ZeRO-Inference:普及大规模模型推理
引言
当前人工智能(AI)领域(如图像、语音和自然语言)的趋势表明,通过增加模型大小可以提高模型质量。例如,在自然语言处理中,最先进(SOTA)模型在不到四年内从3亿参数(Bert-Large)增长到5000亿参数(Megatron-Turing-530B)。然而,模型规模的这种急剧增长显著增加了训练、微调或推理这些模型的GPU成本,使大多数用户无法承担。为了普及对AI创新的访问,Hugging Face (BigScience)、Meta 和 Yandex 等大型组织最近公开了预训练的大规模模型。不幸的是,即使是这些公开可用的模型也未能广泛使用,因为许多用户无法负担用于推理计算所需的数十个GPU。例如,Megatron-Turing-530B(自然语言领域的SOTA模型)的半精度推理计算至少需要40个A100-40GB GPU,这对于许多学生、模型科学家、爱好者和小型企业来说是负担不起的,尽管他们可以从使用这些强大的模型中受益。因此,一个真正令人担忧的问题是,如果模型规模的急剧增长持续下去,那么越来越多的用户可能会被排除在这些AI创新的益处之外。
作为微软“大规模AI”计划的一部分,DeepSpeed 开发了 ZeRO-Inference 技术来解决这些阻碍 AI 普及的障碍。ZeRO-Inference 源于 ZeRO 技术家族,这是一系列强大的内存和并行优化技术,用于在现代 GPU 集群上高效地进行大规模模型训练和推理。DeepSpeed 此前开发了 ZeRO-Infinity,这项技术利用异构内存(GPU、CPU 和 NVMe)将模型训练高效地扩展到极致水平。ZeRO-Inference 针对 GPU 上的模型推理,适配并优化了 ZeRO-Infinity 的技术,通过将模型权重托管在 CPU 或 NVMe 内存中,从而在 GPU 中不托管(零)任何权重。这种方法受到以下观察的启发:大多数商用计算设备(例如,笔记本电脑、台式机、工作站等)中 CPU 和 NVMe 内存的总容量达到太字节级别,足以托管已知最大的模型进行推理计算。通过利用这种非 GPU 内存,ZeRO-Inference 使得大规模模型(拥有数千亿参数)的推理计算可以在最少一个 GPU 上进行,从而使几乎所有人都能访问大规模模型推理。此外,通过使用显著更便宜的 CPU 或 NVMe 内存大幅降低 GPU 内存需求,它显著降低了大规模模型推理的成本,为 SOTA 模型提供了一条经济实惠的推理路径。
ZeRO-Inference 的工作原理
