DeepSpeed-MoE 用于 NLG:将语言模型的训练成本降低 5 倍
自回归 transformer-based 自然语言生成(在博客其余部分简称 NLG)模型可以为广泛的语言任务提供令人信服的解决方案,从文档摘要、标题生成、问答,甚至到生成各种编程语言的代码。由于这些模型的普遍适用性,提高其质量一直是学术界和工业界共同关注的重点。
NLG 的质量随模型规模的增加而提高。然而,如今我们正接近当前一代硬件所能达到的极限。Megatron-Turing NLG 530B 模型在 NVIDIA Selene 超级计算机上使用 2000 多个 A100 GPU 训练了 3 个月,消耗了超过 300 万 GPU 小时。模型规模再增加 3 到 5 倍在合理的时间范围内将是不可行的。鉴于训练最先进的 NLG 模型需要天文数字般的计算资源,一个很自然的问题是:“在不增加计算成本的情况下,是否有可能对模型质量进行显著改进?” 或者等价地问:“是否有可能使用少 3 到 5 倍的资源来生成具有相似质量的模型?”
最近的研究,例如 GShard 和 Switch Transformers,表明专家混合 (MoE) 模型结构可以显著降低基于 transformer 的编码器-解码器模型的训练成本。MoE 模型包含一组稀疏门控专家。在训练和推理过程中,每个输入 token 只会激活这些专家中的一个子集。因此,模型可以扩展到数十亿个参数,而计算量不会按比例增加。尽管显示出有希望的结果,但 MoE 对于计算密集得多的 NLG 系列模型的有效性在很大程度上仍未可知。
鉴于训练 NLG 系列模型需要巨大的计算和能源开销,我们探索了 MoE 在降低其训练成本方面所带来的机会。我们表明,MoE 可以应用于 NLG 系列模型,在相同训练成本下显著提高其模型质量。或者,它也可以将训练成本降低 5 倍,以达到与密集型 NLG 模型相同的模型质量。例如,通过应用 MoE,我们以训练 1.3B 参数密集型模型的成本,实现了 6.7B 参数密集型 NLG 模型的模型质量,这得益于 MoE 的稀疏结构。
假设这种扩展性成立,这些结果有潜力彻底改变大型模型训练的成本格局。例如,一个万亿参数的密集模型有可能以训练 200B 参数(如 GPT-3)规模的密集模型的成本进行训练,这意味着数百万美元的训练成本降低和能源节约(Brown 等人,2020 年,《语言模型是少样本学习器》)。
基于 MoE 的 NLG 模型架构
为了创建基于 MoE 的 NLG 模型,我们研究了类 GPT 的基于 transformer 的 NLG 模型。为了在合理的时间范围内完成训练,我们选择了以下模型:350M(24 层,1024 隐藏层大小,16 个注意力头)、1.3B(24 层,2048 隐藏层大小,16 个注意力头)和 6.7B(32 层,4096 隐藏层大小,32 个注意力头)。我们使用“350M+MoE-128”来表示一个 MoE 模型,该模型使用 350M 密集模型作为基础模型,并在每隔一个前馈层上添加 128 个专家。也就是说,对于 350M+MoE-128 和 1.3B+MoE-128,总共有 12 个 MoE 层。
