DeepSpeed 模型压缩库
什么是 DeepSpeed 压缩: DeepSpeed 压缩是一个专门构建的库,旨在让研究人员和实践者能够轻松地压缩模型,同时提供更快的速度、更小的模型尺寸和显著降低的压缩成本。
为何使用 DeepSpeed 压缩: DeepSpeed 压缩提供了新颖的、最先进的压缩技术,以实现更快的模型压缩,同时具有更好的模型质量和更低的压缩成本。DeepSpeed 压缩还采用端到端的方法,通过高度优化的推理引擎来提高压缩模型的计算效率。此外,我们的库内置了多种最先进的压缩方法。它支持这些方法与系统优化的协同组合,在提供两全其美优势的同时,也为高效的 DL 模型推理提供了一个无缝且易于使用的流水线。我们强烈建议您阅读我们的博客,以(从宏观层面)了解更多关于我们为何构建 DeepSpeed 压缩以及它为用户带来的好处。
如何使用 DeepSpeed 压缩: 第一节“一般教程”将介绍库支持的压缩方法。以下章节将介绍我们关于如何组合不同压缩方法以执行零成本量化 (ZeroQuant) 和极限压缩 (XTC) 的研究工作。除非另有说明,下面列出的实验结果均基于 NVIDIA A100 GPU,并且我们观察到在使用不同 GPU 硬件时结果略有不同。
1. 一般教程
要使用 DeepSpeed 压缩库,您需要按照安装指南安装 DeepSpeed >= 0.7.0。目前 DeepSpeed 压缩包括七种压缩方法:通过知识蒸馏进行的层减少、权重 量化、激活 量化、稀疏剪枝、行剪枝、头剪枝和通道剪枝。在以下小节中,我们将介绍这些方法是什么、何时使用它们以及如何通过我们的库使用它们。
1.1 层减少
什么是层减少
神经网络由输入层、输出层和隐藏层构成。例如,BERT-base 语言模型由嵌入层(输入层)、分类层(输出层)和 12 个隐藏层组成。层减少意味着减少隐藏层的数量,同时保持网络宽度不变(即,不减少隐藏层的维度)。无论硬件和/或场景如何,此方法都可以线性减少隐藏层的推理延迟。
何时使用层减少
如果模型非常深,您可以考虑使用此方法。在应用知识蒸馏时,它的效果会好得多。层减少可以应用于预训练和微调阶段。前者生成一个蒸馏后的任务无关模型,而后者生成一个任务特定的蒸馏模型。在我们的 XTC 工作(论文,教程)中,我们也讨论了何时应用层减少。
如何使用层减少
层减少可以通过 DeepSpeed 配置 JSON 文件进行启用和配置(配置详情)。用户可以自由地通过 keep_number_layer 选择任何深度,并通过 teacher_layer 选择网络层的任何子集。此外,用户还可以选择是否通过 other_module_name 从给定模型(教师模型)重新初始化输入/输出层。
要应用层减少进行任务特定压缩,我们提供了一个如何在 BERT 微调中实现此功能的示例。层减少涉及重置网络架构的深度和权重参数的重新初始化,这发生在训练过程之前。该示例包括对客户端代码(位于 DeepSpeedExamples 的 compression/bert/run_glue_no_trainer.py)的以下更改:
(1) 初始化模型时,模型配置中的层数应与 DeepSpeed 配置 JSON 文件中的 keep_number_layer 相同。对于 Hugging Face BERT 示例,设置 config.num_hidden_layers = ds_config["compression_training"]["layer_reduction"]["keep_number_layer"]。
(2) 然后,我们需要使用从 deepspeed.compression.compress 导入的 init_compression 函数,根据 DeepSpeed JSON 配置重新初始化模型。
(3) 在训练期间,如果未使用 KD,则无需执行任何操作。否则,在计算教师模型和学生模型输出之间的差异时,需要考虑使用 teacher_layer JSON 配置应用 KD。
您可以通过以下方式在 DeepSpeedExamples 中运行我们的层减少示例:
DeepSpeedExamples/compression/bert$ pip install -r requirements.txt
