DeepSpeed ZeRO-3 Offload
今天,我们宣布发布 ZeRO-3 Offload,它是 ZeRO Stage 3 和 ZeRO Offload 的高效易用组合实现,旨在通过使高效的大规模深度学习训练普及化,继续推进我们民主化人工智能的目标。ZeRO-3 Offload 的主要优势包括:
- 前所未有的内存效率,可在有限的 GPU 资源上运行超大型模型——例如,在单个 GPU 上微调超过 400 亿参数的模型,在 512 个 GPU 上微调超过 2 万亿参数的模型!
- 极其易用
- 可扩展到万亿级参数,无需复杂地组合多种并行技术。
- 对于现有的 DeepSpeed 用户,只需在 DeepSpeed 配置文件中设置几个标志即可开启 ZeRO-3 Offload。
- 分布式训练中每 GPU 的高性能吞吐量和跨 GPU 的超线性可扩展性。
- 对于 1 万亿参数的模型,ZeRO-3 Offload 在 512 块 NVIDIA V100 GPU 上可保持 25 PetaFlops 的计算性能,达到 49 TFlops/GPU。
- 与单 GPU 上的 ZeRO-2 Offload 相比,吞吐量提升高达 2 倍
ZeRO 技术家族概述
ZeRO 冗余优化器(简称 ZeRO)是一系列用于大规模分布式深度学习的内存优化技术。与数据并行(高效但只能支持有限的模型大小)或模型并行(可以支持更大的模型大小但需要大量代码重构并增加通信开销从而限制效率)不同,ZeRO 允许在内存中适应更大的模型,而无需代码重构,同时保持非常高效。ZeRO 通过消除数据并行中固有的内存冗余并限制通信开销到最小来实现这一点。