Azure 利用 DeepSpeed 助力易用、高性能和超大规模模型训练
简介
近年来,在大量数据上训练的大规模基于 Transformer 的深度学习模型在多项认知任务中取得了巨大成果,并支持了增强人类能力的新产品和功能。在过去的五年中,这些模型的规模增长了数个数量级。从最初的 Transformer 模型的几百万参数,一直到最新的 5300 亿参数的 Megatron-Turing 模型,如图 1 所示。客户对以空前规模训练和微调大型模型的需求日益增长。
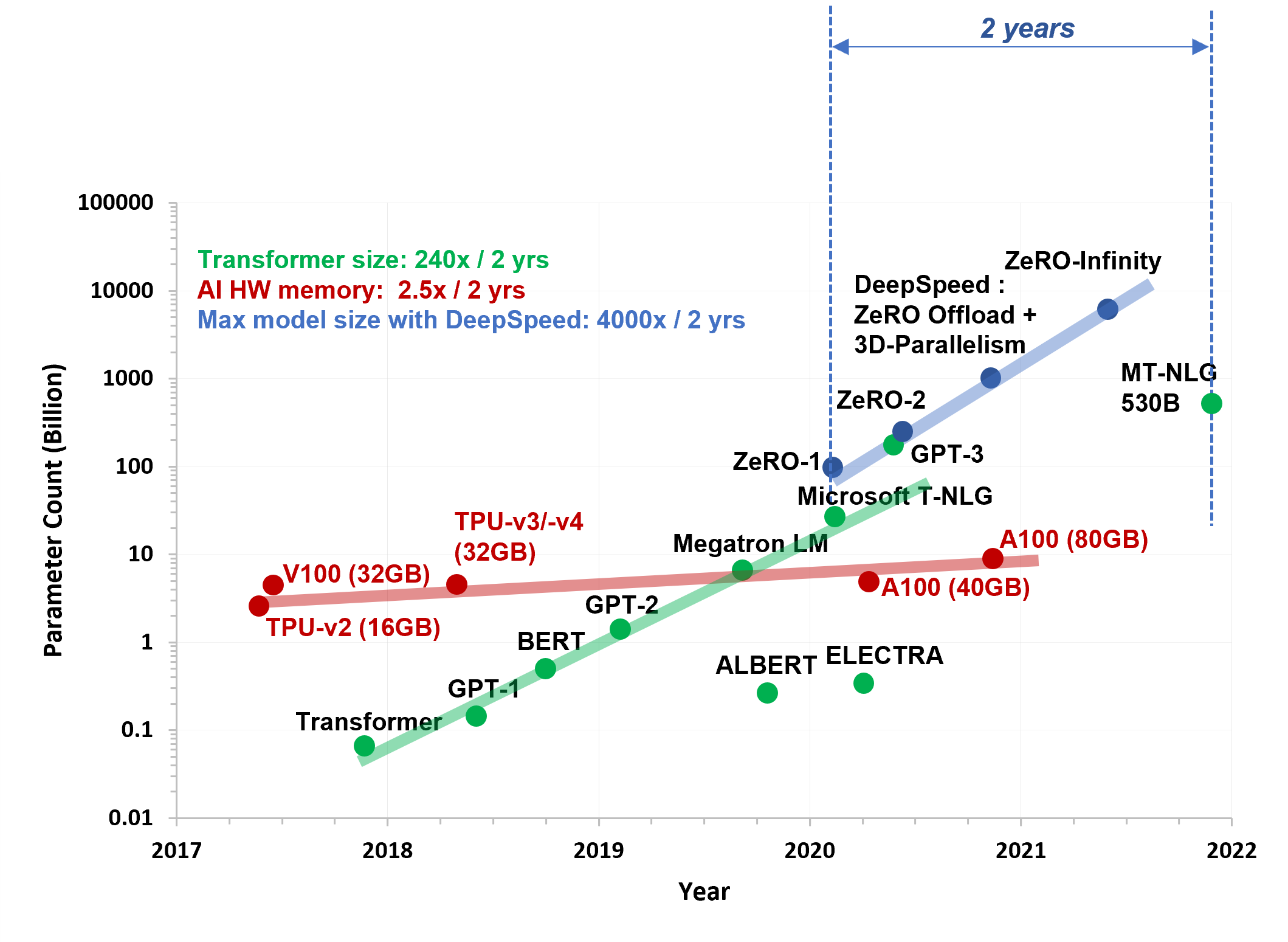
图 1:大型模型和硬件能力的图景
为了训练这些模型,用户需要设置和维护一个复杂的分布式训练基础设施,这通常需要多个手动且易错的步骤。这导致了在使用性和性能方面都不尽如人意的体验。我们最近宣布了我们如何在简化此过程方面取得重大进展,以在 Azure 上实现 1K+ GPU 规模的易用且高性能训练。
在这篇扩展文章中,我们分享了 DeepSpeed 用户如何在 Azure 上通过全新易用、精简、可扩展且高性能的分布式训练体验来训练万亿参数模型的详细信息。我们还分享了实验设置、模型配置、额外的性能趋势的详细信息,并指导用户如何在自己的环境中运行这些实验。
在 Azure 上使用 DeepSpeed 使分布式训练更快、更简单
我们将在图 2 中比较 DeepSpeed 在 Azure 上现有的手动且易错的工作流程与我们提出的易用工作流程。客户现在可以使用易用的训练管道来大规模启动训练作业。如果用户依赖推荐的 AzureML 配置,新工作流程将步骤数从 11 个减少到仅 1 个。