DeepSpeedExamples/compression/bert$ bash bash_script/layer_reduction.sh
最终结果是
Epoch: 18 | Time: 12m 38s
Clean the best model, and the accuracy of the clean model is acc/mm-acc:0.8340295466123281/0.8339096826688365
为了将层减少应用于任务无关压缩,我们提供了一个在 GPT 预训练阶段实现此功能的示例。
步骤 1:获取最新版本的 Megatron-DeepSpeed。
步骤 2:进入 Megatron-DeepSpeed/examples_deepspeed/compression 目录。
步骤 3:运行示例 bash 脚本,例如 ds_pretrain_gpt_125M_dense_cl_kd.sh。与预训练蒸馏相关的参数是:
(1)--kd,启用知识蒸馏。
(2)--kd-beta-ce,指定知识蒸馏系数。通常可以将其设置为默认值 1,但有时调整此超参数会带来更好的蒸馏结果。
(3)--num-layers-teacher、—hidden-size-teacher、num-attention-heads-teacher,这些参数指定了教师模型的网络配置。请确保它们与检查点中的教师模型维度匹配。
(4)--load-teacher,在此处指定教师模型检查点。
(5)--load,这是将要加载的学生模型的初始检查点。默认情况下,它将加载教师模型的底层进行初始化,但您可以传递自己的检查点进行初始化。
除了上述配置,您可能还需要修改 data_options 中的数据路径,以便训练器知道数据位置。为了稍微简化,我们提供了几个示例脚本,用于运行不同模型大小的蒸馏,包括 350M (ds_pretrain_gpt_350M_dense_kd.sh) 和 1.3B 模型 (ds_pretrain_gpt_1.3B_dense_cl_kd.sh)。我们还根据经验发现,分阶段 KD 通常会在下游任务上产生更好的预训练蒸馏模型。因此,我们建议通过不设置提供的脚本中的 --kd 来轻松地提前停止 KD(例如,在剩余 40% 的训练中禁用 KD)。
步骤 4:蒸馏模型后,还可以选择通过运行脚本 125M-L10-Int8-test-64gpu-distilled-group48.sh 来进一步量化蒸馏模型,该脚本使用 INT8 量化器对蒸馏模型的权重和激活进行量化(权重和激活量化将在以下章节中介绍)。请注意,执行量化时需要设置 -reset-iteration 标志。下表提供了来自 WikiText-2 和 LAMBADA 的零样本困惑度结果。
| GPT (125M) | 层数 | wikitex2 困惑度 | LAMBADA |
|---|---|---|---|
| 未压缩 | 12 | 29.6 | 39.5 |
| 仅量化 | 12 | 29.8 | 39.7 |
| 仅蒸馏 | 10 | 31.9 | 39.2 |
| 蒸馏 + 量化 | 10 | 32.28 | 38.7 |
1.2 权重量化
什么是权重量化
权重量化将全精度权重(FP32/FP16)映射到低位权重,如 INT8 和 INT4。引用自本 Coursera 讲座:“量化涉及将模型转换为使用较低精度参数和计算的等效表示。这提高了模型的执行性能和效率,但通常会导致模型精度降低。”
何时使用权重量化
一方面,再次引用自本 Coursera 讲座:“移动和嵌入式设备计算资源有限,因此保持应用程序资源高效非常重要。根据任务的不同,您需要在模型精度和模型复杂度之间进行权衡。如果您的任务需要高精度,那么您可能需要一个大型且复杂的模型。对于需要较低精度的任务,最好使用更小、更简单的模型。”。另一方面,像 GPU 这样的最新服务器加速器支持低精度算术。因此,将权重 量化与激活 量化(在后面章节介绍)结合起来也可以提供更好的效率。
如何使用权重量化