ZeRO 通过将三个模型状态(优化器状态、梯度和参数)在数据并行进程之间进行分区而不是复制来消除数据并行进程之间的内存冗余。通过这样做,它与经典数据并行相比提高了内存效率,同时保留了其计算粒度和通信效率。ZeRO 有三个阶段,对应于三个模型状态,如图 1 所示:第一阶段 (ZeRO-1) 仅分区优化器状态,第二阶段 (ZeRO-2) 分区优化器状态和梯度,最后阶段 (ZeRO-3) 分区所有三个模型状态(更多详情请参阅 ZeRO 论文)。
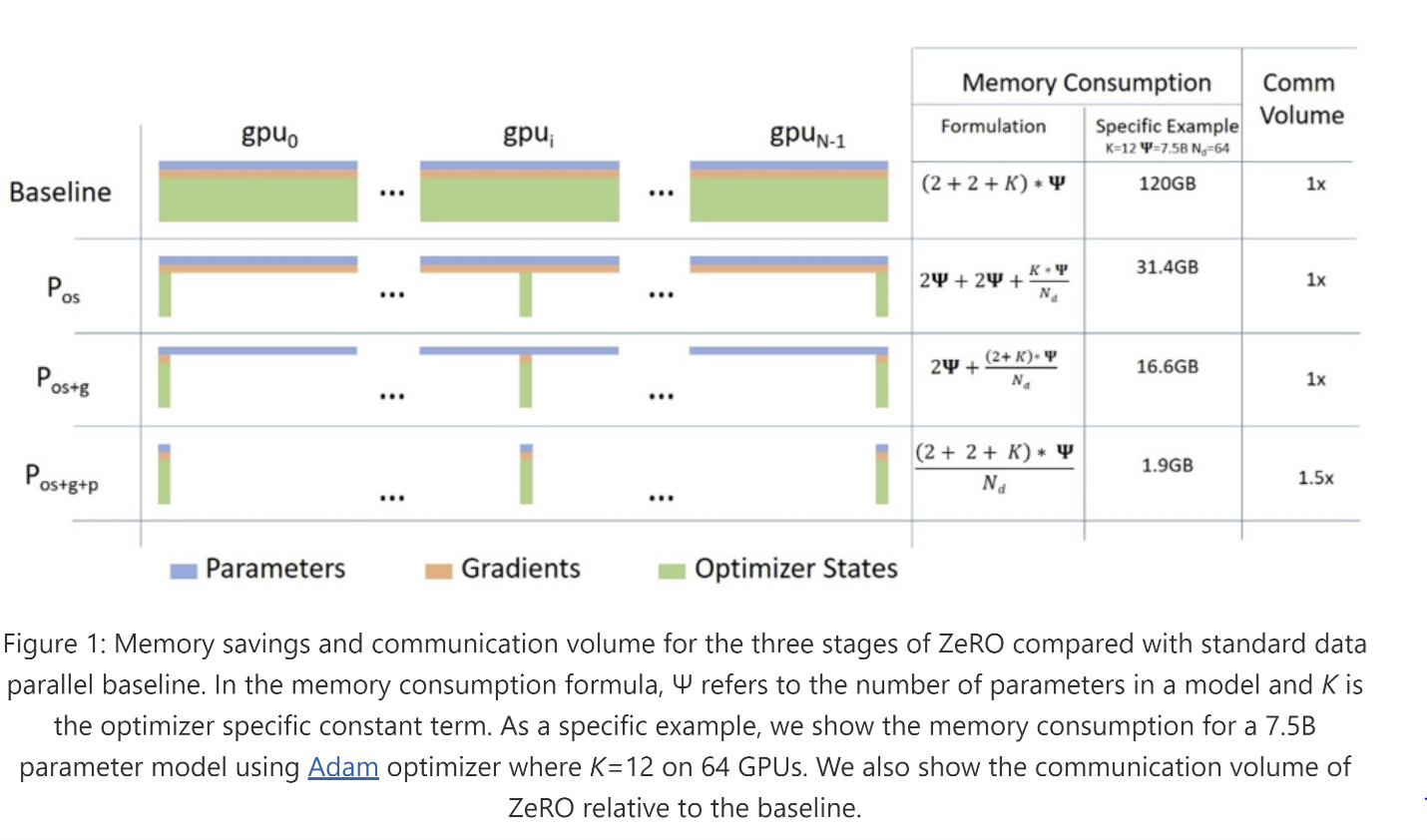 图 1. ZeRO 内存节省概述
图 1. ZeRO 内存节省概述
除了这三个阶段,ZeRO 技术家族还包括 ZeRO-2 Offload。ZeRO-2 Offload 是一种异构深度学习训练技术,与 ZeRO-2 协同工作,将分区的优化器状态和梯度卸载到 CPU 内存。ZeRO-2 Offload 即使在单个 GPU 上也能提供 ZeRO-2 的全部内存优势,同时在多 GPU 设置中提供 ZeRO-2 的出色可扩展性。DeepSpeed 库自 2020 年 9 月以来一直提供 ZeRO-2 Offload。详情请参见下方:
ZeRO-3 Offload
随着今天 ZeRO-3 Offload 的发布,除了 DeepSpeed 中 ZeRO-2 Offload 已支持的优化器状态和梯度分区外,我们还增加了对参数分区和卸载的支持。通过参数分区,ZeRO-3 Offload 实现了 ZeRO 三个阶段的全部功能,使得模型大小能够随着 GPU 数量的增加而线性增长。此外,ZeRO-3 Offload 还可以选择性地将所有这些模型状态卸载到 CPU,以进一步减少 GPU 内存消耗,同时利用 CPU 和 GPU 来最大化整个系统的内存和计算效率。