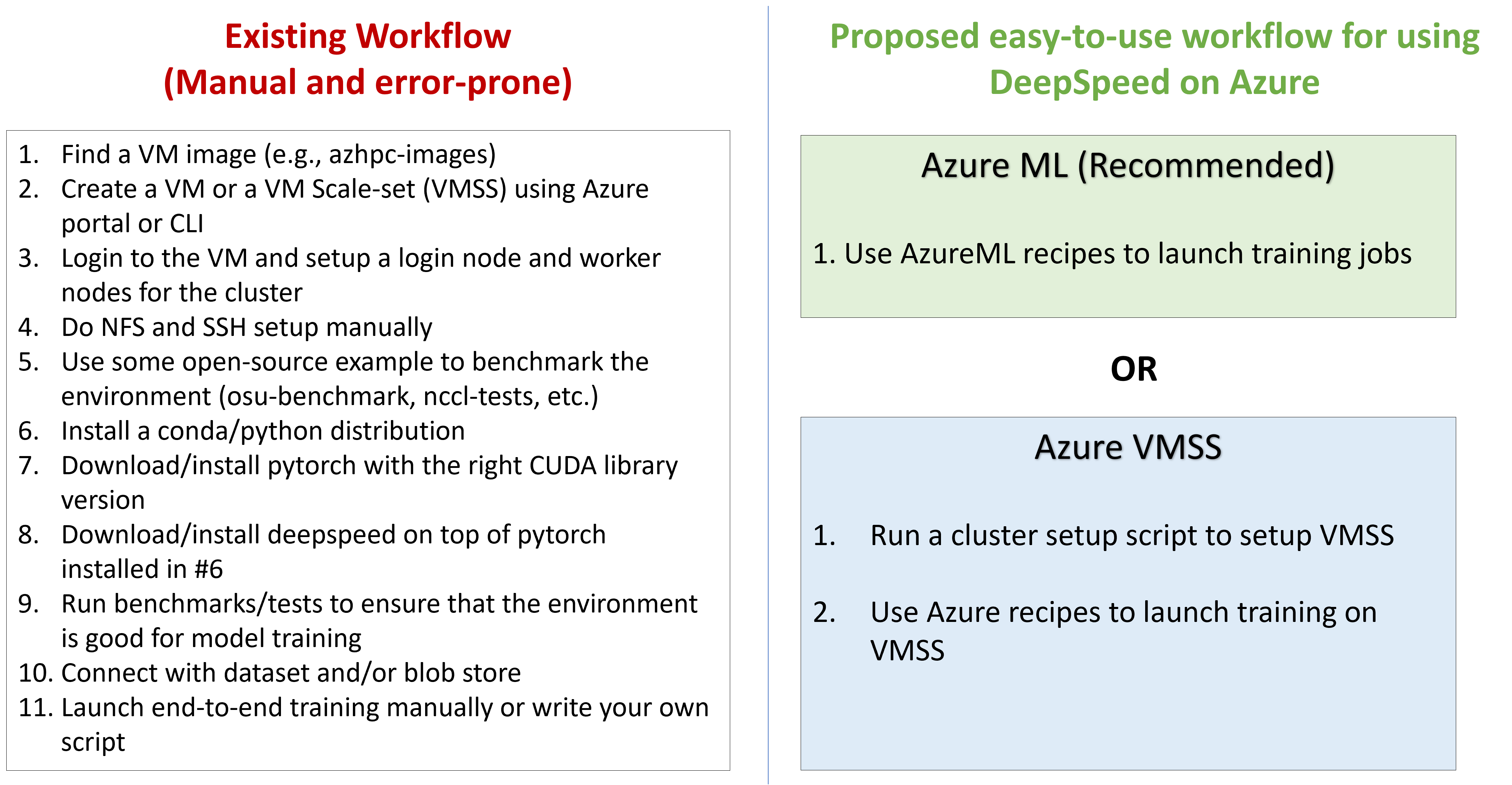
图 2:DeepSpeed 在 Azure 上提供易用且精简的分布式训练体验
对于使用 Azure VM 或 Azure VMSS 构建自定义环境的用户,只需两个步骤:
- 1) 运行集群设置脚本(将在未来几周发布)
- 2) 使用 Azure VMSS 配置来启动训练。
关键性能优势
我们已经在 Azure 公告中分享了我们关键性能结果的摘要。与其他云提供商相比,我们能够训练 2 倍大的模型尺寸(2 万亿 vs. 1 万亿参数),扩展到 2 倍多的 GPU(1024 vs. 512),并提供高达 1.8 倍的每 GPU 计算吞吐量(150 TFLOPs vs. 81 TFLOPs)。
DeepSpeed 在 Azure 上提供接近线性的可扩展性,无论是在模型尺寸增加还是GPU 数量增加方面。如图 3a 所示,结合 DeepSpeed ZeRO-3、其新颖的 CPU 卸载能力以及由 InfiniBand 互连和 A100 GPU 提供支持的高性能 Azure 堆栈,我们能够随着模型尺寸从 1750 亿参数增加到 2 万亿参数,以接近线性的方式保持高效的每 GPU 吞吐量(>157 TFLOPs)。另一方面,对于给定的模型尺寸,例如 175B,随着我们将 GPU 数量从 128 增加到 1024,我们实现了接近线性的扩展,如图 3b 所示。关键在于,Azure 和 DeepSpeed 共同打破了 GPU 内存墙,使我们的客户能够轻松高效地大规模训练万亿参数模型。