大型模型推理的巨大计算需求意味着需要像 GPU 这样的加速器才能高效执行。因此,在有限 GPU 预算下进行大型模型推理的一个重要设计决策是如何在模型权重、推理输入和中间结果之间分配 GPU 内存。
卸载所有模型权重
ZeRO-Inference 将整个模型权重固定在 CPU 或 NVMe(以足以容纳完整模型为准)中,并逐层将权重流式传输到 GPU 进行推理计算。计算完一层后,输出保留在 GPU 内存中作为下一层的输入,同时该层权重所消耗的内存被释放,供下一层使用。因此,模型推理时间由在 GPU 上计算层的时间和通过 PCIe 获取层的时间组成。对于大型模型推理,这种方法提供了扩展性和效率优势,如下所述。
ZeRO-Inference 通过两种方式提供扩展优势。首先,通过在任何时候只将一个(或几个)模型层保留在 GPU 内存中,ZeRO-Inference 显著减少了推理大规模模型所需的 GPU 内存量。对于当前拥有约一百层的 SOTA 模型(例如,GPT3-175B 和 Megatron-Turing-530B 分别有96层和105层),ZeRO-Inference 将 GPU 内存需求减少了高达两个数量级。例如,使用 ZeRO-Inference,Megaton-Turing-530B 进行半精度推理时的 GPU 内存消耗从1TB降至10GB。其次,通过将模型适配到比 GPU 内存便宜几个数量级的 CPU 或 NVMe 内存中,与将整个模型适配到 GPU 内存的方法相比,ZeRO-Inference 使未来 SOTA 模型(例如,拥有数万亿或数十万亿参数的模型)的扩展更加经济实惠。
尽管从 CPU 或 NVMe 通过 PCIe 互连获取模型权重存在延迟,ZeRO-Inference 仍能为吞吐量导向的推理应用提供高效计算。这主要是因为通过将模型的 GPU 内存使用限制到一层或几层权重,ZeRO-Inference 可以利用大部分 GPU 内存来支持大量输入令牌,形式为长序列或大批量大小。一个大型模型层需要大量的计算,尤其是在处理具有许多输入令牌的输入时。例如,GPT3-175B 的一层需要大约7 TFlops 来处理批量大小为1、序列长度为2048的输入。因此,对于具有长序列长度和大批量大小的推理场景,计算时间主导了获取模型权重的延迟,最终提高了效率。总而言之,ZeRO-Inference 利用 GPU 内存支持大量输入令牌的策略,为大型模型带来了高性能推理。
优化
为了进一步提高系统效率,ZeRO-Inference 利用另外两个优化来减少从 CPU 或 NVMe 内存到 GPU 内存获取层权重的延迟。