权重 量化可以通过 DeepSpeed 配置 JSON 文件进行启用和配置(配置详情)。我们想指出的关键配置有:
(1)quantize_groups,一种组式权重矩阵量化:权重矩阵 W 被划分为多个组,每个组分别进行量化。更多详情请参见这篇论文。
(2)quantize_weight_in_forward,对于 FP32 优化器训练必须设置为 true,对于 FP16 则设置为 false。
(3)wq1/wq2,用户可以扩展更多组,例如 wq3、wq4 等。
(4)start_bit 和 target_bit,为了简化首次实验,我们建议将它们设置为相同,这样一旦迭代达到 schedule_offset,我们就将量化应用到目标位。
客户端代码(位于 DeepSpeedExamples 的 compression/bert/run_glue_no_trainer.py)有两处更改:
(1) 模型初始化后,使用 DeepSpeed JSON 配置将 init_compression 函数应用于模型。
(2) 训练后,应用 redundancy_clean 函数保存量化权重。
您可以通过以下方式在 DeepSpeedExamples 中运行我们的权重 量化示例:
DeepSpeedExamples/compression/bert$ pip install -r requirements.txt
DeepSpeedExamples/compression/bert$ bash bash_script/quant_weight.sh
最终结果是
Epoch: 09 | Time: 27m 10s
Clean the best model, and the accuracy of the clean model is acc/mm-acc:0.8414671421293938/0.8422497965825875
1.3 激活量化
什么是激活量化
激活是指每一层的输入。激活量化将输入从全精度/半精度映射到低精度。更多详情请参见此博客。
何时使用激活量化
它可以提高计算效率,类似于权重量化。
如何使用激活量化
激活量化可以通过 DeepSpeed 配置 JSON 文件进行启用和配置(配置详情)。其中一些组件与权重 量化相同,例如 schedule_offset 和 quantization_type。我们想指出的关键配置有:
(1)range_calibration,用户可以选择设置为动态或静态。当使用“dynamic”时,激活量化组将自动设置为逐 token(对于基于 Transformer 的模型)和逐图像(对于基于 CNN 的模型)。更多详情请参见我们的 ZeroQuant 论文和代码(位于 DeepSpeed 的 deepspeed/compression/basic_layer.py)。
(2)aq1/aq2,用户可以扩展更多组,例如 aq3、aq4 等。
客户端代码的更改与权重量化相同。
您可以通过以下方式在 DeepSpeedExamples 中运行我们的激活量化示例:
DeepSpeedExamples/compression/bert$ pip install -r requirements.txt
DeepSpeedExamples/compression/bert$ bash bash_script/quant_activation.sh
最终结果是
Epoch: 02 | Time: 28m 50s
Clean the best model, and the accuracy of the clean model is acc/mm-acc:0.8375955170657158/0.8422497965825875
1.4 剪枝
什么是剪枝
剪枝旨在通过移除网络连接来减少生成预测所需的参数和操作数量。通过剪枝,您可以降低网络中总体的参数数量(更多详情请参见本 Coursera 讲座)。我们可以将剪枝策略分为两种类型:结构化剪枝和非结构化剪枝(更多详情请参见这篇论文)。
| 方法 | 类型 |
|---|---|
| 稀疏剪枝 | 非结构化和结构化 |
| 行剪枝 | 结构化 |
| 头剪枝 | 结构化 |
| 通道剪枝 | 结构化 |