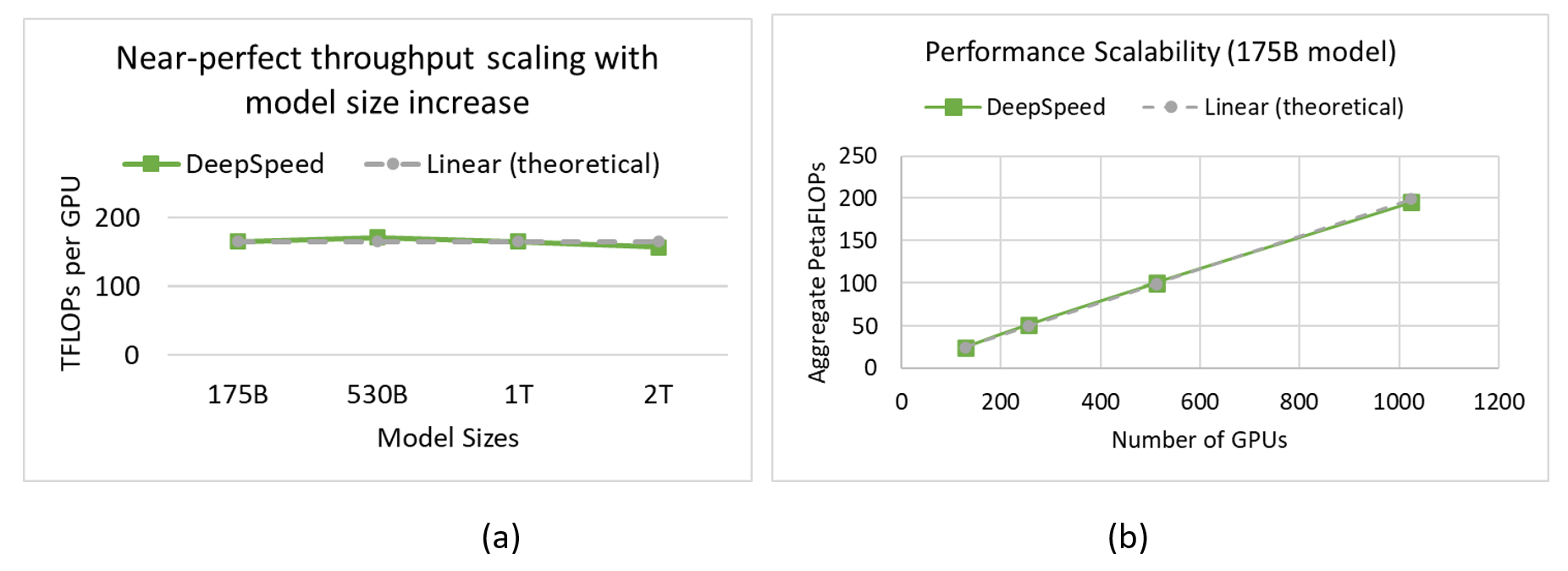
图 3:(a) 随着模型尺寸从 1750 亿参数增加到 2 万亿参数(BS/GPU=8),每 GPU 吞吐量接近完美。(b) 对于 175B 模型(BS/GPU=16),随着 GPU 设备数量的增加,性能扩展接近完美。两种情况下的序列长度均为 1024。
实验设置
我们分享了实验设置的详细信息以及我们遵循的一些最佳实践。用户可以直接使用它们来重现我们的结果,或者根据自己的模型规模和 Azure 硬件的配置规模进行修改。
硬件(Azure 实例)
在我们的实验中,我们使用了 NDm A100 v4 系列实例。每个实例包括两个 AMD EPYC 7V12 64 核 CPU 插槽、1.7TB 主内存和八个 A100 80GB GPU。该系统具有平衡的 PCIe 拓扑,将 4 个 GPU 设备连接到每个 CPU 插槽。VM 中的每个 GPU 都配备了其专用的、与拓扑无关的 200 Gb/s NVIDIA Mellanox HDR InfiniBand 连接,提供加速的 200 Gbps 高速结构。DeepSpeed 库利用了卸载功能,其中激活和优化器状态分配在主内存中。因此,每个节点 1.7TB 的内存容量有助于我们扩展到大型模型尺寸。
使用 AzureML 的训练设置