我们使用门控函数来激活 MoE 层中每个 token 的一部分专家。具体而言,在我们的实验中,只选择 top-1 专家。因此,在训练和推理过程中,我们的 MoE 模型为每个 token 激活的参数数量与其密集部分相同。例如,我们的 1.3B+MoE-128 模型每个 token 只会激活 1.3B 参数,并且每个 token 的训练计算量将与 1.3B 密集模型相似。
MoE 训练基础设施和数据集
我们使用 DeepSpeed 在 128 块 A100 GPU 上预训练了上述模型的密集版本和 MoE 版本。DeepSpeed 结合了数据并行和专家并行训练,以有效扩展 MoE 模型训练。
我们使用了与 MT-NLG 博客中描述的相同训练数据。为了公平比较,我们使用 300B token 来训练密集模型和 MoE 模型。
MoE 提升 NLG 模型质量
图 1 显示,MoE 模型的验证损失显著优于其对应的密集模型。此外,请注意 MoE 模型 350M+MoE-128 的验证损失与基础规模大 4 倍的 1.3B 密集模型的验证损失不相上下。与基础规模大 5 倍的 6.7B 密集模型相比,1.3B+MoE-128 也是如此。此外,模型质量不仅在验证损失方面不相上下,而且在表 1 所示的各种 6 项零样本评估任务中也表现出同等水平,这表明这些模型实际上具有非常相似的模型质量。
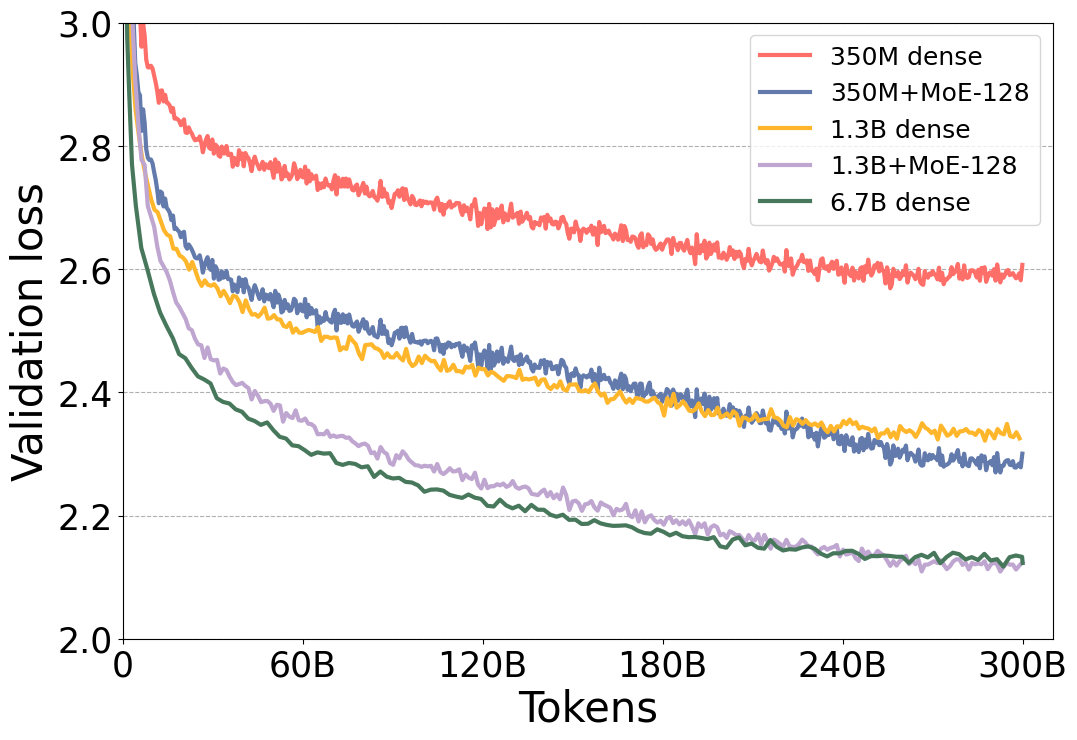
图 1:不同模型大小的密集型和 MoE NLG 模型的逐 token 验证损失曲线。
| 模型尺寸 | LAMBADA:补全预测 | PIQA:常识推理 | BoolQ:阅读理解 | RACE-h:阅读理解 | TriviaQA:问答 | WebQs:问答 |
|---|---|---|---|---|---|---|
| 密集型 NLG | ||||||
| 350M | 0.5203 | 0.6931 | 0.5364 | 0.3177 | 0.0321 | 0.0157 |
| 1.3B | 0.6365 | 0.7339 | 0.6339 | 0.3560 | 0.1005 | 0.0325 |
| 6.7B | 0.7194 | 0.7671 | 0.6703 | 0.3742 | 0.2347 | 0.0512 |
| MoE NLG | ||||||
| 350M+MoE-128 (13B) | 0.6270 | 0.7459 | 0.6046 | 0.3560 | 0.1658 | 0.0517 |
| 1.3B+MoE-128 (52B) | 0.6984 | 0.7671 | 0.6492 | 0.3809 | 0.3129 | 0.0719 |
表 1:不同密集型和 MoE NLG 模型的零样本评估结果(后六列)。所有零样本评估结果均使用准确率指标。
相同质量,训练成本降低 5 倍
正如我们从上述结果中看到的,向 NLG 模型添加包含 128 个专家的 MoE 显著提高了 NLG 模型的质量。然而,这些专家并没有改变模型的计算需求,因为每个 token 只由一个专家处理。因此,密集模型及其对应 MoE 模型(具有相同基础)的计算需求是相似的。