1.4.1 稀疏剪枝
什么是稀疏剪枝
稀疏剪枝意味着我们将每个权重矩阵中的一些元素设置为零值。根据用户选择的剪枝方法,零值可能具有结构化模式或非结构化模式。一种执行剪枝的方法是基于权重参数的绝对值,例如参见这篇论文。另一种执行剪枝的方法是基于权重在被掩码时对损失函数的影响,例如参见这篇论文。
何时使用稀疏剪枝
如果您的模型参数过多,您可以考虑使用稀疏剪枝。然而,要看到硬件计算效率的真正好处,密度比(剪枝后保留的权重百分比)必须相当低。
如何使用稀疏剪枝
稀疏剪枝可以通过 DeepSpeed 配置 JSON 文件进行启用和配置(配置详情)。我们想指出的关键配置有:
(1)schedule_offset,我们根据经验发现,当使用 method: topk 时,最好将 schedule_offset 设置为一个较大的值,例如总训练步数的 10%。
(2)method,我们支持 L1 范数、topk 和 snip_momentum 方法。欢迎用户贡献更多方法。
(3)sp1,用户可以扩展更多组,例如 sp2、sp3 等。请注意,snip_momentum 方法不需要此项。
(4)dense_ratio,对于非结构化稀疏剪枝,BERT-base 模型的稠密比可以小于 0.1,同时仍能保持良好的准确性。对于 ResNet-50,稠密比可以低至 0.3,同时在 ImageNet 上仍具有良好的准确性。对于结构化稀疏剪枝(如 snip_momentum),稠密比应在 shared_parameters 中指定,并用于计算全局稀疏度比。
(5)frequency、block_pattern 和 schedule_offset_end,它们用于指定剪枝的步长频率、块状剪枝模式(NxM 和 N in M)以及剪枝的结束步。对于 snip_momentum 方法,这些配置是强制性的。
客户端代码的更改与权重量化相同。
您可以通过以下方式在 DeepSpeedExamples 中运行我们的稀疏剪枝示例:
DeepSpeedExamples/compression/bert$ pip install -r requirements.txt
DeepSpeedExamples/compression/bert$ bash bash_script/pruning_sparse.sh
最终结果是
Epoch: 02 | Time: 26m 14s
Clean the best model, and the accuracy of the clean model is acc/mm-acc:0.8416709118695873/0.8447925142392189
1.4.2 行剪枝
什么是行剪枝
行剪枝将权重矩阵中某些行的所有元素设置为零值。如果一行被剪枝,该行中的所有元素都将设置为零。
何时使用行剪枝
行剪枝有利于硬件加速,比稀疏剪枝效果好得多(但与稀疏剪枝相比,可能导致更大的精度损失)。这是一项专为两个连续线性层(例如 Transformer 中的前馈网络)设计的功能。因此,我们建议对第一个线性层(即 BERT 的 intermediate.dense 层)使用行剪枝。减少此矩阵的行维度有助于减少后续矩阵(即 BERT 的 layer.\\w+.output.dense 层)的列。行剪枝也适用于其他类型的线性层。
如何使用行剪枝
行剪枝可以通过 DeepSpeed 配置 JSON 文件进行启用和配置(配置详情)。我们想指出的关键配置有:
(1)method,目前仅支持 topk 方法。欢迎用户贡献更多方法。
(2)rp1,用户可以扩展更多组,例如 rp2、rp3 等。
(3)related_modules,如“何时使用行剪枝”中所述,如果进行行剪枝,后续矩阵将受到影响。因此,需要了解模块之间的连接。
客户端代码的更改与权重量化相同。
您可以通过以下方式在 DeepSpeedExamples 中运行我们的行剪枝示例:
DeepSpeedExamples/compression/bert$ pip install -r requirements.txt
DeepSpeedExamples/compression/bert$ bash bash_script/pruning_row.sh