第一个优化涉及将层的获取与之前层的计算重叠,也称为层预取。层预取允许 ZeRO-Inference 隐藏预取层的部分传输延迟。当计算时间不够长或无法充分增加(例如,通过更大的批量大小)以主导获取层权重的延迟时,这尤其有用。
第二个优化适用于在多个 GPU 上进行推理,它通过使用每个 GPU 仅获取层的一部分来并行化每个层的获取。以这种方式利用 GPU 的聚合 PCIe 链路本质上是线性地增加了传输带宽,从而减少了延迟。通过这种方法,将层获取到 GPU 内存中分两个阶段进行。首先,每个 GPU 独立地通过 PCIe 将层的一部分获取到其内存中。此时,每个 GPU 上只驻留层的一个分区。接下来,每个 GPU 通过高带宽的 GPU-GPU 互连(例如 NVLink、xGMI 等)从其他 GPU 获取缺失的层部分,以组装完整的层进行计算。由于 GPU-GPU 互连带宽通常比 PCIe 带宽高一个数量级以上,因此高效的多 GPU 或多节点通信原语,如 NCCL 或 RCCL all-gather,可以用来高效地在所有 GPU 上组装完整的层,其延迟相对于 PCIe 延迟可忽略不计。
替代方法:在 GPU 内存中托管部分模型权重
ZeRO-Inference 的一种替代方法是将尽可能多的模型权重固定在 GPU 内存中,并在计算需要时从(CPU 或 NVMe)获取其余部分。这种方法的一个好处是避免了获取已经固定在 GPU 内存中的权重的延迟。然而,这种方法有两个缺点:(i) 对于千亿参数模型,延迟节省可以忽略不计,因为只有一小部分权重可以适应 GPU 内存;(ii) 即使模型权重的相当一部分可以适应(例如,对于约100亿参数的模型,大于50%),剩余的 GPU 内存也只能适应小批量大小,这会损害推理吞吐量。我们将在后面展示评估结果,以证明这种方法是次优的。
单 GPU 上的模型扩展
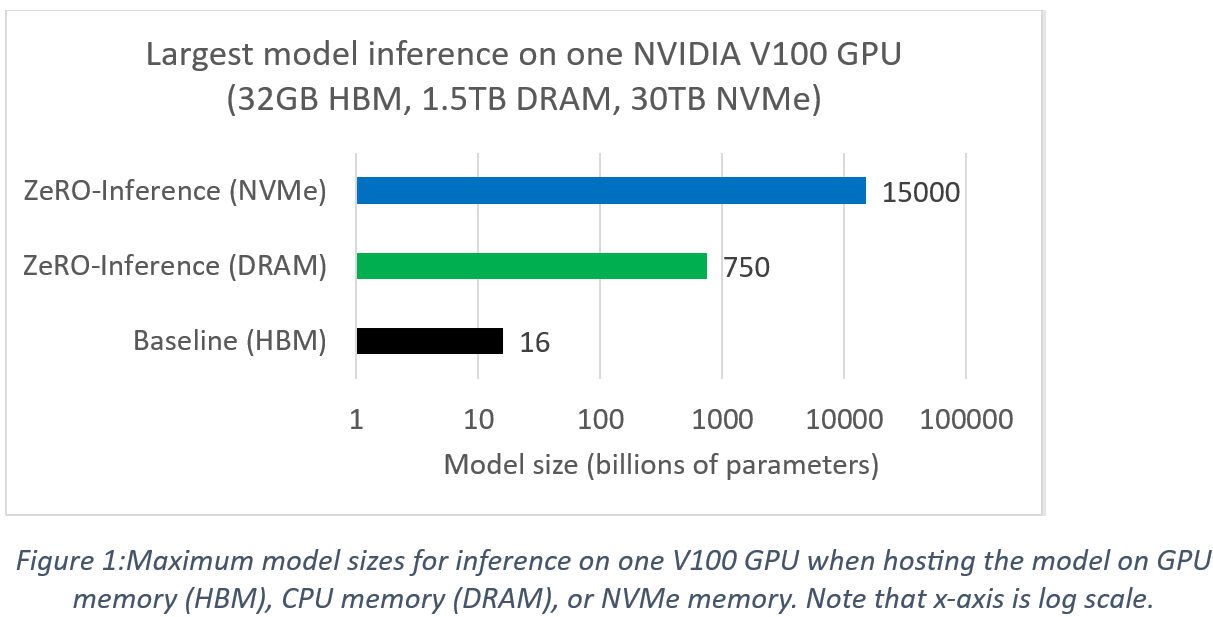
与将模型托管在 GPU 内存(即 HBM)中的基线方法相比,ZeRO-Inference 在单个 GPU 上实现了显著的模型推理扩展。例如,我们考虑在 NVIDIA DGX2 系统中使用单个 NVIDIA Tesla V100 GPU 进行半精度模型推理。虽然 V100 GPU 具有32GB内存,但该系统配备了1.5TB的 CPU DRAM 和30TB的 NVMe 存储。GPU 推理计算支持的最大模型大小取决于模型所托管的内存。下面的图1显示了在该系统中,使用 ZeRO-Inference 进行 GPU 推理时可实现的模型规模。相比之下,基线方法无法支持大于160亿参数的模型进行 GPU 推理1。与此相反,ZeRO-Inference 具有将模型托管到 HBM 以外的不同内存(DRAM 或 NVMe)的灵活性。