DeepSpeed 推理:支持定制推理核和量化的多GPU推理
尽管DeepSpeed支持训练先进的大规模模型,但在所需应用场景中使用这些训练好的模型仍然面临挑战,原因在于现有推理解决方案存在三大局限性:1) 缺乏对多GPU推理的支持,以适应大型模型并满足延迟要求;2) 在小批量推理时GPU核性能受限;3) 难以利用量化,这包括将模型量化以减小模型大小和延迟,以及在没有专用硬件的情况下支持量化模型的高性能推理。
为了应对这些挑战,我们引入了DeepSpeed Inference,它通过三个关键特性,为DeepSpeed中训练的大型模型无缝添加了高性能推理支持:针对多GPU推理的推理自适应并行度、针对小批量推理优化的推理核,以及对量化感知训练和量化模型推理核的灵活支持。
支持自适应并行度的多GPU推理
并行度是适应大型模型并减少训练和推理时每设备内存消耗的有效方法。然而,简单地将训练时的并行选择和程度应用于推理效果不佳。模型并行(MP)和流水线并行(PP)的配置通常在模型训练期间设置,与数据并行(DP)不同,其设置基于内存占用、计算方式和资源预算。一方面,推理计算本身所需内存较少,因此每设备可以容纳更大的分区。这有助于减少模型部署所需的并行度。另一方面,优化延迟或满足延迟要求通常是推理中的首要考虑因素,而训练则优化吞吐量。
为了获得所需的延迟,DeepSpeed Inference自动将模型并行(MP)作为降低模型延迟的有效方法,其并行度通常是首先确定的。通过MP,我们可以分割模型并在多个设备(GPU)上并行化计算操作以降低延迟,但这会降低计算粒度并增加通信开销,可能损害吞吐量。一旦达到延迟目标,DeepSpeed可以应用流水线并行来最大化吞吐量。总的来说,DeepSpeed Inference支持从训练到推理的并行方法和程度选择的灵活适应,在最大限度地降低延迟的同时节省部署成本。