我们认为 ZeRO-3 Offload 在大型模型训练方面带来了巨大飞跃,主要体现在以下三个方面:
i) 前所未有的模型规模,
ii) 轻松支持超大模型,以及
iii) 实现卓越的训练效率。
前所未有的模型规模
与 ZeRO-2 和 ZeRO-Offload 中参数必须适应单个 GPU 内存不同,ZeRO-3 Offload 可以将参数跨 GPU 进行分区,并将其卸载到 CPU,从而支持比单个 GPU 内存大得多的模型。此外,ZeRO-3 Offload 超越了最先进的混合 3D 并行(数据、模型和流水线并行结合)。虽然 3D 并行受限于聚合的 GPU 内存,但 ZeRO-3 Offload 可以同时利用 GPU 和 CPU 内存,其中 CPU 内存比 GPU 内存大得多且便宜。这使得 ZeRO-3 Offload 能够利用给定的 GPU 和 CPU 资源训练比任何其他现有技术更大规模的模型。
单 GPU 上的模型规模:ZeRO-3 Offload 可以在单个 GPU 上高效训练超过 400 亿参数的模型(例如,32GB V100 GPU + 1.5TB CPU 内存)。这比当前最先进的 ZeRO-2 Offload 所能实现的规模大了 3 倍。
多 GPU 上的模型规模:借助 ZeRO-3 Offload,您可以在拥有 256 个 GPU 和 512 个 GPU 的 NVIDIA 32GB V100 DGX-2 集群上分别训练万亿和两万亿参数的模型。相比之下,最先进的 3D 并行分别需要 800 个 GPU 和 1600 个 GPU 才能适应相同大小的模型。这意味着训练万亿级以上参数的模型所需的 GPU 数量减少了 3 倍。