用户可以直接使用 AzureML Studio 并使用我们发布的配置来运行实验,无需任何额外设置。这是在 Azure 上运行实验最简单和推荐的方式。
使用 Azure VMSS 的训练设置
现有的 VMSS 客户以及拥有基于 Azure VM 的自定义环境的用户可以按照以下步骤进行设置。使这些步骤变得简单的脚本将在未来几周内发布。使用 Azure 虚拟机规模集 (VMSS) 创建集群,以预置所需数量的计算节点,这些节点运行专为超大规模深度学习应用而设计的新 Azure HPAI VM 镜像,并使用表 1 中列出的软件堆栈。
| 名称 | 描述(版本) |
|---|---|
| PyTorch | 1.10.2(从源代码安装) |
| DeepSpeed | 0.6.2(从源代码安装) |
| Megatron-LM | https://github.com/deepspeedai/Megatron-DeepSpeed |
| Apex | 0.1 |
| NCCL | 2.12.10 |
| CUDNN | 8.2.4.15 |
| CUDA | 11.4 |
| CUDA 驱动程序 | R470.82 |
| 虚拟机镜像 | Ubuntu-HPC 20.04 镜像 |
表 1:Azure HPC VM 镜像中软件包的详细版本信息
用户可以创建一个包含多达 600 个 VM 实例的 VMSS,从而支持多达 4,800 个 A100 GPU。除了用于计算节点的 VMSS,我们还使用廉价的 D4s v4(或类似)实例预置了一个独立的登录节点,该实例具有 4 核 Intel VCPU,运行相同的镜像,用于编译、启动和监控作业。