这种灵活性使得 ZeRO-Inference 能够支持比基线方法大得多的模型。例如,通过将模型托管在 NVMe 内存上,ZeRO-Inference 可以支持高达15万亿参数的模型进行 GPU 推理,这比基线方法大近千倍。图1的一个实际启示是,ZeRO-Inference 使得当前 SOTA 模型(因为它们小于15万亿参数)可以在单个 GPU 上进行推理计算。
令牌生成性能
一项重要的推理工作负载是基于输入提示的令牌生成。在此工作负载中,模型接收文本序列作为输入提示,并根据此提示生成可配置长度的输出文本。我们使用此工作负载来演示 ZeRO-Inference 的性能。该工作负载包含两个阶段:(1) 提示处理阶段,模型处理输入提示;(2) 生成阶段,模型生成输出令牌。
ZeRO-Inference 旨在用于吞吐量导向的推理应用,因此我们为此工作负载使用的性能指标是生成阶段每秒生成的令牌数。在我们的实验中,我们使用 Hugging Face 令牌生成流水线,测量在给定四个令牌的输入提示下,使用贪婪搜索算法生成十个输出令牌的性能。实验中的生成流水线使用了 KV 缓存优化,通过缓存已生成的令牌来避免重新计算,从而提高性能。我们考虑了 ZeRO-Inference 设计选择和优化的三个方面对性能的影响:(1) 完全卸载模型权重而非部分卸载,(2) 在使用前预取层权重,以及 (3) 使用多个 GPU 并行化通过 PCIe 获取层。此外,我们测量了改变输出令牌数量对性能的影响。
模型
在我们的实验中,我们使用了表1中列出的三个公开可用的巨型语言模型。我们将这些模型配置为半精度推理计算。由于这些模型比 GPU 内存大,因此在单个 V100-32GB 上进行推理需要 ZeRO-Inference。

模型权重的完全卸载与部分卸载
ZeRO-Offload 中的一个关键设计选择是完全卸载大于 GPU 内存的模型权重,而不是在 GPU 内存中托管部分权重。我们对此方法的直觉是,对于吞吐量导向的推理应用,完全卸载所实现的更大批量大小比部分卸载能带来更好的性能。在表2中,我们展示了 OPT-30B 在单个 V100-32GB 上进行令牌生成的结果,比较了模型权重的完全卸载与在 GPU 内存中托管一部分(即100亿和120亿参数2)。结果表明,完全卸载在 CPU 内存(每秒43个令牌)和 NVMe 内存(每秒30个令牌)上都提供了最佳性能。对于 CPU 和 NVMe 内存,完全卸载比部分卸载180亿和200亿参数分别快1.3倍和2.4倍以上。完全卸载的性能优势来自于更大的批量大小,这与部分卸载选项形成对比。因此,当模型不适合 GPU 时,使用 GPU 内存来增加批量大小而非部分适应模型会导致更快的令牌生成。