轻松支持超大模型
从系统角度来看,训练数百亿和万亿参数的模型极具挑战性。数据并行无法将模型大小扩展到数十亿参数以上,模型并行(带张量切片)由于巨大的通信开销,无法有效地将模型大小扩展到单个节点边界之外,而流水线并行无法扩展到模型中可用层数之外,这限制了模型大小以及它可以扩展到的 GPU 数量。
目前唯一可在大规模并行 GPU 集群上扩展到万亿参数的并行技术是 3D 并行,它以复杂的方式结合了数据、模型和流水线并行。虽然这样的系统可以非常高效,但它需要数据科学家进行大量的模型代码重构,将模型拆分为负载均衡的流水线阶段。这也使得 3D 并行在支持的模型类型方面不够灵活,因为具有复杂依赖图的模型无法轻易转换为负载均衡的流水线。
ZeRO-3 Offload 通过两种方式解决了这些挑战:
i) 凭借突破性的内存效率,ZeRO-3 和 ZeRO-3 Offload 是唯一能够独立高效扩展到万亿级参数的深度学习并行技术,无需混合并行策略,极大简化了深度学习训练的系统堆栈。
ii) ZeRO-3 Offload 几乎不需要模型科学家进行模型重构,使数据科学家能够将复杂模型扩展到数百亿到万亿参数。
卓越的训练效率
多节点上每 GPU 的高性能吞吐量:ZeRO-3 Offload 为多节点上的数十亿和万亿参数模型提供了卓越的训练效率。在由 512 块 NVIDIA V100 GPU 组成的 32 个 DGX2 节点上运行,每 GPU 可实现高达 50 TFlops 的持续吞吐量(参见图 2)。相比之下,使用 PyTorch 的标准数据并行训练对于 12 亿参数的模型(单独使用数据并行可训练的最大模型)每 GPU 只能达到 30 TFlops。