登录节点、计算节点和共享存储文件系统都分组在一个 Azure 虚拟网络 (vnet) 中,允许 VM 之间通过 SSH 相互连接,并连接到共享 NFS 卷,如图 4 所示。
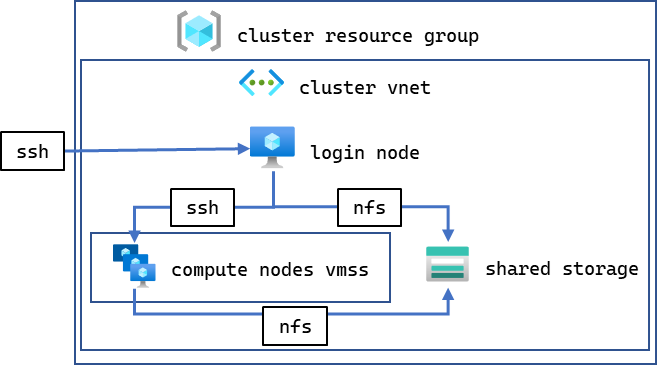
图 4:我们基于 VMSS 的实验设置组织结构
不同模型配置的性能评估
我们使用表 2 中所示的配置,对四种不同模型尺寸(175B、530B、1T 和 2T)进行了实验。
| 模型尺寸 | 1750 亿 | 5300 亿 | 1 万亿 | 2 万亿 |
|---|---|---|---|---|
| 层数 | 96 | 105 | 128 | 160 |
| 隐藏维度 | 12,288 | 20,480 | 25,600 | 32,768 |
| 注意力头数 | 96 | 128 | 160 | 128 |
表 2:模型配置
对于每种配置,我们都以 TFLOPs/GPU 作为主要性能指标报告系统的峰值吞吐量。为了计算 TFLOPs,我们使用 Megatron 论文中使用的公式,如下所示。
FLOPs/GPU = 96 * B * s * l * h2 * (1 + s/6h + V/(16*l*h))
B 是批处理大小,s 是序列长度,l 是层数,h 是隐藏大小,V 是词汇量大小。
扩展 175B 和 530B 模型