预取层权重
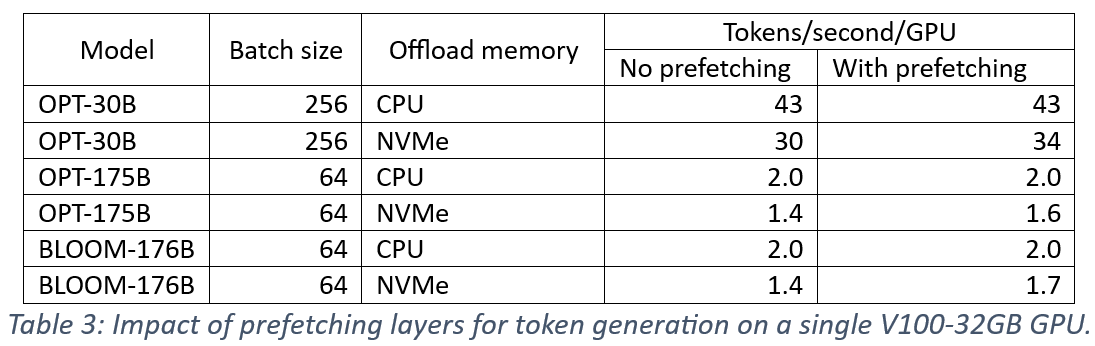
ZeRO-Inference 在使用前预取层,与当前层计算重叠,以隐藏层传输延迟。我们测量了预取对单个 V100-32GB 上令牌生成性能的影响,结果总结在表3中。我们观察到预取并未改善 CPU 卸载。这是因为令牌生成中相对较短的序列(即少于50个令牌)导致层计算时间不足以隐藏 CPU 层获取时间的大部分。相比之下,预取将 OPT-30B、OPT-175B 和 BLOOM-176B 的 NVMe 卸载性能分别提高了1.13倍、1.14倍和1.21倍。这是因为从 NVMe 经由 CPU 内存传输权重,使得预取能够将从 CPU 到 GPU 内存的传输与从 NVMe 到 CPU 的传输重叠,从而提高了有效传输带宽。
在多个 GPU 上并行化层获取
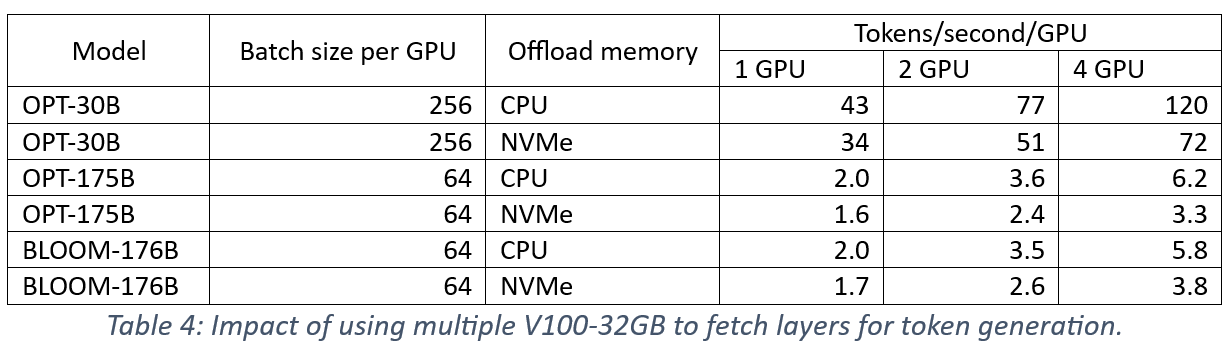
ZeRO-Inference 利用 GPU 和 CPU 内存之间的四个 PCIe 互连来并行化层获取,从而在多个 GPU 上实现更快的推理计算。在表4中,我们报告了在两个和四个 GPU 上进行令牌生成相对于单个 GPU 的吞吐量改进3。这些结果是在启用层预取的情况下收集的。报告的吞吐量数字是每个 GPU 的,表明随着聚合 PCIe 链路减少层获取延迟,每个 GPU 上的令牌生成速度变得更快。改进的每个 GPU 吞吐量转化为超线性扩展性能。此外,这些结果表明未来 PCIe 代的带宽改进有助于提高 ZeRO-Inference 的性能。
生成输出长度的影响
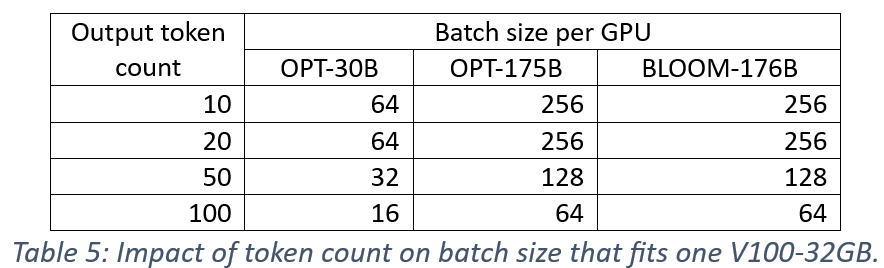
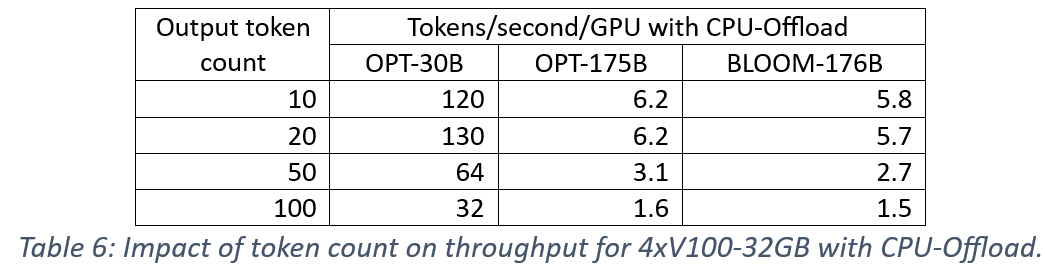
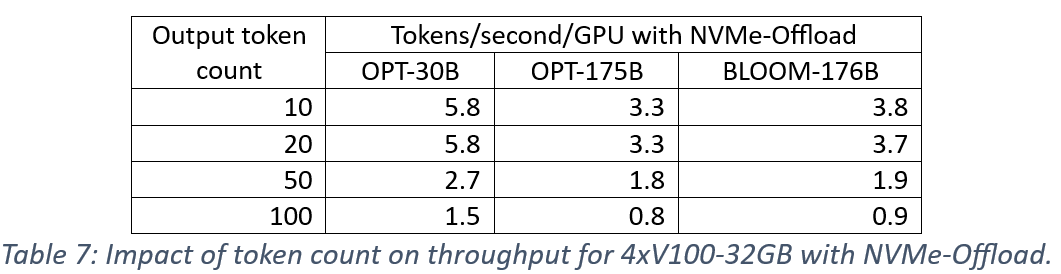
我们测量了输出令牌数量对性能的影响,因为 KV 缓存优化的内存开销随着输出令牌长度的增加而增加,并可能限制批量大小。首先,我们考虑令牌长度为10、20、50和100对单个 V100-32GB GPU 可容纳的批量大小的影响。表5中的结果显示,当令牌数量增加5倍(与基线数量10相比)时,批量大小减少了2倍。
接下来,我们测量了使用四个 V100-32GB GPU 对生成吞吐量的影响。结果在表6中为 CPU 卸载,在表7中为 NVMe 卸载。我们观察到对模型和卸载内存都一致的影响,即增加输出令牌数量会使吞吐量与批量大小的减少成比例地降低。这些结果也证明了大批量大小对于 ZeRO-Inference 性能的重要性。