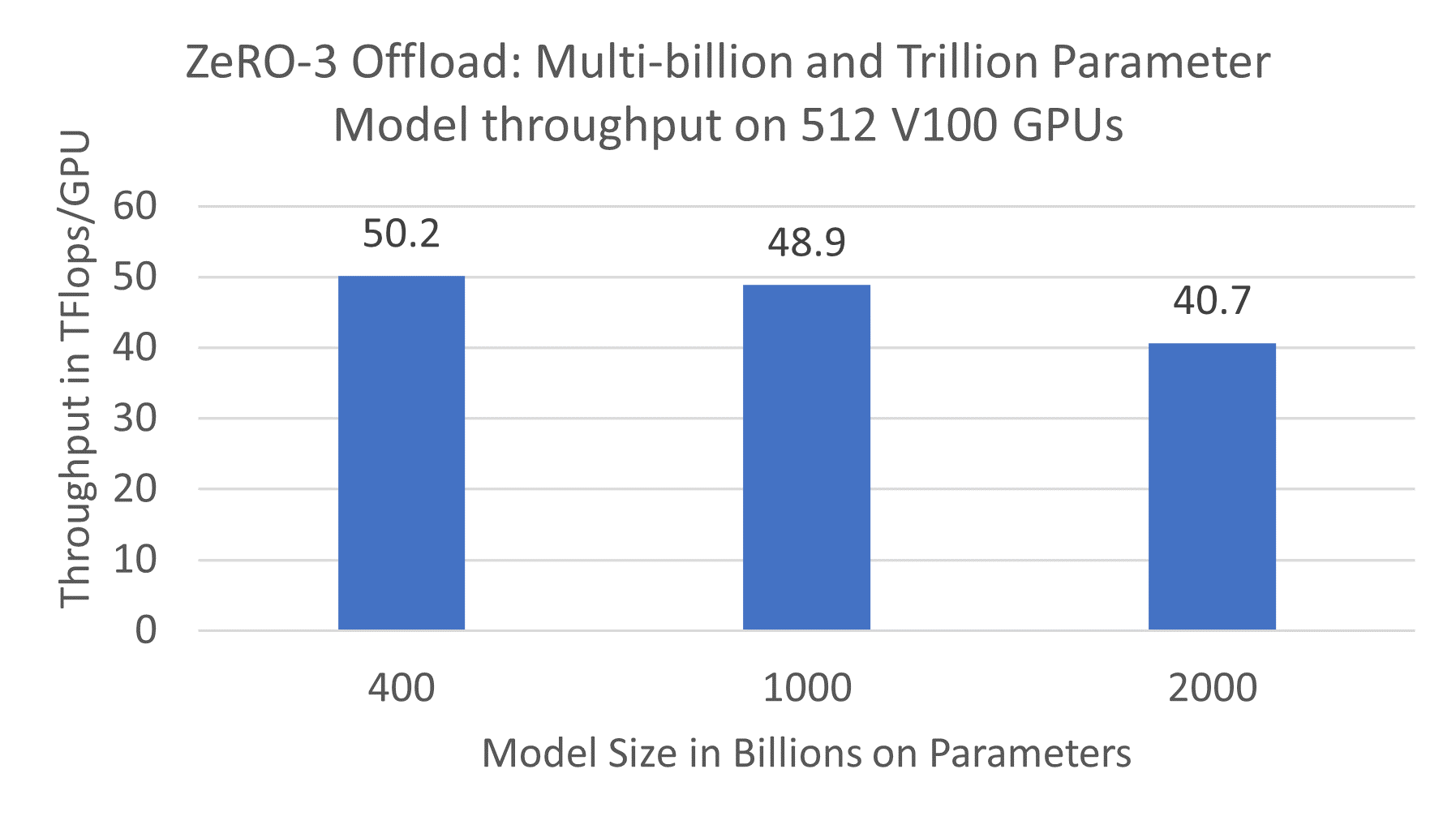 图 2. ZeRO-3 Offload:在 512 块 V100 GPU 上训练数十亿和万亿参数模型的吞吐量
图 2. ZeRO-3 Offload:在 512 块 V100 GPU 上训练数十亿和万亿参数模型的吞吐量
尽管 ZeRO Stage 3 相对于固定批次大小的标准数据并行训练有 50% 的通信开销,ZeRO-3 Offload 仍能获得高效率。这得益于以通信重叠为中心的设计和实现,它允许 ZeRO-3 Offload 将几乎所有的通信量与计算重叠,同时利用更大的批次大小,通过更好的 GPU 内存效率来提高效率。
在单个 GPU 上高效训练数十亿参数模型:ZeRO-3 Offload 通过在单个 GPU 上实现数十亿参数模型的高效训练,进一步推动了人工智能的普及。对于单个 GPU 训练,ZeRO-3 Offload 在两个方面优于 ZeRO-2 Offload。首先,ZeRO-3 Offload 将单个 V100 上可训练的模型大小从 130 亿增加到 400 亿。其次,对于两种解决方案都可训练的模型大小,ZeRO-3 Offload 相比 ZeRO-2 Offload 提供了加速(例如,对于 130 亿参数模型,加速 2.3 倍)。这些结果总结在图 3 中。
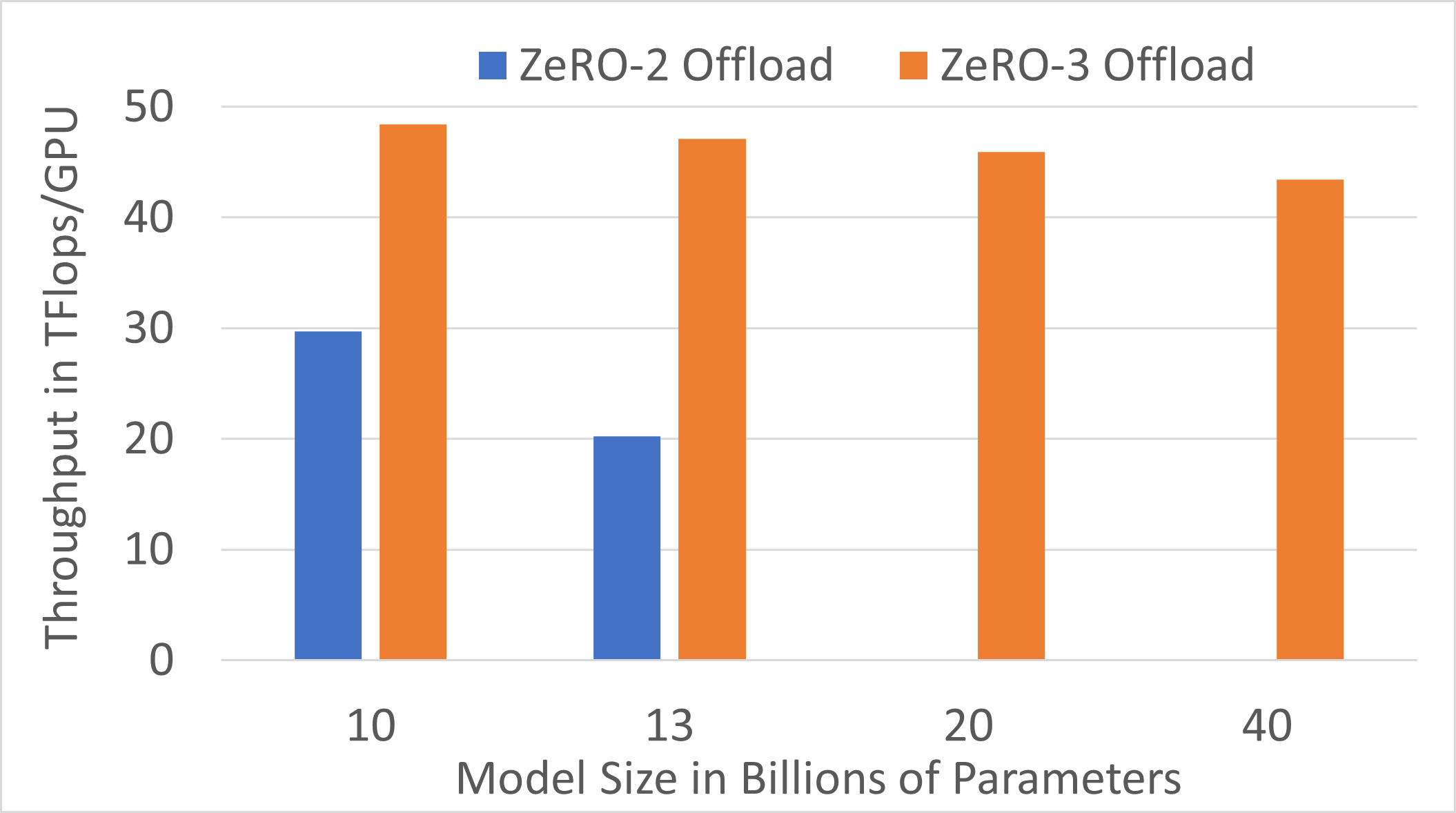 图 3. 在单个 V100 GPU 上训练数十亿参数模型
图 3. 在单个 V100 GPU 上训练数十亿参数模型