图 5a 和 5b 分别显示了序列长度为 512 和 1024 的 175B 模型的结果。对于序列长度为 512 的情况,我们只扩展到 512 个 GPU,因为添加更多 GPU 显示出相似的性能。另一方面,对于序列长度为 1024 的情况,我们看到了线性性能增长到 1024 个 GPU。总的来说,在 256 个 GPU 上,当微批处理大小为 32 且序列长度为 512 时,实现了204.49 TFLOPs/GPU 的峰值吞吐量。
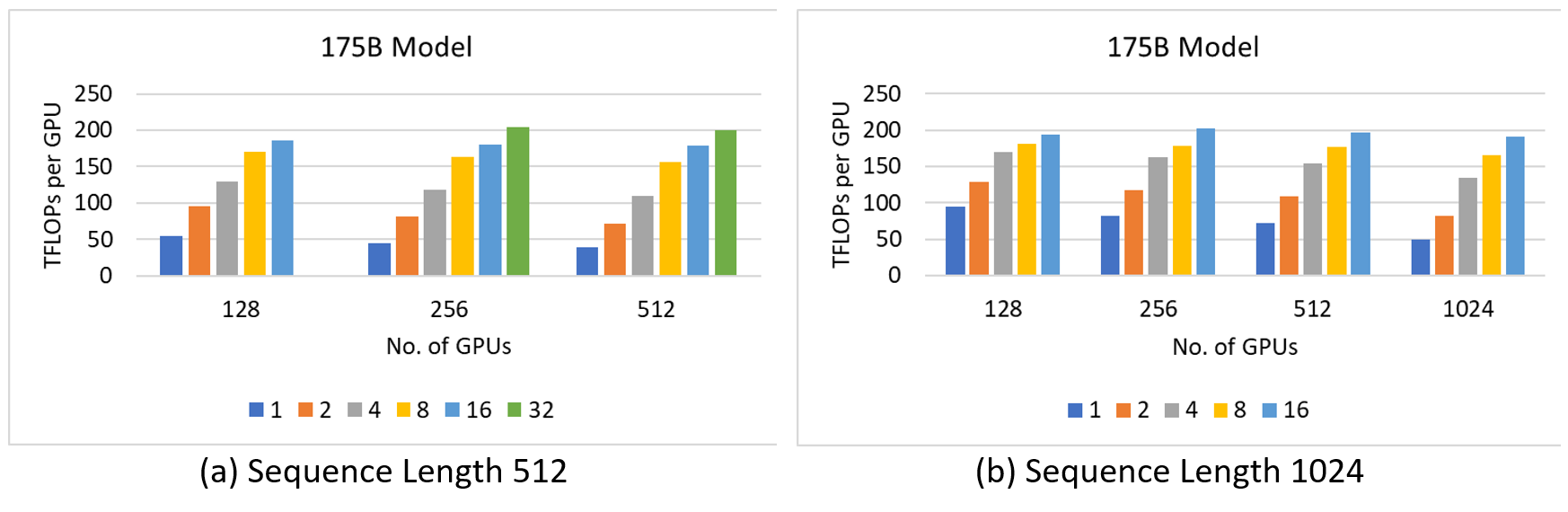
图 5:175B 模型在 512 和 1K 个 GPU 上的性能特征。彩色柱表示不同的微批处理大小。
接下来,我们报告 530B 模型的扩展情况。之前在 Selene 超级计算机上使用 DeepSpeed 和 Megatron-LM 在 280 台 DGX A100 服务器上对 530B MT-NLG 模型进行的测试显示,峰值吞吐量为 126 TFLOPS/GPU。然而,我们能够超越该吞吐量,在 128 个 NDm A100 v4 系列 A100 系统(即 1024 个 GPU)上实现了高达171.37 TFLOPs/GPU 的吞吐量,如图 6 所示。
530B 模型的优势在于其更简单的并行化配置,因为它没有张量/管道并行。通过 ZeRO 驱动的数据并行,配置分布式模型所需启发式方法更少。此外,对于微批处理大小 >1 的情况,每 GPU 超过 140 TFLOPs 的稳定态性能一致性,证明了我们强大的软硬件平台。