使用 ZeRO-Inference
我们简要讨论用户如何判断 ZeRO-Inference 是否适合其应用,以及如何在 DeepSpeed 中启用 ZeRO-Inference。
何时使用 ZeRO-Inference
ZeRO-Inference 专为需要 GPU 加速但缺少足够 GPU 内存来托管模型的推理应用而设计。此外,ZeRO-Inference 针对吞吐量导向并允许大批量大小的推理应用进行了优化。其他技术,例如 Accelerate、DeepSpeed-Inference 和 DeepSpeed-MII,它们将整个模型(可能使用多个 GPU)放入 GPU 内存中,更适合对延迟敏感或批量大小较小的推理应用。
如何使用 ZeRO-Inference
ZeRO-Inference 在 DeepSpeed 库版本 >= 0.6.6 中可用。将 ZeRO-Inference 集成到令牌生成流水线中,例如 Hugging Face generate,需要更新 DeepSpeed 配置,将 ZeRO 优化设置为 stage 3,并将参数卸载设置为 CPU 或 NVMe。
以下是启用 ZeRO-Inference 并卸载到 CPU 内存的配置片段。
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
...
},
...
}
以下是将数据卸载到挂载在“/local_nvme”的 NVMe 设备的配置片段。
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme",
...
},
...
}
结论
AI 技术最近的进步主要源于模型规模的极致扩展。然而,极致的模型扩展也使得训练和推理的硬件成本高昂,除了最大的组织外,其他大多数都望而却步,严重限制了对 AI 创新的访问。为了帮助普及 AI,我们开发了 ZeRO-Inference,这项技术使得大规模模型的推理计算可以在最少单个 GPU 上进行。ZeRO-Inference 通过将模型托管在 CPU 或 NVMe 内存中,并将模型层流式传输到 GPU 内存进行推理计算,从而降低了 SOTA 模型推理的 GPU 成本。ZeRO-Inference 补充了大型组织公开 SOTA 预训练模型以实现 AI 普及的努力,确保这些模型的推理计算对大多数用户(例如,学生、爱好者、模型科学家等)来说是经济实惠的。
致谢
DeepSpeed 团队感谢 Stas Bekman 预览此博客并提供宝贵的反馈。