最终结果是
Epoch: 02 | Time: 27m 43s
Clean the best model, and the accuracy of the clean model is acc/mm-acc:0.8440142638818136/0.8425549227013832
1.4.3 头剪枝
什么是头剪枝
头剪枝是专门为具有多头注意力的网络设计的,例如基于 Transformer 的模型(更多详情请参见此博客)。例如,BERT-base(BERT-large)模型有 12 个头(24 个头)。
何时使用头剪枝
头剪枝有利于硬件加速。此外,正如此博客所述:“在论文中,观察到令人惊讶的结果:即使在正常训练模型(包含所有头)之后,许多头在测试时也可以被移除,并且不会显著影响 BLEU 分数,事实上,在某些情况下移除少数头甚至可以提高 BLEU 分数。”。
注意:头剪枝是专为注意力层(例如 Transformer 中的多头注意力)设计的功能。目前,它只能应用于 Transformer 的输出矩阵(即 BERT 中的 attention.output.dense)。剪枝输出矩阵也可能导致查询/键/值矩阵的剪枝。
如何使用头剪枝
头剪枝可以通过 DeepSpeed 配置 JSON 文件进行启用和配置(配置详情)。我们想指出的关键配置有:
(1)num_heads:用户需要为他们的模型提供正确的头数。
(2)modules:模块 attention.output.dense 专门为 Hugging Face BERT 模型制作。目前,我们仅支持当查询/键/值是独立矩阵且后面跟着 attention.output.dense 的情况。我们乐于提供帮助并欢迎对注意力模型的变体做出贡献。
(3)related_modules:如“何时使用头剪枝”中所述,剪枝注意力输出矩阵也可能导致 QKV 矩阵的剪枝。因此,这里的输入是 ["self.query", "self.key", "self.value"]。
客户端代码的更改与权重量化相同。
您可以通过以下方式在 DeepSpeedExamples 中运行我们的头剪枝示例:
DeepSpeedExamples/compression/bert$ pip install -r requirements.txt
DeepSpeedExamples/compression/bert$ bash bash_script/pruning_head.sh
最终结果是
Clean the best model, and the accuracy of the clean model is acc/mm-acc:0.8397350993377484/0.8377746135069162
1.4.4 通道剪枝
什么是通道剪枝
通道剪枝是专为卷积层和计算机视觉设计的。根据 wikipedia.org,“图像的颜色数据存储在三个值数组中,称为通道。”。例如,一张具有三个通道的图像通过 ResNet-18 后,第一层会产生 64 个通道。
何时使用通道剪枝
通道剪枝是专为两个连续的 CONV2d 层(例如 ResNet 中的残差连接)设计的功能。因此,我们建议对第一个 CONV2d 层使用通道剪枝。减少此层的输出通道数可以帮助减少下一层的输入通道数。通道剪枝也适用于其他类型的 CONV2d 层。
如何使用通道剪枝
通道剪枝可以通过 DeepSpeed 配置 JSON 文件进行启用和配置(配置详情)。
您可以通过以下方式在 DeepSpeedExamples 中运行我们的通道剪枝示例:
pip install torch torchvision
DeepSpeedExamples/compression/cifar$ bash run_compress.sh
最终结果是
after_clean
epoch 10 testing_correct: 0.7664
请注意,上述结果是在“ResNet”模型中不使用批归一化(BN)时的情况。如果您的模型使用了 BN 并应用了通道剪枝,则模型清理后的验证结果将与清理前的模型不同。我们建议用户在这些情况下,在应用 redundancy_clean 后进一步微调模型。