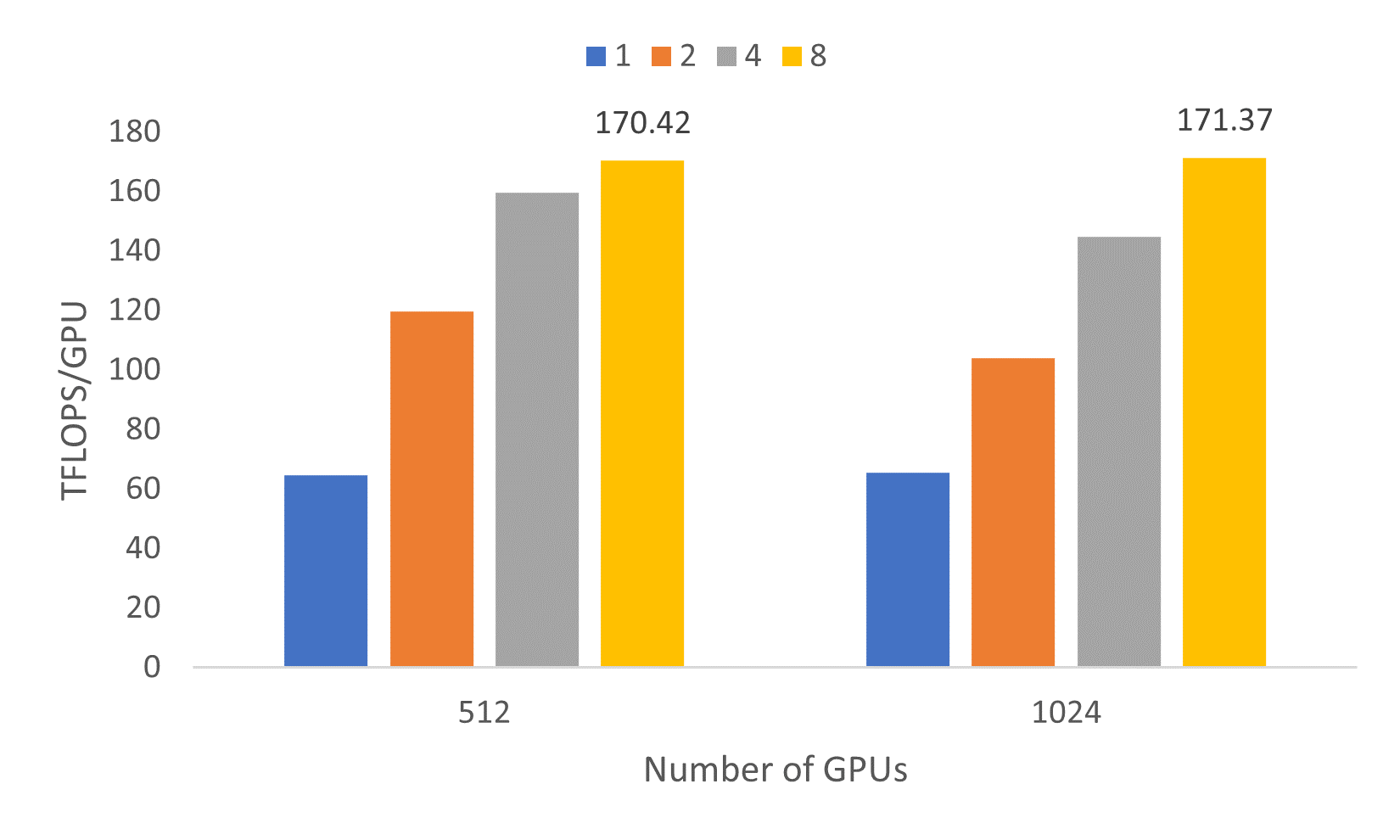
图 6:5300 亿参数模型在 512 和 1024 个 GPU 上实现的吞吐量,每 GPU 微批处理大小分别为 1、2、4 和 8,序列长度为 1,024。
扩展 1T 和 2T 模型
1 万亿参数模型包含 128 层和 160 个注意力头。训练这样一个超大规模模型并非易事。图 7 显示了我们在 512 和 1024 个 GPU 上探索的每种模型配置所达到的吞吐量。在 1024 个 GPU 上,当微批处理大小为 8 时,峰值吞吐量达到了165.36 TFLOPs/GPU,并且模型在前 3-4 次迭代内达到了稳定性能。
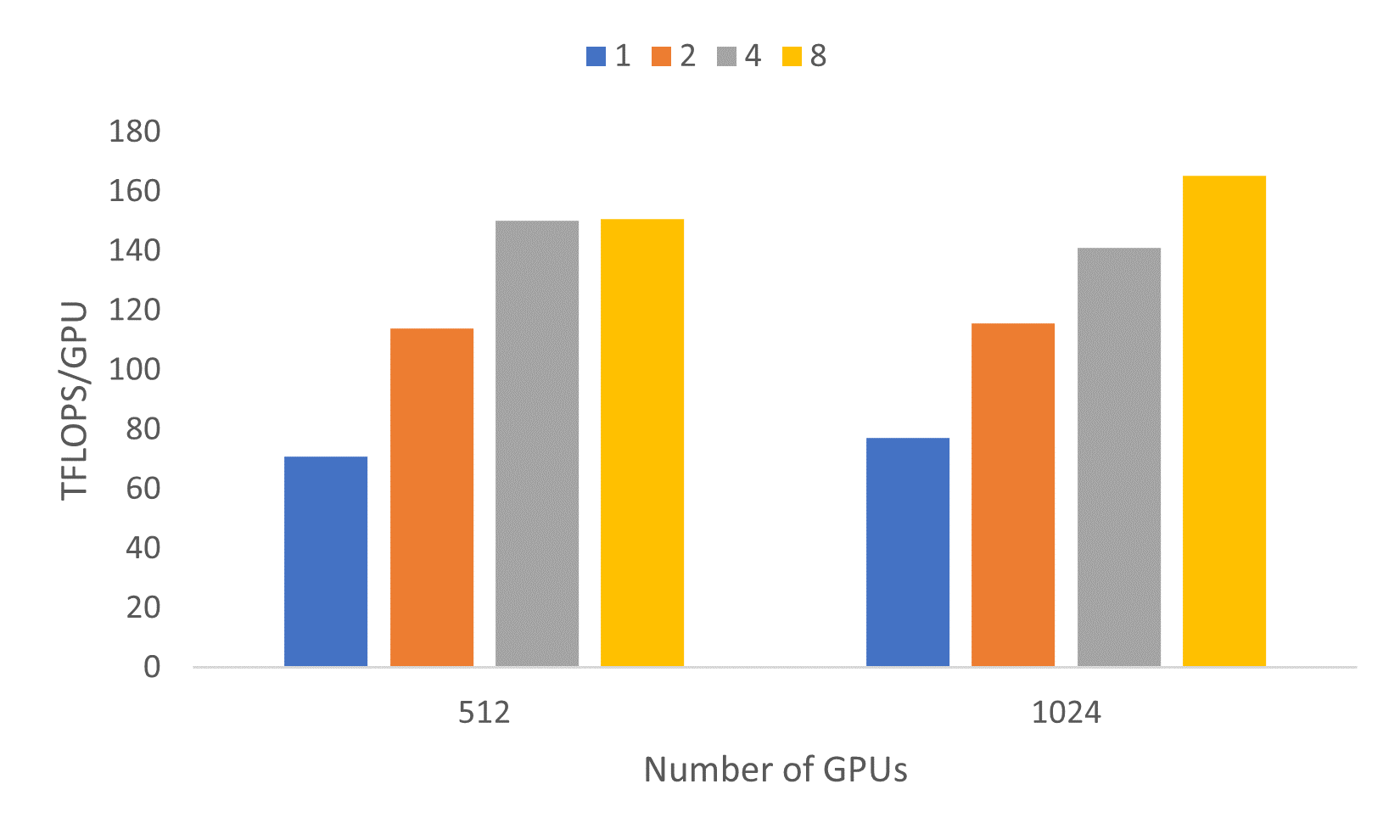
图 7:1 万亿参数模型在 512 和 1024 个 GPU 上,使用 1、2、4 和 8 微批处理大小的性能特征,序列长度为 1,024。
2 万亿参数模型包含 160 层,32k 隐藏维度和 128 个注意力头。考虑到模型的大尺寸以及在 1024 个 GPU 上所需的显著时间,我们将 2T 模型的基准测试运行限制为每个 GPU 批处理大小为 8,序列长度为 1024。我们能够在 1,024 个 GPU 上实现 157 TFLOPs/GPU。
如何在 Azure 上运行训练实验?
我们认识到 DeepSpeed 用户群体多样,拥有不同的环境。在本教程中,我们的重点是简化计划在 Azure 上运行大型模型训练实验的用户的操作。
在 Azure 上进行模型训练最简单的方法是通过 Azure ML 配置。作业提交和数据准备脚本已在此处提供。用户只需按照指南设置他们的 Azure ML 工作区,然后使用 aml_submit.py 文件提交实验。
一些用户拥有基于 Azure VM 和 VMSS 集群构建的自定义环境。为了简化在此类设置上的训练,我们正在开发一个易用的集群设置脚本,该脚本将在未来几周内发布。如果您已经有一个正在运行的集群设置,您可以使用针对 175B 和 1T 模型的 Azure 配置。这些配置可以很容易地修改以训练其他模型配置。
致谢
这篇博客文章由 DeepSpeed 团队与 AzureML 和 AzureHPC 团队合作撰写。我们要感谢以下几位使这项工作成为可能的人:
- AzureHPC 团队:Russell J. Hewett, Kushal Datta, Prabhat Ram, Jithin Jose, and Nidhi Chappell
- AzureML 团队:Vijay Aski, Razvan Tanase, Miseon Park, Savita Mittal, Ravi Shankar Kolli, Prasanth Pulavarthi, and Daniel Moth
- DeepSpeed 团队:Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Martin Cai, and Yuxiong He
- 首席技术官办公室:Gopi Kumar and Luis Vargas