定制推理核以提升Transformer块的计算效率
为了实现高计算效率,DeepSpeed-inference通过算子融合为Transformer块提供了定制的推理核,同时考虑了多GPU的模型并行性。我们的核融合方案与类似方法的主要区别在于,我们不仅融合逐元素操作(如偏置加法、残差和激活函数),还将通用矩阵乘法(GeMM)操作与其他操作合并。为此,我们为向量-矩阵或瘦矩阵-矩阵乘法设计了一种高效的实现,这使得我们能够在GeMM操作的归约边界处融合更多的操作。
核融合
我们采取了两种主要的算子融合策略:1) 在所有融合操作序列中,保持输入和输出的访问模式不变;2) 在每个all-reduce边界处融合操作。第一种策略确保不同的线程块不会遇到在流式多处理器(SMs)之间传输数据的情况。这是因为除了使用主内存之外,SMs之间没有直接的通信方式,而主内存会因为内存访问的非确定性行为而增加块同步开销。第二种策略的原因是,除非模型并行GPU之间的部分结果得到归约,否则我们无法继续执行。
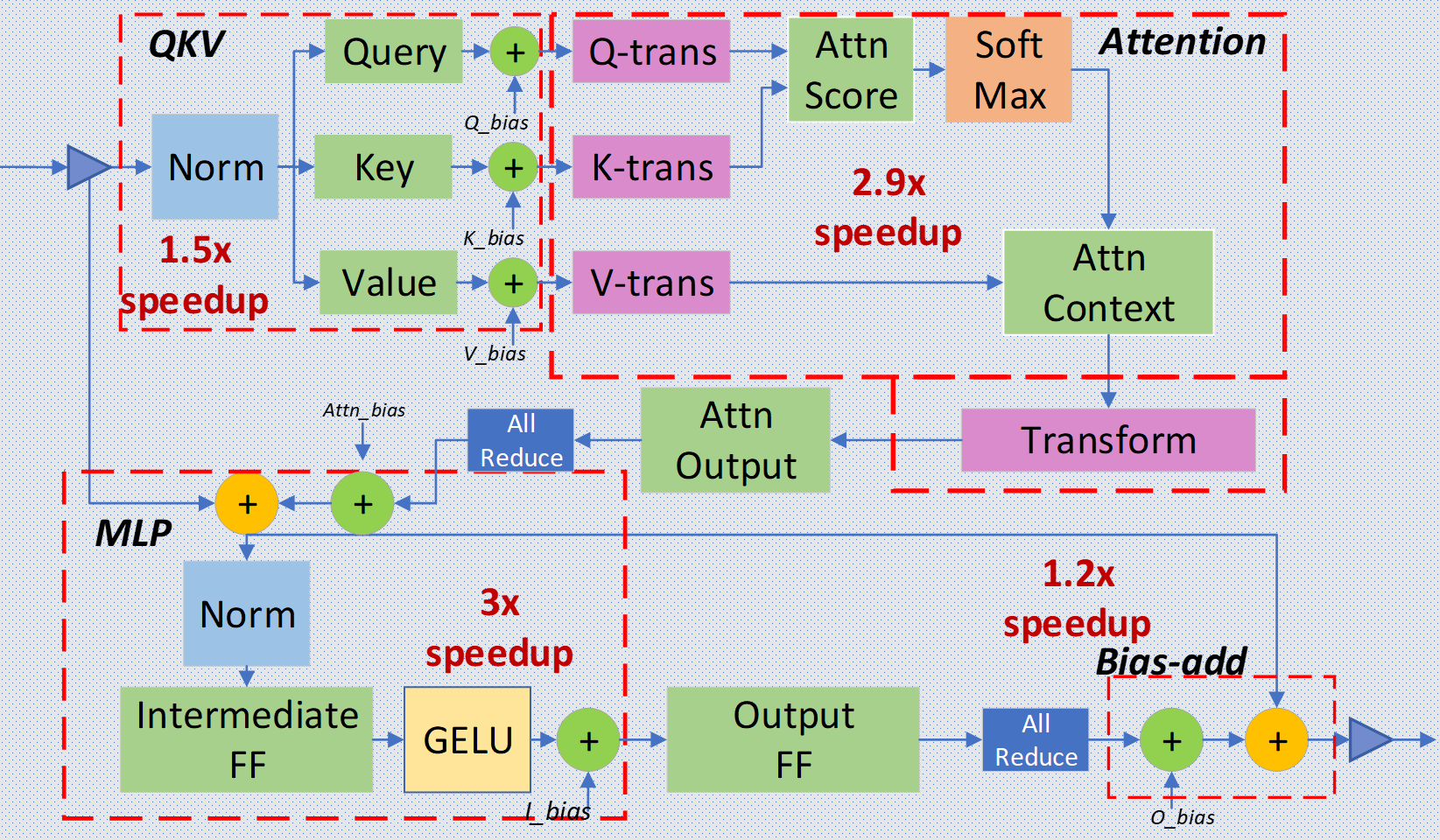
图1:带有Megatron风格模型并行all-reduce组件的Transformer层。该图用虚线(线的宽度表示融合深度)说明了层中融合在一起的部分。
图1展示了Transformer层的不同组件,以及在我们的推理优化中考虑进行融合的算子组。我们还考虑了NVIDIA Megatron-LM风格的并行度,它将注意力(Attn)和前馈(FF)块划分到多个GPU上。因此,我们包含了两个all-reduce操作,它们在Attn和FF块之后,将并行GPU之间的结果进行归约。如图1所示,我们将Transformer层内部的算子融合在四个主要区域:
- 输入层归一化(Layer-Norm)加上查询(Query)、键(Key)和值(Value)的GeMM操作及其偏置加法。
- 变换(Transform)加上注意力(Attention)。
- 中间前馈(FF)、层归一化(Layer-Norm)、偏置加法(Bias-add)、残差(Residual)和高斯误差线性单元(GELU)。
- 偏置加法(Bias-add)加上残差(Residual)。
为了融合这些操作,我们利用共享内存作为中间缓存,用于在层归一化(Layer-Norm)和GeMM中使用的归约操作与逐元素操作之间传输数据。此外,在归约部分计算时,我们使用warp级指令在线程之间通信数据。我们还为GeMM操作采用了新的调度方案,这使得第三次核融合能够融合尽可能多的操作。我们还在第二次核融合中通过使用隐式矩阵变换,将注意力计算的GeMMs操作结合起来,以减少内存压力。与使用cuBLAS GeMM的未融合计算方式相比,对于所有这些核融合,我们分别将性能提高了1.5倍、2.9倍、3倍和1.2倍。
从训练到推理的无缝管道,支持自动核注入
要在推理模式下运行模型,DeepSpeed只需模型检查点的位置和所需的并行配置,即模型并行(MP)/流水线并行(PP)程度。DeepSpeed推理核也可以通过预定义的策略映射(将原始参数映射到推理核中的参数)来支持许多知名的模型架构,例如HuggingFace (Bert和GPT-2) 或Megatron GPT模型。对于其他基于Transformer的模型,用户可以指定自己的策略映射。请注意,只要接收到所有模型检查点,DS-Inference就可以独立于训练管道运行,并且如果定义了正确的映射策略,DeepSpeed用于推理的Transformer核可以注入到任何Transformer模型中。有关如何启用Transformer推理核以及指定并行度的更多信息,请参阅我们的推理教程。