跨 GPU 的超线性可扩展性:此外,ZeRO-3 Offload 还保留了我们所有先前 ZeRO 技术(ZeRO Stage 1、ZeRO Stage 2 和 ZeRO Offload)所展示的超线性可扩展特性。ZeRO-3 Offload 可以利用多 GPU 训练配置中所有 GPU 之间 GPU 和 CPU 的聚合 PCI-E 带宽,同时也可以利用所有节点上的聚合 CPU 计算能力。因此,CPU-GPU-CPU 通信时间以及优化器更新时间分别随 GPU 和节点数量线性减少,使得 ZeRO-3 Offload 展现出超线性扩展(参见图 4)。
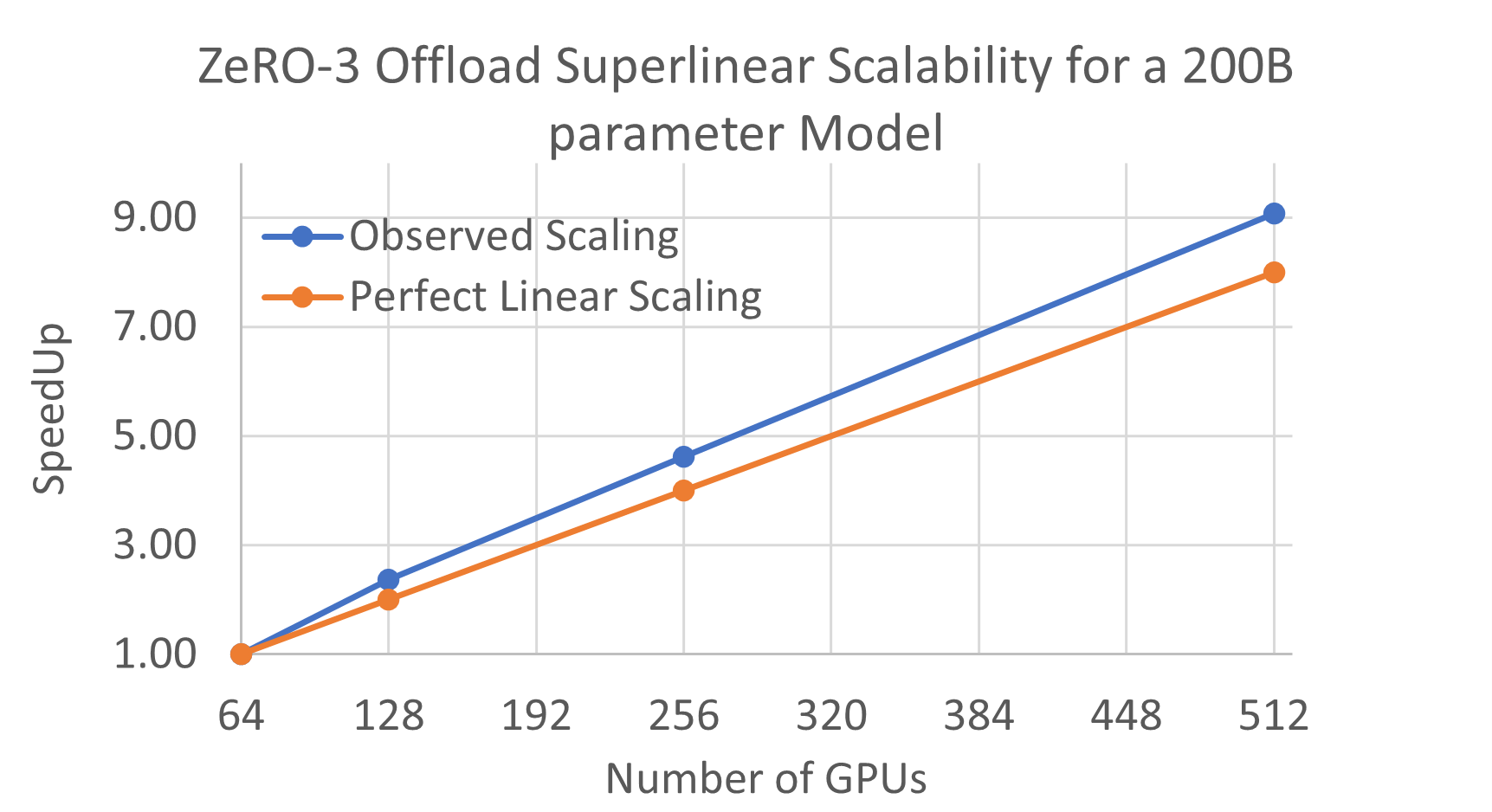 图 4. ZeRO-3 Offload 对 2000 亿参数模型的超线性可扩展性。
图 4. ZeRO-3 Offload 对 2000 亿参数模型的超线性可扩展性。
如何使用 ZeRO-3 Offload
与许多其他现有 DeepSpeed 功能一样,一旦用户模型已转换为使用 DeepSpeed,启用 ZeRO-3 Offload 就像在 DeepSpeed 配置文件中打开几个标志一样简单。支持权重共享等高级功能,或启用需要跨 GPU/节点分区以适应 GPU/CPU 内存的超大型模型,只需使用 ZeRO-3 Offload API 进行几行额外的代码更改即可完成。
如果您已经是 DeepSpeed 用户,您可以在下方找到我们关于 ZeRO-3 Offload 的详细教程。如果您是 DeepSpeed 的新用户,我们建议您在尝试我们的 ZeRO-3 Offload 教程之前,先从入门页面开始。
DeepSpeed 团队非常高兴能与深度学习社区分享 ZeRO-3 Offload。