2. ZeroQuant 教程:高效且经济的训练后量化
在本节中,我们将介绍如何应用 DS-Compression 进行无成本 INT8 量化和轻量级 INT4/INT8 混合精度量化。欲了解更多详情,请参阅我们的论文。
什么是 ZeroQuant
ZeroQuant 是一种高效的训练后量化方法,包括:(1) 一种细粒度且硬件友好的权重和激活量化方案,可以显著减少量化误差;(2) 一种新颖且经济实惠的逐层知识蒸馏算法 (LKD),即使在无法访问原始训练数据的情况下也能使用;(3) 高度优化的量化系统后端支持,以消除量化/反量化开销。通过这些技术,ZeroQuant 能够 (1) 零成本将模型量化为 INT8,以及 (2) 以最小的资源需求(例如,BERT-base 量化仅需 31 秒)将模型量化为 INT4/INT8 混合精度。
何时使用 ZeroQuant
当您想将基于 Transformer 的模型量化为 INT8 或 INT4/INT8 格式时,总是最好先尝试 ZeroQuant,尤其是在模型进行量化感知训练非常耗费资源(GPU 和/或时间)以及/或者无法访问原始训练数据的情况下。
如何使用 ZeroQuant
您可以通过以下方式在 DeepSpeedExamples 中运行我们的 BERT 示例:
DeepSpeedExamples/compression/bert$ pip install -r requirements.txt
DeepSpeedExamples/compression/bert$ bash bash_script/ZeroQuant/zero_quant.sh
最终结果是
Clean the best model, and the accuracy of the clean model is acc/mm-acc:0.8427916454406521/0.8453010577705452
您可以通过以下方式运行我们的 GPT 示例:
DeepSpeedExamples/compression/gpt2$ pip install -r requirements.txt
DeepSpeedExamples/compression/gpt2$ bash bash_script/run_zero_quant.sh
最终结果是
Before converting the module COVN1D to linear and init_compression: 19.371443732303174
Before cleaning, Epoch at 0 with Perplexity: 19.47031304212775
After cleaning with Perplexity: 19.47031304212775
注意:目前,我们仅支持零成本量化。请继续关注 ZeroQuant 论文中提出的逐层知识蒸馏的代码发布。
3. XTC 教程:简单而有效的极限压缩流水线
在本节中,我们将介绍如何应用 DeepSpeed 压缩库执行轻量级层减少和超低位精度(二值/三值)量化。特别是,我们将指导您如何实现XTC 方法,即:
(1) 获得具有 8 位激活量化的 1 位或 2 位 BERT-base(12 层)模型。
(2) 将 12 层 BERT-base 减少到 5 层,然后获得其 1 位或 2 位对应的模型。
什么是 XTC
XTC(eXTreme Compression 的简称)是我们新的简单而高效的方法,通过轻量级层减少和鲁棒的二值化将模型压缩到极限。XTC 通过简单而有效的二值化技术,将模型大小减少 32 倍,同时在 GLUE 任务上的平均分数几乎没有损失。通过结合极限量化和轻量级层减少,我们可以进一步改进二值化模型,实现 50 倍的模型大小减少,同时保持 97% 的准确率。欲了解更多详情,请参阅我们的论文,其中我们系统地研究了当前用于极限压缩的各种技术的影响。
何时使用 XTC
如果您希望在保留有竞争力性能的同时显著压缩模型,XTC 可能是一个理想的选择。它是一种简单且易于超参数调优的方法。
如何使用 XTC