灵活的量化支持
为了进一步降低大规模模型的推理成本,我们创建了DeepSpeed量化工具包,它支持灵活的量化感知训练以及用于量化推理的高性能核。
在训练方面,我们引入了一种名为量化混合(MoQ)的新方法,该方法受混合精度训练启发,并能无缝应用量化。通过MoQ,我们可以在训练的每一步更新参数时,通过模拟量化影响来控制模型的精度。此外,它支持灵活的量化策略和调度——我们发现,通过在训练期间动态调整量化位数,最终的量化模型在相同的压缩比下提供了更高的精度。为了适应不同的任务,MoQ还可以利用模型的二阶信息来检测它们对精度的敏感性,并相应地调整量化调度和目标。
为了最大限度地发挥量化模型的性能优势,我们提供了针对量化模型定制的推理核,这些核通过优化数据移动来降低延迟,但不需要专用硬件。最后,我们的工具包无需在客户端进行任何代码更改,使其易于使用。
性能结果
提高吞吐量并降低推理成本。图3显示了对应于GPT-2、Turing-NLG和GPT-3这三个Transformer网络的三种模型大小的每GPU推理吞吐量。与基线相比,在使用相同FP16精度时,DeepSpeed Inference将每GPU吞吐量提高了2到4倍。通过启用量化,我们进一步提升了吞吐量。对于GPT-2,吞吐量提升了3倍;对于Turing-NLG,提升了5倍;对于与GPT-3特性和大小相似的模型,提升了3倍,这直接意味着在服务这些大型模型时,推理成本降低了3-5倍。此外,正如图5所示,我们实现了这些吞吐量和成本的提升,而没有牺牲延迟。
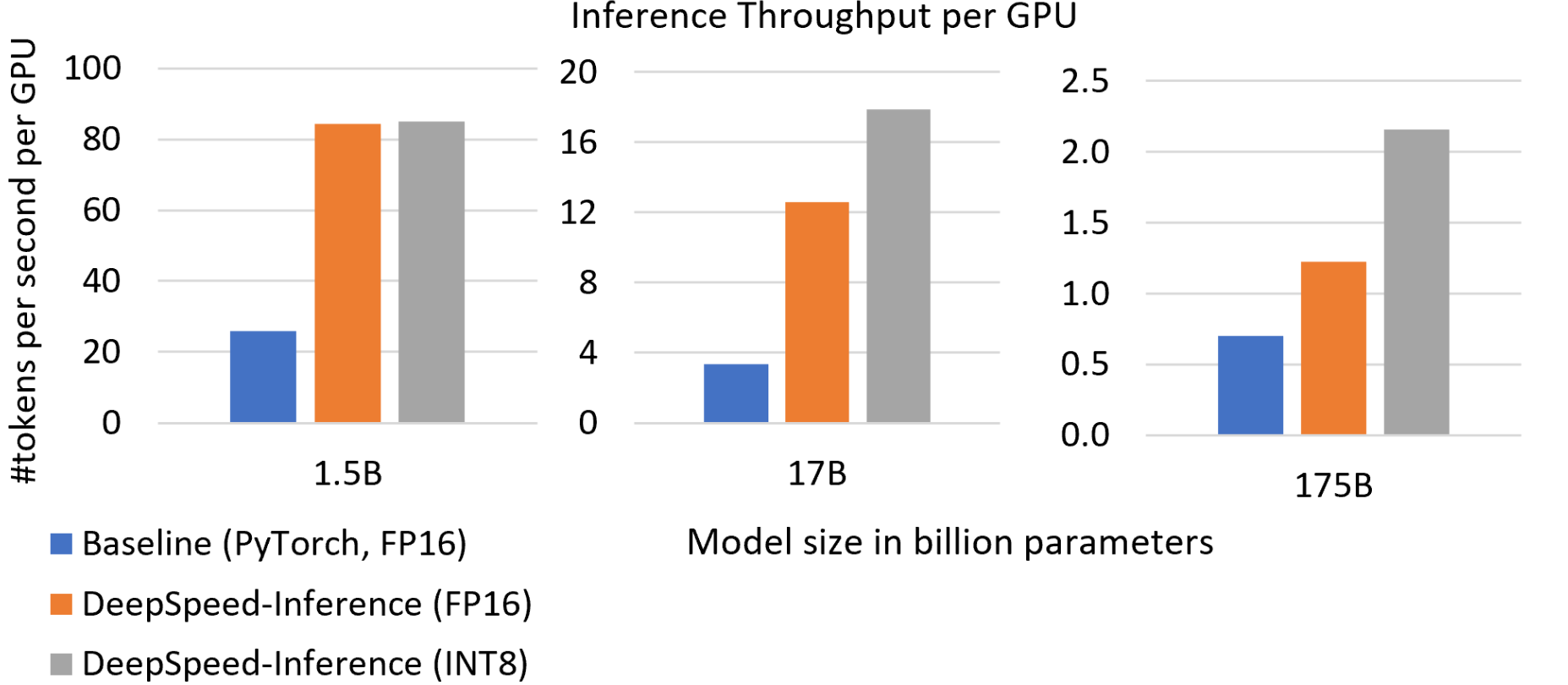
图3:不同模型大小的推理吞吐量。DeepSpeed Inference的吞吐量比基线高3到5倍。
