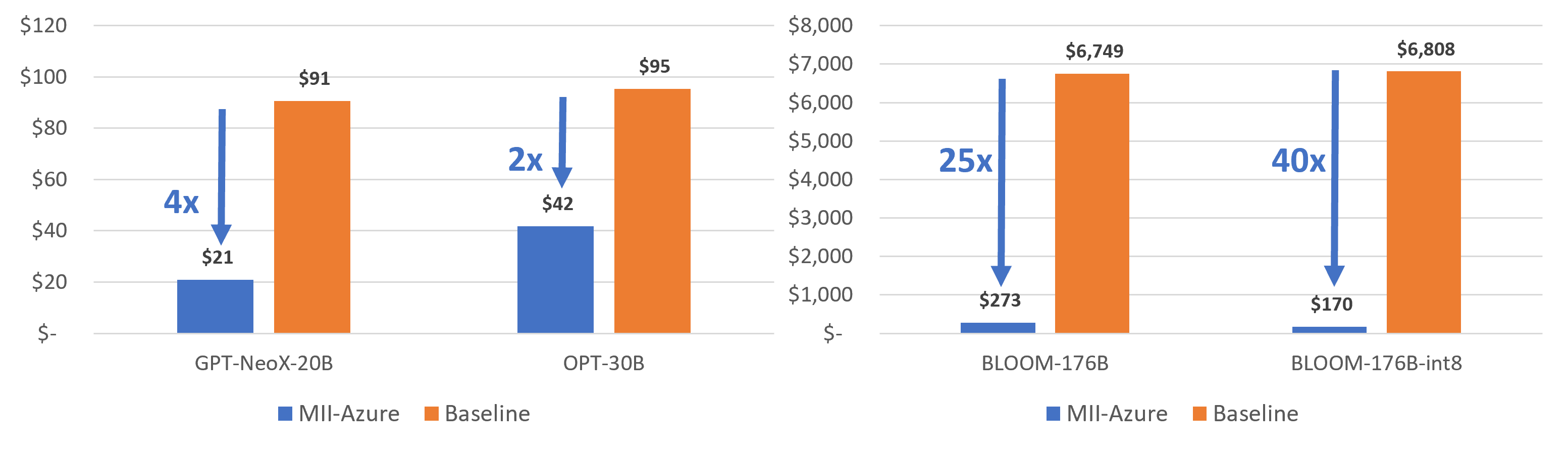 图 8:在 Azure 上生成 100 万个 token 的成本(针对不同模型类型)。MII-Azure 将生成成本降低了 40 倍以上。
图 8:在 Azure 上生成 100 万个 token 的成本(针对不同模型类型)。MII-Azure 将生成成本降低了 40 倍以上。
部署选项
MII 支持的模型可以通过两种不同的方式部署,如图 1 所示,只需几行代码。
MII-Public 部署
MII-Public 可以部署在本地或任何云产品上。MII 创建一个轻量级的 GRPC 服务器来支持这种部署形式,并提供一个 GRPC 推理端点用于查询。以下代码展示了如何使用 MII-Public 部署受支持的模型。
import mii
mii.deploy(task="text-to-image",
model="CompVis/stable-diffusion-v1-4",
deployment_name="sd-deployment")
MII-Azure 部署
MII 支持通过 AML Inference 在 Azure 上部署。为此,MII 为给定模型生成 AML 部署资产,这些资产可以使用 Azure-CLI 进行部署,如以下代码所示。此外,在 Azure 上部署允许 MII 利用 DeepSpeed-Azure 作为其优化后端,这比 DeepSpeed-Public 提供了更好的延迟和成本降低。
import mii
mii.deploy(task="text-to-image",
model="CompVis/stable-diffusion-v1-4",
deployment_name="sd-deployment",
deployment_type=DeploymentType.AML)
要了解有关这些部署选项的更多信息并开始使用 MII,请参阅 MII 入门指南。
总结
我们非常高兴能与社区分享 MII,并期待根据您的反馈进行改进。我们将继续在 MII 中增加对更多模型的支持,并增强 MII-Public 和 MII-Azure,以服务于本地和 Azure 用户。我们希望,尽管开源已经使强大的 AI 能力被许多人所获取,MII 将通过即时降低推理延迟和成本,使这些能力更广泛地融入到各种应用和产品中。
附录
下表显示了图 3、4、5 和 6 中使用的模型别名与实际模型名称之间的映射。