安装: BERT 模型的 XTC 极限压缩示例位于 DeepSpeedExamples 中的 compression/bert/bash_script/XTC。您需要通过以下方式安装所需依赖:
DeepSpeedExamples/compression/bert$ pip install -r requirements.txt
XTC 方法的实现: 为了方便没有微调模型或任务特定模型进行压缩的用户,我们的 python 脚本 run_glue_no_trainer.py 通过参数 --model_name_or_path yoshitomo-matsubara/bert-base-uncased-${TASK_NAME} 自动从 Hugging Face 下载模型。用户也可以使用自己具有更高准确率的模型作为教师模型和学生模型初始化。
3.1 具有 8 位激活量化的 1 位或 2 位 BERT-base(12 层)模型
有关配置,请参阅 DeepSpeedExamples 中的 compression/bert/config/XTC/ds_config_W1A8_Qgroup1_fp32.json。在我们的论文中,我们使用 FP32 ("fp16": {"enabled": false}) 进行训练,同时在训练开始时 ("schedule_offset": 0) 直接对激活应用 8 位量化 ("bits": 8),对注意力(query、key、val)和前馈权重矩阵 ("modules": ["attention.self", "intermediate", "output.dense"]) 应用 1 位量化 ("start_bits": 1, "target_bits": 1)。此外,我们还将 1 位量化应用于 word_embeddings 作为权重量化。
您可以通过以下方式运行此示例:
DeepSpeedExamples/compression/bert$ bash bash_script/XTC/quant_1bit.sh
最终结果是
Clean the best model, and the accuracy of the clean model is acc/mm-acc:0.8293428425878757/0.8396053702196908
我们想提到的另一个重要特性是 weight_quantization 中的 quantize_groups,这里设置为 1 以匹配我们 XTC 论文的 FP32 训练设置。我们发现,在 FP16 训练下,较少数量的量化组(例如 1 或 2)可能导致训练不稳定。因此,我们建议在 FP16 下使用更多数量的组(例如 64)。DeepSpeedExamples 中的 compression/bert/config/ds_config_W1A8_Qgroup64_fp16.json 是 FP16 示例配置,其中 "fp16": {"enabled": true} 和 "weight_quantization": {"shared_parameters": {"quantize_weight_in_forward": false}} 与 FP32 情况不同。
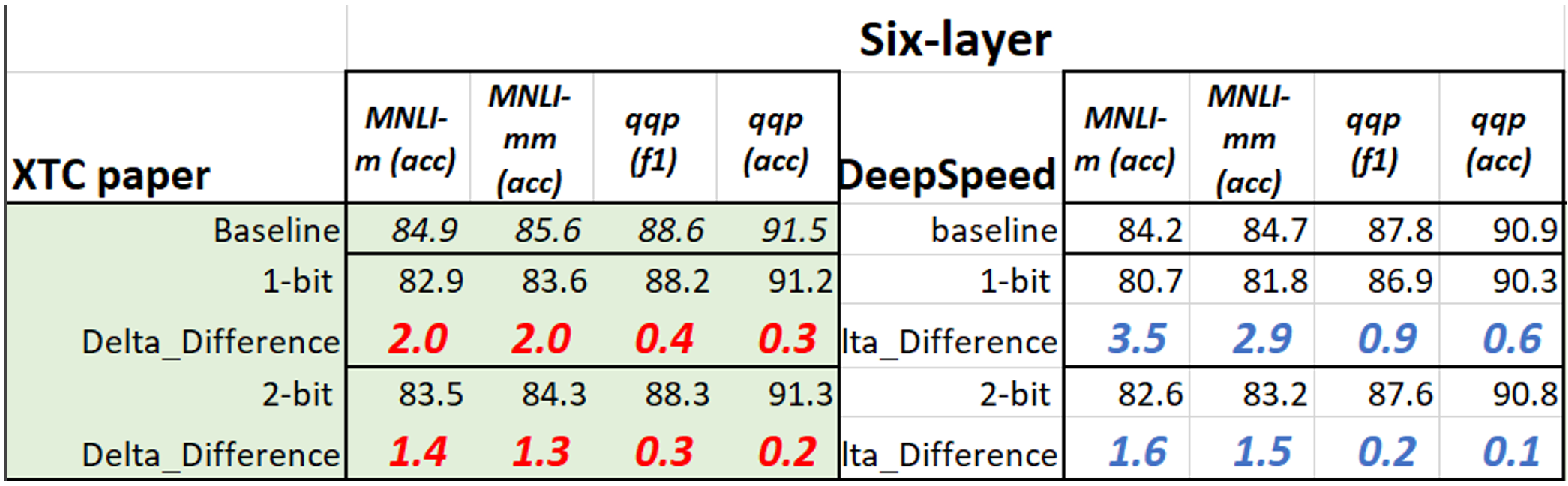
使用此配置,我们量化从 Hugging Face 下载的现有微调模型。对于 2 位权重量化,用户需要更新 ds_config JSON 文件。为了让您了解下载模型与我们论文中模型的压缩性能差异,我们在下表中收集了结果(在 MNLI 和 QQP 上,经过 18 个训练周期后的 1/2 位 BERT)。本教程与论文之间的差异是由于使用了不同的检查点。在TinyBERT中引入的数据增强将对较小任务(如 mrpc、rte、sst-b 和 cola)有显著帮助。更多详情请参阅我们的论文。
3.2 将 12 层 BERT-base 压缩到 1 位或 2 位的 6/5 层 BERT
本节包含两个部分:(a) 我们首先执行轻量级层减少,以及 (b) 基于 (a) 中的模型,我们执行 1 位或 2 位量化。
3.2.1 轻量级层减少