降低推理成本的一个来源是通过减少托管大型模型所需的GPU数量,如图4所示。优化的GPU资源来自于:1) 使用推理自适应并行度,允许用户根据训练好的模型检查点调整模型并行和流水线并行程度;2) 通过INT8量化将模型内存占用减少一半。如图所示,通过调整并行度,我们用2倍更少的GPU来运行17B模型尺寸的推理。结合通过DeepSpeed MoQ进行的INT8量化,我们分别在17B和175B尺寸下使用了4倍和2倍更少的GPU。
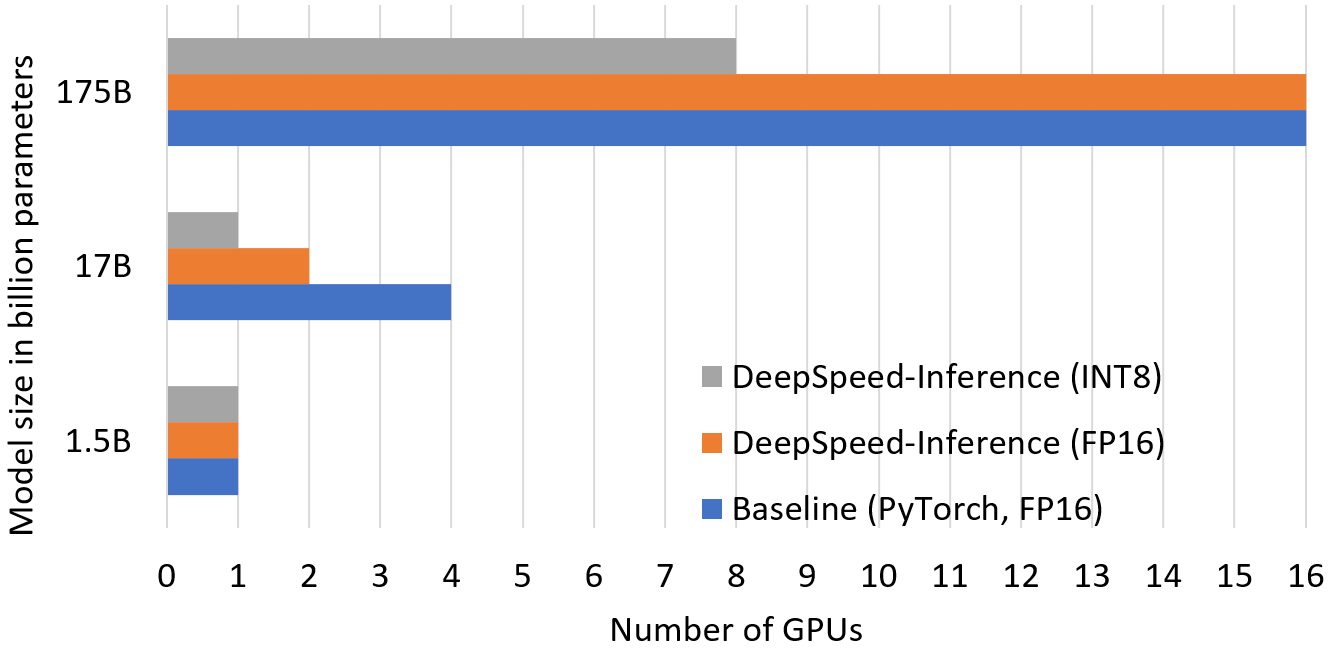
图4:在图4中显示的不同模型尺寸上运行推理所使用的GPU数量。
降低推理延迟。对于推理延迟至关重要的应用场景,我们可以在DeepSpeed Inference中增加模型并行度,以进一步降低推理延迟。如图5所示,当我们模型并行度增加到4时,与PyTorch相比,我们可以将延迟降低2.3倍。此外,通过在推理时调整并行度并使用MoQ量化模型,我们仍然可以在使用较少GPU数量的情况下获得显著的延迟改进。我们分别在比基线低4倍和2倍的资源下获得了1.3倍和1.9倍的加速。
降低推理延迟。对于推理延迟至关重要的应用场景,我们可以在DeepSpeed Inference中增加模型并行度,以进一步降低推理延迟。如图5所示,当我们模型并行度增加到4时,与PyTorch相比,我们可以将延迟降低2.3倍。此外,通过在推理时调整并行度并使用MoQ量化模型,我们仍然可以在使用较少GPU数量的情况下获得显著的延迟改进。我们分别在比基线低4倍和2倍的资源下获得了1.3倍和1.9倍的加速。
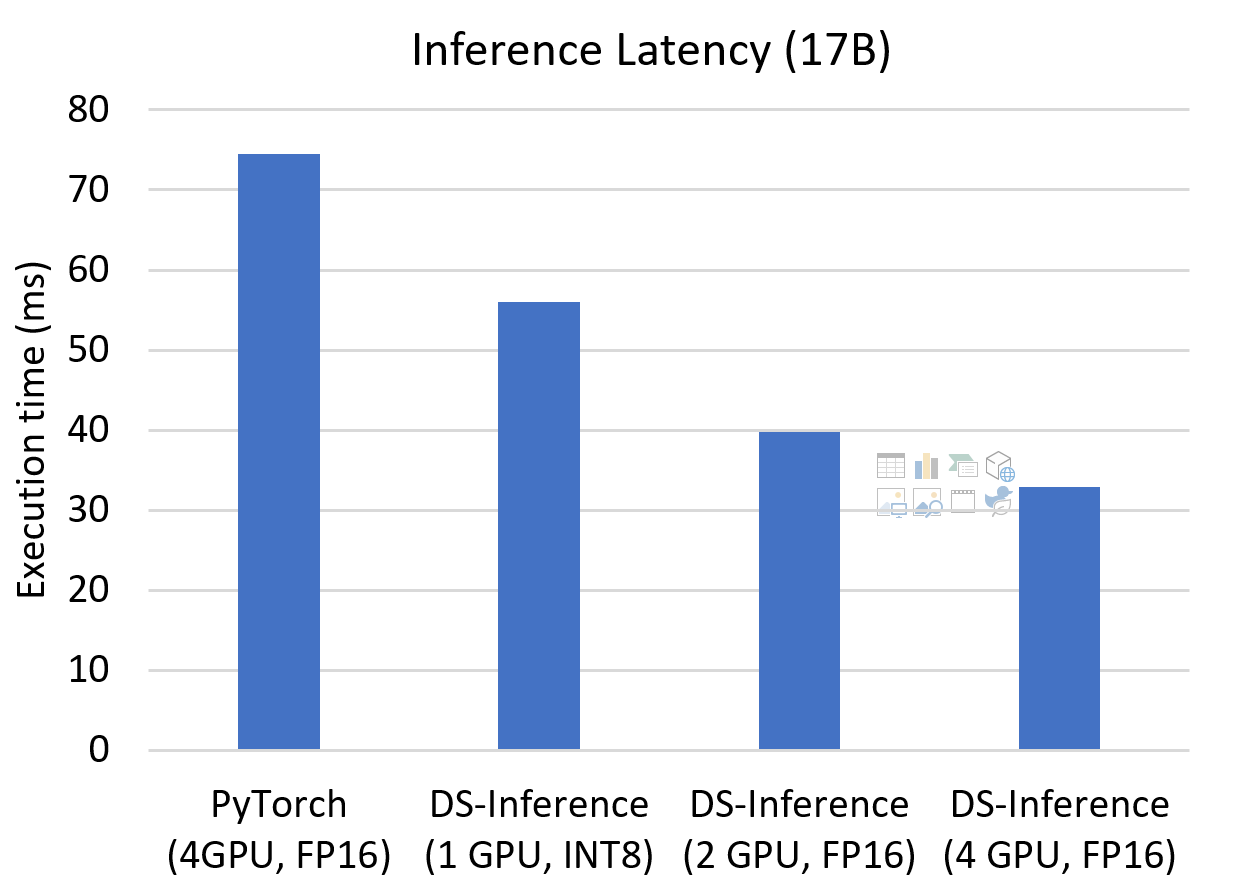
图5. 使用不同并行配置优化延迟的17B模型推理延迟。