使用 VL-MoE 扩展大规模生成式多模态专家混合模型
人工智能生成内容 (AIGC) 领域正在迅速发展,其目标是使内容创作更高效、更易用。AIGC 最令人兴奋的领域之一是开发像 Flamingo、BLIP 和 GPT4 这样的大规模多模态模型,它们可以接受来自多种资源的输入,例如图像、文本、音频等,并生成各种格式的输出。例如,可以通过稳定扩散 (stable diffusion) 和 DALLE 使用提示文本来创建图像,而即将推出的 Office 新功能则可以利用新的 Microsoft Office Copilot 的强大功能,创建包含文本、图像、动画等的幻灯片。
扩大模型规模是提高 AIGC 任务可用性和能力的一种常见方法。然而,简单地扩大密集架构(例如,从 GPT-1 到 GPT-3)对于模型训练和推理来说通常都极其耗费资源和时间。解决这一挑战的一种有效方法是应用专家混合(MoE)。特别是,最近的基于文本的 MoE 和 基于视觉的 MoE 研究表明,与同等质量的密集模型相比,MoE 模型可以显著降低训练和资源成本,或者在相同的训练预算下产生更高质量的模型。到目前为止,联合训练多模态模型的 MoE 的有效性仍未被充分理解。为了探索这一重要能力,DeepSpeed 团队 自豪地宣布推出我们的第一个大规模生成式专家混合 (MoE) 多模态模型,命名为 VL-MoE。
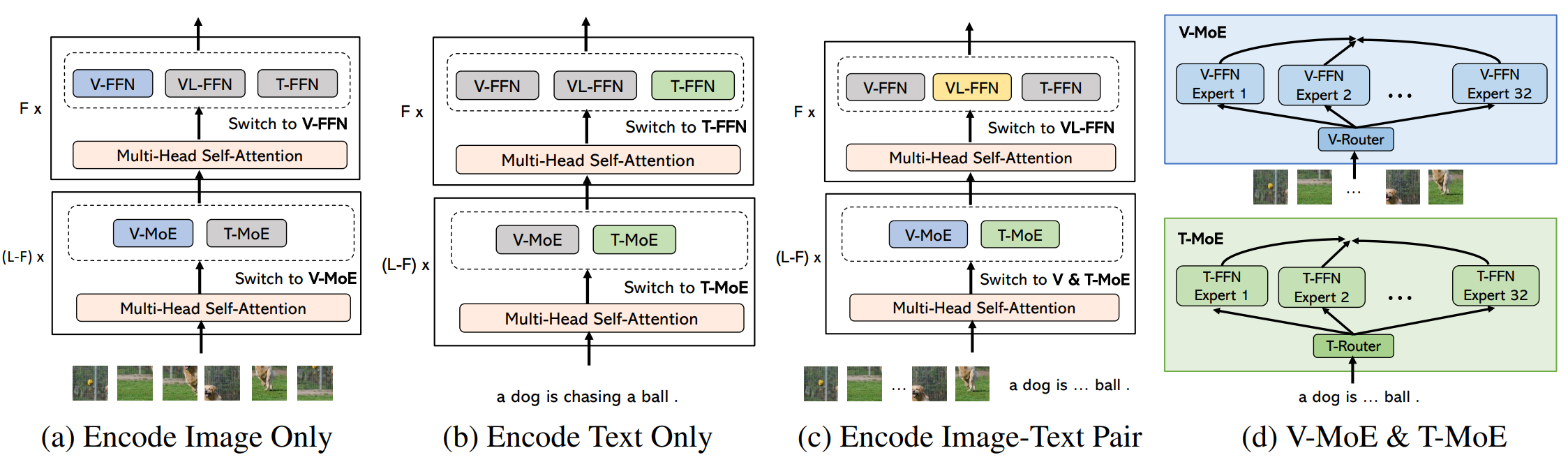
图1:我们 VL-MoE 中针对各种模态输入的新编码过程,其中灰色块和彩色块分别表示未激活和已激活的模块。
具体来说,我们将 MoE 结构整合到经典的单塔多模态模型中,包含以下组件:(1) 一个跨模态的共享自注意力模块,(2) 前馈网络 (FFN) 中特定模态的专家池,以及 (3) 一个从密集 FFN 扩展而来的稀疏门控 MoE。随后,在与 VLMO 相同数量的训练资源(20万训练步)下,我们展示了 VL-MoE 在以下两个方面优于最先进的密集对应模型:
(1) 与密集对应模型相比,VL-MoE 可以实现显著的精度提升。表1显示,在相同的训练预算下(即每个 token 具有相同数量的激活参数),拥有32个专家的 VL-MoE Base 在所有四个视觉-语言数据集上都比 VLMO-Base 密集模型取得了更好的精度。
(2) 与密集对应模型相比,VL-MoE 在激活参数数量少得多的情况下实现了相似的模型质量。我们的结果表明,VL-MoE 的微调性能与大3.1倍的 VLMO-Large 密集模型(即每个 token 的激活参数数量多3.1倍)相似。这可以直接带来大约3.1倍的训练成本降低,因为 Transformer 的训练 FLOPs 与每个 token 的激活模型大小成正比。
| 每个 Token 的参数数量(# 总参数) | VQA | NLVR2 | COCO | Flickr30K | |
|---|---|---|---|---|---|
| test-dev / std | dev / test-P | TR / IR | TR / IR | ||
| 密集对应模型 | |||||
| VLMO-密集 Base | 180M (180M) | 76.64 / 76.89 | 82.77 / 83.34 | 74.8 / 57.2 | 92.3 / 79.3 |
| VLMO-密集 Large | 560M (180M) | 79.94 / 79.98 | 85.64 / 86.86 | 78.2 / 60.6 | 95.3 / 84.5 |
| 我们的(32专家 VL-MoE) | |||||
| VL-MoE | 180M (1.9B) | 78.23 / 78.65 | 85.54 / 86.77 | 79.4 / 61.2 | 96.1 / 84.9 |
表1:用于视觉-语言分类任务和图像-文本检索任务的不同模型的微调精度结果比较。
复杂的 MoE 模型设计需要一个高效且可扩展的训练系统,该系统能够支持多维并行和高效的内存管理。DeepSpeed MoE 训练系统提供了这些高级功能,包括易于使用的 API,可实现数据、张量和专家并行的灵活组合。此外,DeepSpeed MoE 通过结合利用专家并行和 ZeRO 优化,实现了比最先进系统更大的模型规模。通过利用 DeepSpeed MoE 系统,拥有32个专家的 VL-MoE Base 实现了与 VLMO-密集 Large 相似的模型质量,同时训练速度提高了约2.5倍。
DeepSpeed MoE 系统已经开源,可以轻松作为即插即用组件,为任何大规模 MoE 模型实现高性能低成本训练。DeepSpeed MoE 的使用教程可在此处获取。VL-MoE 目前正在集成到 DeepSpeed 示例中作为模型示例。请继续关注我们即将发布的更新。