DeepSpeedExamples 中的 compression/bert/config/XTC/ds_config_layer_reduction_fp16.json 是将 12 层 BERT-base 减少到 6 层的示例配置。学生模型的层从教师模型的第 i 层初始化,其中 i=[1, 3, 5, 7, 9, 11](注意层从 0 开始),这在我们的 XTC 论文中被称为 Skip-BERT_5。此外,学生模型的模块,包括嵌入层、池化层和分类器,也从教师模型初始化。对于 5 层层减少,需要将 ds_config_layer_reduction_fp16.json 中的配置更改为 "keep_number_layer": 5,"teacher_layer": [2, 4, 6, 8, 10](如 compression/bert/config/ds_config_TEMPLATE.json 中所示)。
您可以通过以下方式运行此示例:
DeepSpeedExamples/compression/bert$ bash bash_script/XTC/layer_reduction.sh
最终结果是
Clean the best model, and the accuracy of the clean model is acc/mm-acc:0.8377992868059093/0.8365541090317331
值得注意的是,当使用单阶段知识蒸馏 (--distill_method one_stage) 时,教师模型和学生模型输出之间的差异(att_loss 和 rep_loss)也需要与初始化保持一致。请参阅 compression/bert/util.py 中 forward_loss 下的 _kd_function 函数。
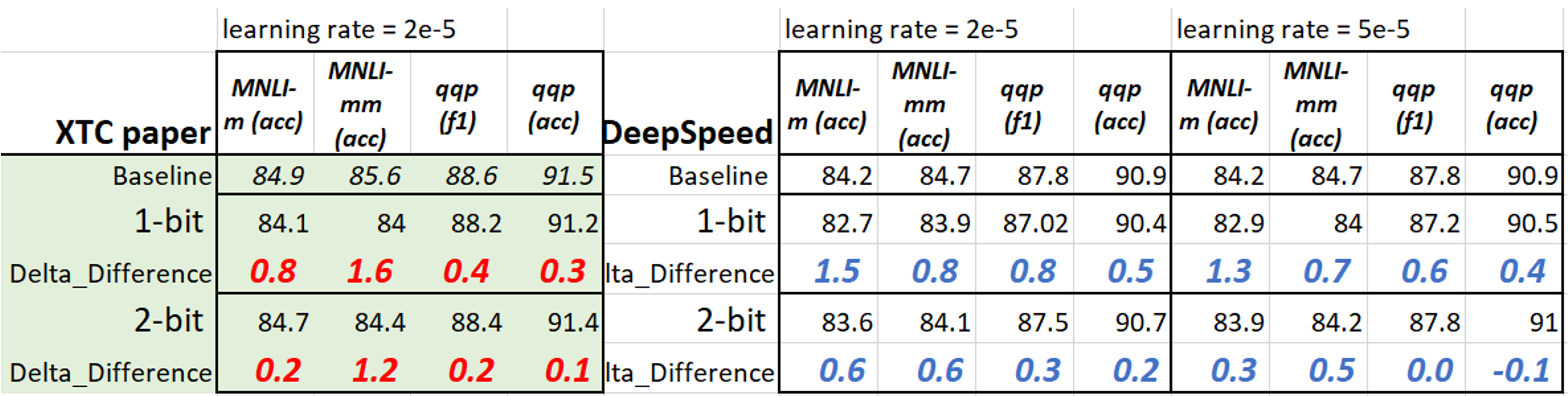
对于 mnli/qqp,我们设置了 --num_train_epochs 36、--learning_rate 5e-5,并使用了上述 JSON 配置。结果如下(我们还包括了 fp16 训练结果)。使用 fp32 显然比 fp16 带来更稳定的性能,尽管 fp16 可以加快训练时间。
3.2.2 6 层(5 层)BERT 的 1 位或 2 位量化
在准备好上述层减少模型后,我们现在继续使用 1/2 位量化来压缩模型。DeepSpeedExamples 中的 compression/bert/config/XTC/ds_config_layer_reduction_W1Q8_fp32.json 是一个示例配置,其中我们在 compression/bert/config/XTC/ds_config_W1A8_Qgroup1_fp32.json 的基础上将层减少设置为 true。除了配置之外,我们还需要在脚本 compression/bert/bash_script/XTC/layer_reduction_1bit.sh 中使用 --pretrained_dir_student 更新学生模型的路径。用户可以通过添加 --pretrained_dir_teacher 来使用不同的教师模型进行训练。
您可以通过以下方式运行此示例:
DeepSpeedExamples/compression/bert$ bash bash_script/XTC/layer_reduction_1bit.sh
最终结果是
Epoch: 18 | Time: 18m 11s
Clean the best model, and the accuracy of the clean model is acc/mm-acc:0.8140601120733572/0.8199755899104963
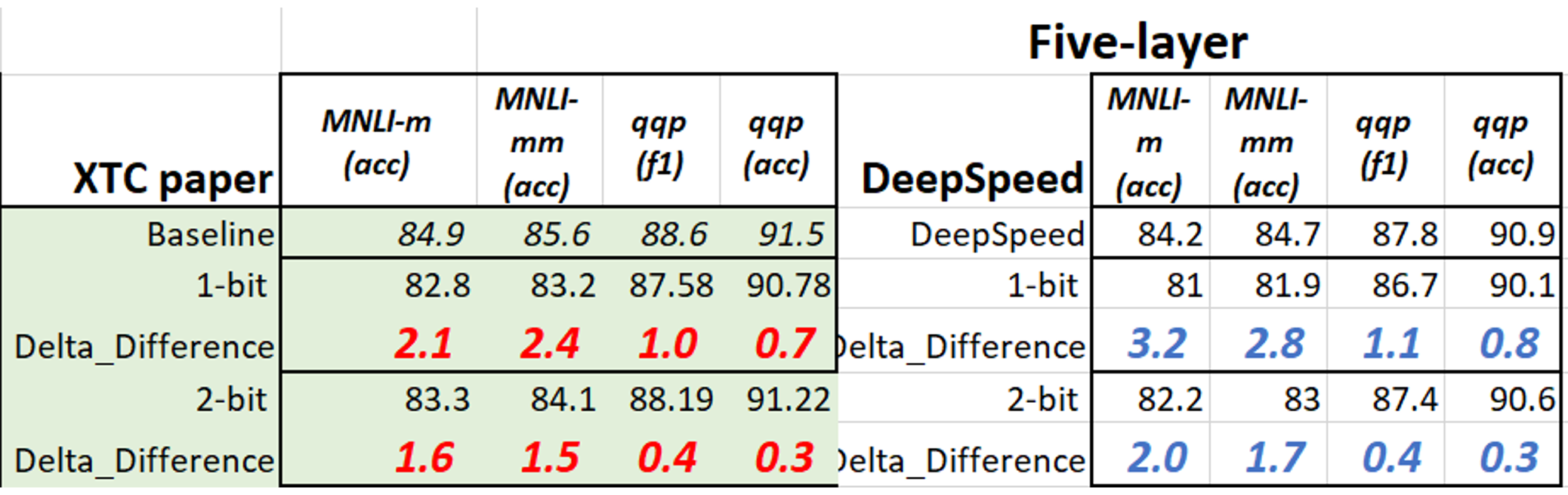
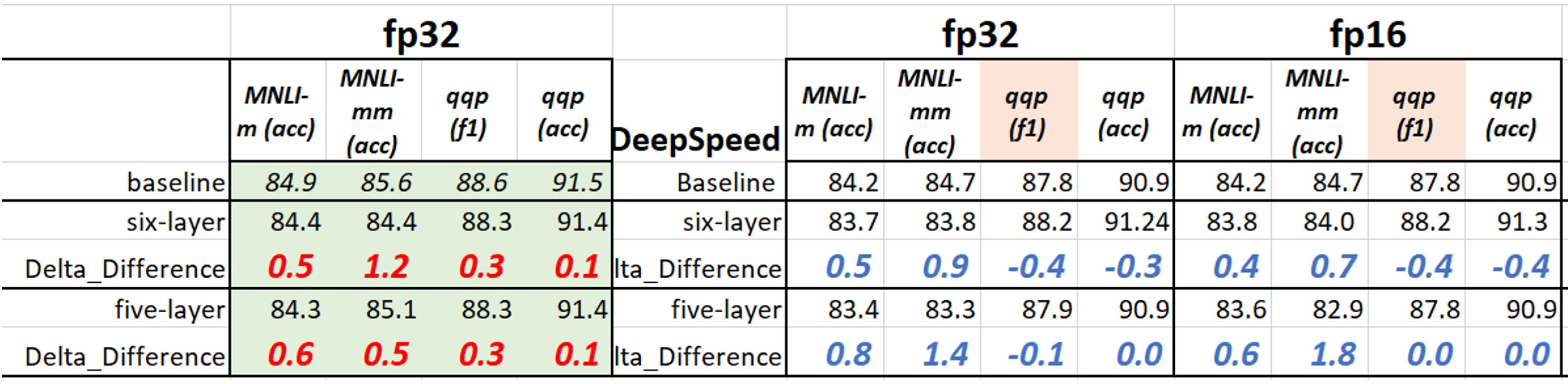
通过上述命令,现在可以获得 1 位 6 层模型的结果。现在我们在下表中列出了 2-/1 位 6/5 层模型的更多结果。请注意,我们用于下方压缩的检查点来自 3.2.1 节中的上表。