更具体地说,1.3B+MoE-128 模型的训练所需的计算操作量与 1.3B 密集模型大致相同,同时提供了更好的模型质量。此外,我们的结果表明,通过应用 MoE,我们可以以训练 1.3B 参数密集模型的成本,实现 6.7B 参数密集模型的模型质量,从而有效将训练计算量减少 5 倍。
通过利用高效的 DeepSpeed MoE 训练系统,这种计算成本的降低可以直接转化为吞吐量提升、训练时间和训练成本的降低。表 2 显示了 1.3B+MoE-128 模型与 6.7B 密集模型在 128 块 NVIDIA A100 GPU 上的训练吞吐量对比。
| 每秒训练样本数 | 吞吐量增益 / 成本降低 | |
|---|---|---|
| 6.7B 密集型 | 70 | 1 倍 |
| 1.3B+MoE-128 | 372 | 5 倍 |
表 2:MoE 模型与能够达到相同模型质量的密集模型在 128 块 A100 GPU 上的训练吞吐量对比。
MoE 用于推理
MoE 的训练成本降低并非没有代价,与密集模型相比,它需要增加总参数数量才能达到相同的模型质量。1.3B+MoE-128 的参数数量(52B)大约是 6.7B 密集模型的 8 倍。那么,这是否意味着推理速度会比密集模型慢 8 倍,因为推理通常受限于读取所有模型参数所需的时间,尤其是在小批量大小的情况下?
并非如此。请注意,在 1.3B+MoE-128 模型中,每个 token 在每个 MoE 层中都由一个唯一的专家处理,并且处理该 token 所使用的总参数数量仅为 1.3B。理论上,这甚至可以比质量相当的 6.7B 密集模型实现更快的推理速度,因为计算量和参数读取量都减少了 5 倍。然而,实际上,推理过程中批处理中的 token 数量通常大于 1。推理长序列长度或非单位批量大小时,可能需要加载所有专家,从而使加载的总参数数量比质量相当的密集模型增加 8 倍。因此,即使每个 token 使用的参数和产生的计算量与质量相当的密集模型相比很小,使用 MoE 实现良好的推理性能仍然具有挑战性。
尽管如此,我们相信可以通过使用不同形式的并行化来利用大规模内存带宽,通过在大量设备上进行扩展来加速 MoE 推理,使其在扩展推理场景中与质量相当的密集模型相媲美或更快,并为 MoE 模型在训练之外的推理方面实现成本效益创造机会。
结论与发布
我们证明了基于 MoE 的模型可以应用于 NLG 任务,与 GPT-3 和 MT-NLG 530B 等密集型自回归 transformer 模型相比,训练成本降低了 5 倍。通过基于 MoE 的低成本训练,我们希望能够让高质量的语言模型惠及更广泛的受众,即使计算资源有限也能使用。
为此,我们发布了用于训练基于 MoE 的 NLG 模型的端到端 pipeline,以及特定示例脚本和教程,以帮助您开始使用我们的 pipeline。我们期待它能为深度学习社区带来应用和创新。
致谢
这项工作是与图灵团队的 Brandon Norick、Zhun Liu、Xia Song 以及 Z-Code 团队的 Young Jin Kim、Alex Muzio、Hany Hassan Awadalla 合作完成的。我们还要感谢 Luis Vargas、Umesh Madan、Gopi Kumar、Andrey Proskurin 和 Mikhail Parakhin 的持续支持和指导。